/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Сравнение текстов
Допустим у нас есть три текста: два из них про собачек и один про кошечек. Как их сравнить между собой?

Мы можем посчитать сколько каждое слово встречается в тексте, в нашем случае считать будем кошечек и собачек, и если в тексте собачек встречается больше, чем кошечек, то можно сделать вывод, что они (тексты) про одно и то же.
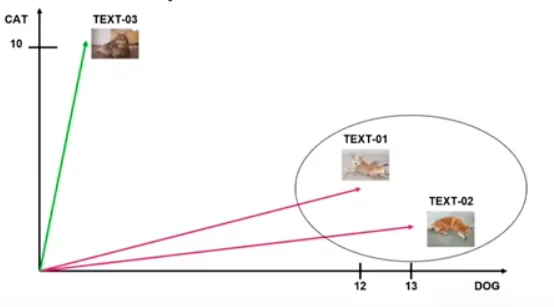
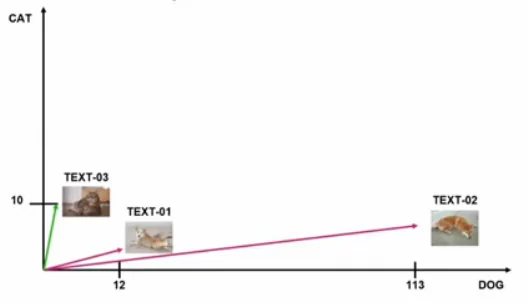
На самом деле, не всегда так. Представим ситуацию, что есть очень длинный текст про собачек и в нем слов встречается больше. К счастью, из такой ситуации можно выйти, сравнив косинусные расстояния.
Такой подход, когда мы текст делим на слова и считаем каждое слово называется bag-of-words или мешок слов. На python это делается довольно просто:

Проблема подхода bag-of-words в том, что, например, «Кошку» и «Кошка» это два разных слова и при подсчете будут засчитаны двум разным словам. Если внимательнее присмотреться, то мы заметим, что эти слова различаются только на одну букву. А что, если мы вырежем все окончания и суффиксы? На самом деле такой процесс называется Стемминг. Этот подход работает довольно быстро и послепредобработки bag-of-words будет засчитывать такие слова, как «Кошку» и «Кошка» за одно.
Лемматизация
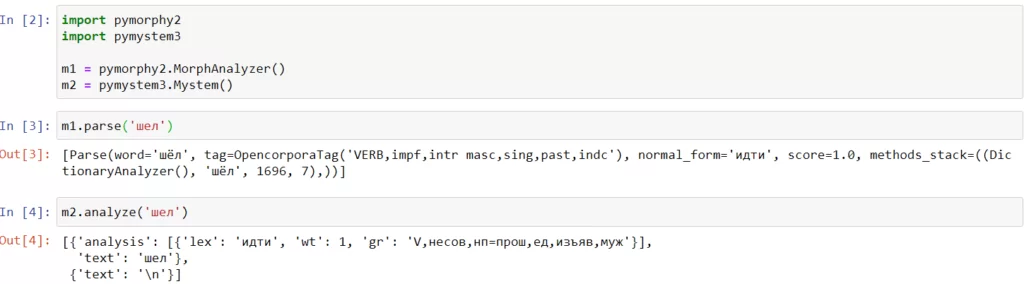
Рассмотренный выше подход так же не лишен недостатков. Представим ситуацию, когда у нас есть два слова, но удаление суффиксов и окончаний не приведет к одному и тому же слову. Например, слова «шел» и «идти». Тут нам на помощь приходят другие инструменты – морфологические анализаторы. В python два самых популярных: pymorphy и pymystem. На вход подаем слово, а на выходе получаем его в нормализованном виде. Такой подход называется Лемматизация.
Орфография
И снова поднимаем вопрос предобработки данных. Иногда бывает так, что в тексте могут встретится орфографические ошибки и было бы не плохо о них знать, а в идеале еще и исправить их.

