/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 8 мин.
Вместо эпилога
Эта история произошла довольно давно, но некоторые подробности стали ясны только сейчас, отчего и настало время её рассказать.
Не будем останавливаться на описании типов параллельных реальностей, это уже давно и успешно делают многие литераторы, любители альтернативной истории, футурологи и просто поклонники подобных вещей. Перейдём сразу к делу.
А дело происходило в НИИЧАВО в тот момент, когда у Кристобаль Хозеевича Хунты не получилось навести порядок с Тройкой. Соответственно товарищ А.Привалов, выражаясь современным языком «завис» под началом товарища Выбегалло. Ноябрь выдался малоснежный, но близился новый год и т. Выбегалло пришёл к т. Привалову с поручением от Тройки: «Ввиду наступающего праздника Нового года необходимо разработать план обеспечения настроением всех жителей страны:
1) в недельный срок произвести оценку потребности нужных событий на 1000 жителей;
2) передать описание потребности из п.1 в лабораторию Хорошего настроения для реализации плана, уже доведённого до них Тройкой.
Передав поручение Тройки с резолюцией «Обеспечить январь настроением» Выбегалло, строго посмотрел на т. Привалова и сказал, что зайдёт через два дня.
Работа началась
Александр с максимально серьёзным видом кивнул. Сказал: «Немедленно займусь» и проводил уходящего т. Выбегалло взглядом. Особого беспокойства Александр не испытывал, т.к. недавно у заезжего путешественника во времени выменял на неразменный рубль notebook c Anaconda. Так что сейчас он точно знал, что Рython не только змея такая, но и полезная в хозяйстве вещь.
Немного поразмышляв о подходах, он создал данные с 1000 событий для января месяца. Малым, но приятным бонусом, было то, что 1 января выпадало на понедельник и функции обработки дат даже не понадобились. В данных он заложил два типа событий: «искренняя улыбка» и «беззаботный смех».
При подготовке к встрече Александр считал данные:
# Читаем данные о количестве событий каждого вида
# Pivot самое простое средство для визуализации данных этой задачи: подсчитать сумму по типам событий
Cnt_arr = pd.DataFrame()
Cnt_arr = F_Lst_FULL_df.pivot_table('DT_evnt', index='Date_event',dropna = False,fill_value=0, columns='Type',aggfunc='count')
# Рисуем
sns.set() # используем seaborn styles по умолчанию
Cnt_arr.plot()
plt.xlabel('Даты событий')
plt.ylabel('Количество событий')
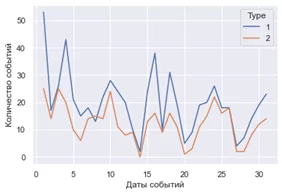
Анализ
Когда т. Выбегалло пришёл, к обещанному времени т. Привалов показал ему графическое описание данных. Александр уточнил, что улыбки — это тип=1, а смех, это тип=2 и спросил какие вопросы нужно обсудить.
«Вот ведь т. Привалов» — сказал Выбегалло, «машина вроде умная у Вас, а чего же она сразу не обозначает, что самая важная тенденция в событиях – плавный переход от праздников к рабочему ритму?».
Александр улыбнулся и тут же в течение 5 минут быстро набрал на клавиатуре:
# Рисуем график для отображения тенденций по обоим сортам событий
sns.set_style("white")
gridobj = sns.lmplot(x='Date_event', y='DT_evnt', hue='Type', data=Cnt_arr, height=7, aspect=1.6,
robust=True, palette='tab10', scatter_kws=dict(s=60, linewidths=.7, edgecolors='black'))
# Внимание на общий масштаб и выбор добавки к минимальному и максимальному значению!
# Ключевое: Наши данные в целочисленном диапазоне 0-100!
# определяем размерность по X (min, max)
Xmin=Cnt_arr['Date_event'].min()-1
Xmax=Cnt_arr['Date_event'].max()+1
# определяем размерность по Y (min, max)
Ymin=Cnt_arr['DT_evnt'].min()-1
Ymax=Cnt_arr['DT_evnt'].max()+1
# Рисуем
gridobj.set(xlim=(Xmin, Xmax), ylim=(Ymin, Ymax))
plt.title("График с линией тенденции для двух типов событий",
fontsize=20)
plt.show()
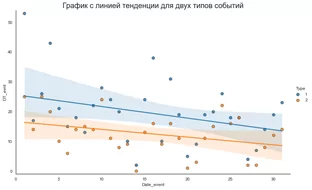
«Ну вот нужную тенденцию вижу. Так бы сразу!» — смягчившись, сказал Выбегалло и расплылся в довольной улыбке. Потом посерьёзнел и спросил: «А что это за пила такая была на первом рисунке? Отчего это она так дергается, мил человек?».
