/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Естественно, никакого анализа процесса не может быть без данных. Чтобы разобраться в том, как робот выполняет свою задачу нам необходимо знать последовательность его действий. Для этого нам необходимы логи (журнал действий).
Самым удобным способом для анализа действий роботов является Process Mining. На данный момент существует множество инструментов process vizualisation и process discovery. Но зачастую функционала этих инструментов не хватает для качественного и всестороннего анализа процесса. Для исследования приходится писать собственные функции на языке python.
В этой статье хотим рассказать, как написать функцию, которая поможет выявить аномалии во времени – это может стать одним из шагов поиска отклонений в процессе с использованием инструментов Process Mining. Целью является поиск временных аномалий во времени переходов от одного события к другому, т.к. визуализация параметра “performance” в существующих PM инструментах позволяет только показать среднее или медианное время прохождения шага.
У нас есть логи процесса, которые содержат 3 признака: уникальный идентификатор (id_column), время совершения события (dt_column) и наименование события (activity_column). Этих данных достаточно, для анализа графа процесса и переходов по стадиям. Начинаем писать алгоритм с использованием python, нам понадобится импортировать только одну библиотеку pandas. Сначала отсортируем датафрейм по идентификатору и времени, затем создаем 2 новых столбца со временем окончания действия и наименованием следующей активности, таким образом формируя подробную матрицу переходов.
anomaly_time= pd.DataFrame()
anomaly_time[['id_column','time_start','activity_start']] = df[‘id_column’,’dt_column’, ‘activity_column’]
anomaly_time['activity_end'] = df.groupby(‘id_column’)[‘activity_column’].shift(-1)
anomaly_time['time_end'] = df.groupby(‘id_column’)[‘dt_column’].shift(-1)
Далее нам нужно отсечь те действия, которые содержат лишь один шаг, т.к. они не имеют переходов и в подсчет не войдут.
anomaly_time['count'] = self.pandas_df.groupby(self.id_column)[self.dt_column].transform('count')
anomaly_time = anomaly_time[anomaly_time['count']!=1]
Чтобы избежать ошибок, связанных с типом данных на последнем шаге активности, мы должны заполнить пропуски в столбце ‘activity_end’, ведь используя при его создании shift(-1) мы заполнили каждое последнее значение для активности ‘NAN’. Теперь заполним их таким образом, чтобы в них было значение, равное ‘time_start’.
anomaly_time['activity_end'].fillna('end', inplace=True)
anomaly_time.loc[anomaly_time['activity_end']=='end','time_end']=anomaly_time.loc[anomaly_time['activity_end']=='end','time_start']
После этого мы уже можем считать время выполнения каждого шага и записать разницу во времени в столбец ‘delta’.
anomaly_time['delta']=(pd.to_datetime(anomaly_time['time_end'])-pd.to_datetime(anomaly_time['time_start'])).astype('timedelta64[s]')Для поиска аномалий в полученном столбце, его необходимо для начала нормализовать в рамках каждого перехода. Нормализацию данных будем осуществлять по формуле X_norm=(X-X_min)/(X_max-X_min), используя минимум и максимум дельты из уникальных переходов. Чтобы получить уникальные переходы, нужно закодировать столбцы ‘activity_start’ и ‘activity_end’ и вывести их существующие сочетания как в представленном ниже коде.
labels_start,uniques=pd.factorize(anomaly_time['activity_start'])
anomaly_time['activity_start_code']=labels_start
labels_end,uniques=pd.factorize(anomaly_time['activity_end'])
anomaly_time['activity_end_code']=labels_end
anomaly_time['start_end']=anomaly_time['activity_start_code'].astype(str)+anomaly_time['activity_end_code'].astype(str)
anomaly_time=anomaly_time[anomaly_time['activity_end']!='end']
anomaly_time['max_time'] = anomaly_time.groupby('start_end')['delta'].transform('max')
anomaly_time['min_time'] = anomaly_time.groupby('start_end')['delta'].transform('min')
anomaly_time['delta_norm']=(anomaly_time['delta']-anomaly_time['min_time'])/(anomaly_time['max_time']-anomaly_time['min_time'])
Теперь, когда у нас есть столбец с нормализованной длительностью переходов, нам необходимо проставить метки принадлежности к аномальным случаям. Все рассматриваемые задачи разные, поэтому порог отсечения аномалий нужно подбирать индивидуально, поэтому создадим переменную trash, для возможности выбора хвостов распределения с обеих сторон.
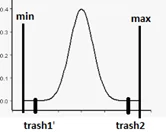
anomaly_time['anomaly_lable']=0
anomaly_time.loc[(anomaly_time['delta_norm']<=trash)|(anomaly_time['delta_norm']>=trash2),'anomaly_lable']=1
В итоге проделанной работы у нас получился DataFrame, содержащий признак ‘anomaly_lable’, который заполнен 0/1 (0 – признак нормального наблюдения, 1 – признак аномалии). Анализ данной информации позволит рассмотреть подробно случаи слишком быстрого или слишком длительного случая перехода для более полного понимания процесса.