Расстояние Левенштейна
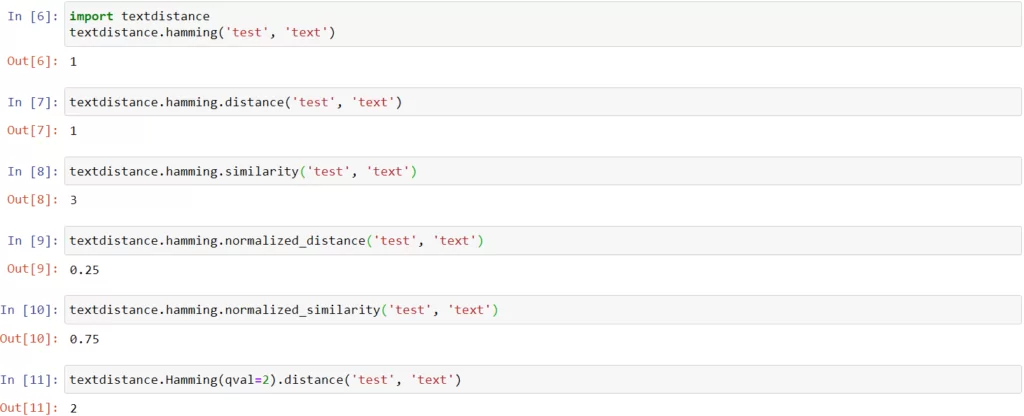
Вычисление метрики Расстояния Левенштейна помогает при решении задач, в которых необходимо ответить насколько слова или тексты похожи друг на друга. Как это работает? У нас есть два слова и если они одинаковы, то метрика равно нулю, а если для достижения «одинаковости» требуется произвести, к примеру, перестановку букв, то мы штрафуем и прибавляем единицу. Таким образом значение метрики увеличивается, и чем больше значение мы получаем, тем меньшей степенью похожести обладают наши слова.
Однако, не во всех случаях Расстояние Левенштейна одинаково эффективно. Например, если мы посчитаем метрику у слов «Светильник» — «Лампа» — «Кипятильник», то скорее всего окажется, что «Светильник» больше похож на «Кипятильник», чем на «Лампа».
Word2Vec
Вопрос со светильником, лампой и кипятильником остается открытым. Преодолеть данную проблему можно проанализировав контекст употребления слов, и в этом нам поможет инструмент Word2Vec. Как он работает? Он берет различные контексты и если слова встречаются в одинаковых контекстах, то считается что они похожи. Другими словами, каждому слову представлен некоторый вектор и если слова близко, то они синонимы. Обучить Word2Vec можно в несколько строчек:
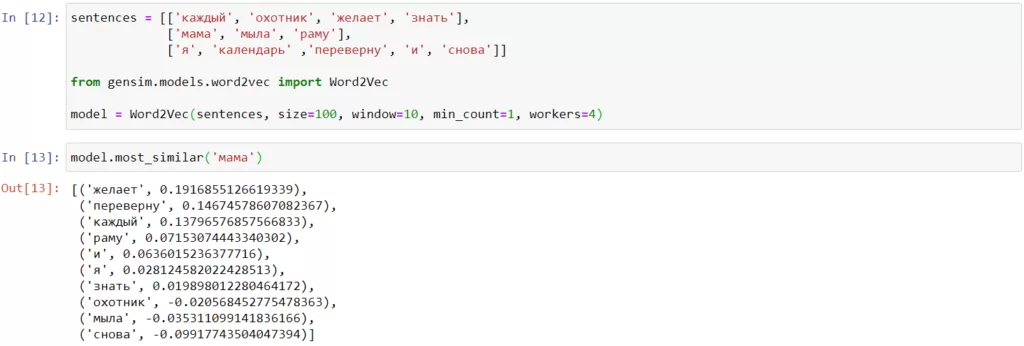
На вход подается массив из массивов слов, т.е. предложения для обучения еще делим на слова. На деле для обучения предложений должно быть, естественно, побольше. Имеет смысл при обучении использовать от 10 тыс. предложений.
Тематическое моделирование
Представим, что у нас есть набор книг и нам нужно поделить их по жанрам, например книги про бизнес, книги про IT, экономику и т.д. Здесь на помощь нам приходит тематическое моделирование. Как это работает? Каждому тексту присваивается метка и благодаря этой метке он (инструмент) относит текст к одной из «кучек». Далее мы садимся разбирать эти «кучки» и если «кучка» состоит из миллиона текстов, а десять из них про кулинарные рецепты, то следовательно, мы делаем вывод, что все тексты в этой кучке являются кулинарными рецептами.
Кроме того, инструмент pyLDAvis обладает мощной визуализацией, что сейчас очень актуально.
Синтаксический анализ
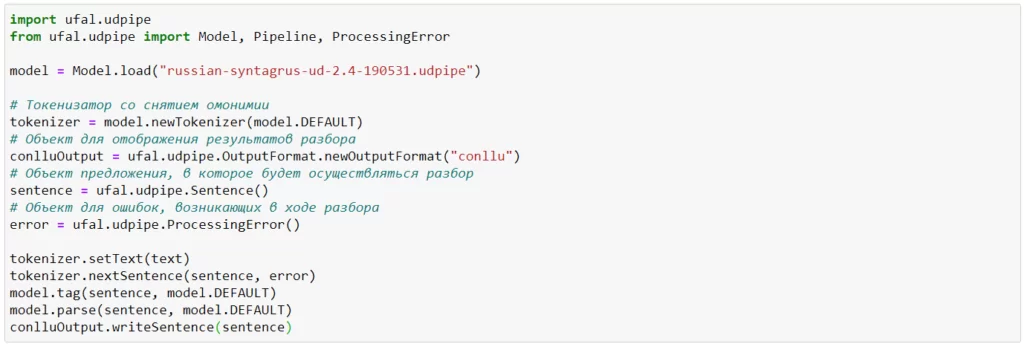
Методы синтаксического анализа применяются, когда нужно удалить часть предложения. Например, если из текста нужно сделать небольшую аннотацию. Для этого разбираем предложение по составу и убираем ненужные слова. С такой задачей легко справится udpipe.
И посмотрим, как работает этот инструмент на примере мема, который ходит среди лингвистов: «Глокая куздра штеко будланула бокра и курдячит бокрёнка». Это предложение, в котором у нормальных слов корни заменили на набор звуков, но при этом все еще понятно кто и кого «будланул».
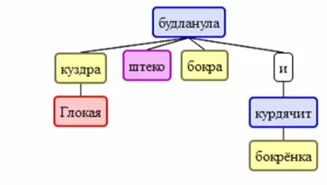
Как мы видим, udpipe справился и построил граф зависимостей даже на таком, очевидно, бредовом предложении.
Несмотря на то, что все инструменты рассматривались на простых примерах, у NLP широкий спектр решаемых задач: классификация обращений сотрудников, оценка отзывов клиентов, анализ сообщений из чат-бота. Таким образом в наших руках появилось еще несколько инструментов.