Александр был готов к этому вопросу (мысленно, только мысленно, он улыбнулся), а вслух сказал: «Это потому, что в данных есть две особенности: 1) количество событий определялось случайным образом, вроде как естественные всплески настроения; 2) субботы и воскресенья обеспечены пониженным количеством событий, т.к. это не рабочие дни.»
Александр замолчал, ожидая пока Выбегалло посмотрит на него, и закончил: «А для проверки отсутствия явных зависимостей я повёл кластерный анализ. Причём сами данные для удобства обогатил следующими временными признаками»:
# Добавленные признаки
# Сначала день месяца (отбрасываем остаток)
F_Lst_FULL_df['Date_event'] = F_Lst_FULL_df['DT_evnt']-F_Lst_FULL_df['DT_evnt']%1
# Исправляем особенность в данных 0 дату меняем на 1-ое
F_Lst_FULL_df['Date_event'] = F_Lst_FULL_df['Date_event'].replace(0.0, 1.0)
# Добавляем долю дня в течение суток от 0 до 1
F_Lst_FULL_df['PartOfDay'] = F_Lst_FULL_df['DT_evnt']%1
# Добавляем номера недели
F_Lst_FULL_df['NWeek'] = F_Lst_FULL_df['Date_event']//7%7+1
# Добавляем номер дня в неделе 1-пн
F_Lst_FULL_df['D_Week'] = 1 + (F_Lst_FULL_df['Date_event']+6)%7
На слове «кластерный» Выбегалло аж крякнул от неожиданности. Для иллюстрации «недельной» аналитики Александр запустил заранее готовый код и показал «Хитрый кругляшок», как его сразу де окрестил уже изрядно поражённый Выбегалло:
# Рисуем в двух координатах день недели и время события в доле суток количество этих событий
# КЛЮЧЕВОЕ ПРАВИЛО:
# равенство размерности массивов(серий) для трёх наборов данных - угла, радиуса, диаметра окружности
# Самый простой способ создания таких данных - pivot
vis_date = F_Lst_FULL_df.pivot_table('DT_evnt', index=['D_Week','PartOfDay'],
dropna = False,fill_value=0, aggfunc='count').reset_index()
Angle_dim = vis_date['D_Week'] # День недели
Radius_dim = vis_date['PartOfDay'] # Часть суток (0-1) в 24 часах
# Построение
# Угол отображения данных в зависимости от дня недели
theta = 2 * np.pi * Angle_dim/7 # Приводим день недели к двум Pi (3.14159265...)
# Площадь круга для отображения зависит от количества событий для этого дня недели
area = vis_date['DT_evnt'] #
colors = theta # Цвета зависят от дня недели (1-пн,2-вт,3-ср...7-вс)
fig = plt.figure()
# На всякий случай, если так ещё не рисовали:
# Примечание: параметр, 111 - это первая строка, первый столбец и первая (единственная здесь) ячейка на сетке Figure.
ax = fig.add_subplot(111, projection='polar')
# Сделаем свои метки для круговой диаграммы, то что будем писать по кругу (вместо градусов)
# К стати, углы увеличиваются против часовой стрелки!
xtks = pd.DataFrame()
xtks['val']=(2 * np.pi * Angle_dim/7).unique() # Сами значения угла
xtks['mrk']=['Пн','Вт','Ср','Чт','Пт','Сб','Вс'] # Метки для его обозначения
plt.xticks(xtks['val'].tolist(),xtks['mrk'].tolist())
c = ax.scatter(theta, Radius_dim, c=colors, s=area, cmap='hsv', alpha=0.75)
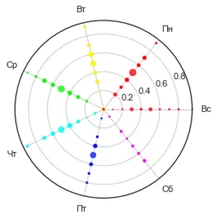
«С субботами и воскресеньями – хвалю, надо экономить волшебные средства» — выпалил Выбегалло, он был явно доволен. «Вот только насчёт кластерных анализов надо обмозговать. Надёжна ли вещь?» — осторожно подбирая слова и задумчиво гладя на Привалова, сказал Выбегалло. «Никаких сомнений» — сказал Александр и перешёл к показу.
Сначала нормализуем данные
Александр показал небольшой кусочек кода, который использовал для нормализации:
# Нормализация (все признаки в диапазон 0-1)
d = preprocessing.normalize(F_Lst_FULL_df,axis=0)
scaled_df = pd.DataFrame(d,columns = ['DT_evnt', 'Type', 'Date_event', 'PartOfDay','NWeek','D_Week'])
del d
Готовим модель кластеризации (k-Menas)
Александр перешёл к коду модели и уточнил: «N_Clstr меняем для проверки нескольких гипотез.
N_Clstr=2 события делятся на кластеры по признаку тип события (улыбка/смех);
N_Clstr=7 события делятся на кластеры по признаку день недели для события;
N_Clstr=31 события делятся на кластеры по признаку день в месяце;
N_Clstr=14 делятся на кластеры по двум признакам день недели и тип события.»
# Описываем модель
N_Clstr=14
model = KMeans(n_clusters=N_Clstr)
# Проводим моделирование
model.fit(scaled_df)
# Предсказание на всем наборе данных
all_predictions = model.predict(scaled_df)
Для данных посчитанных с помощью модели понижаем размерность (что бы нарисовать кластеры в двумерном пространстве)
Александр «напомнил», что кластеры определены в пространстве размерностью равной количеству признаков. Посмотреть на такое разбиение весьма проблематично. «Поэтому используем TSNE инструмент для снижения размерности нашей картинки кластеров до 2D.
# Определяем модель и скорость обучения
model = TSNE()
# Обучаем модель
transformed = model.fit_transform(scaled_df)
# Представляем результат в двумерных координатах
x_axis = transformed[:, 0]
y_axis = transformed[:, 1]
Рисуем для каждой гипотезы набор картинок, в качестве цвета задаём признаки, содержащие сравнительно малое количество вариантов значений
plt.title('K-Means кластеризация на кол-во кластеров: '+str(N_Clstr)+'. Цвет по типам событий')
plt.scatter(x_axis, y_axis, c=scaled_df['Type'])
plt.show()
# Далее так же для:
# Цвет по дням недели D_Week
# Цвет по доле начала события в течение суток PartOfDay
# Цвет по дате события Date_event
# Цвет по номеру недели для события NWeek
Анализируем кластеры
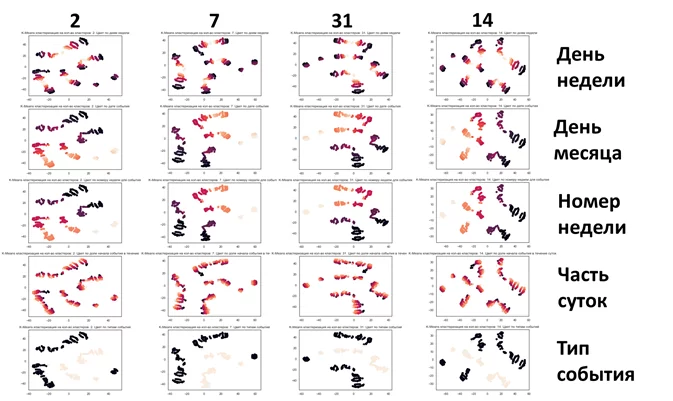
Александр, окинул взглядом поле из картинок и выдержал паузу, после чего начал: «Вот, товарищ Выбегалло, как сами видите наглядная демонстрация, что чёткое распределение на ярко выраженные кластеры мы не наблюдаем только отчасти, для типов события есть разбиение на два (нижняя строчка картинок), в какой-то мере это же мы видели на первом графике (данные события одного типа не совпадают с данными события другого типа (есть только пара точек пересечений).
По остальным картинкам мы наблюдаем:
1) не односвязный характер цветовых массивов,
2) наложение разных цветов друг на друга.
Следовательно, как такового «понимания» управления настроением не ожидается. Всё веселье пройдёт по плану и строго по плану перейдёт в рабочий ритм февраля, абсолютно естественным образом!».
Выбегалло был очень доволен, широко улыбнувшись, он спросил: «Отчёт уже напечатали?». «Конечно, все эти данные вот». Александр достал папку из верхнего ящика.
«Вы молодец! Обязательно отмечу Вас при подведении итогов года!» — сказал Выбегалло и решительно отправился в секретариат Тройки.