/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 12 мин.
В данной статье будет рассмотрена графовая система управления базами данных в Neo4j, а именно:
- Установка и настройка Neo4j;
- Создание базы данных с использованием Python;
- Базовый синтаксисом языка Cypher для создания запросов;
- Кейс использования данной СУБД.
Что такое Neo4j или немного теории:
Neo4j — это графовая система управления базами данных с открытым исходным кодом, реализованная на Java. Она является ведущей графовой СУБД в мире. Аналогами Neo4j являются Oracle NoSQL Database, HypherGraphDB, GraphBase, InfiniteGraph и AllegroGraph.
Всем известно, что такое граф, и из чего он состоит. Так вот, графовые базы данных представляет собой набор объектов, где объекты связаны между собой, подобно как в графе вершины (узлы), связанные через ребра (отношения).

Почему графы и где они используются?
Графы – это удобная и наиболее понятная визуальная система описания данных. Обычно они используются в геоинформационных системах, логистике, социальных сетях и т.п.
От теории к практике:
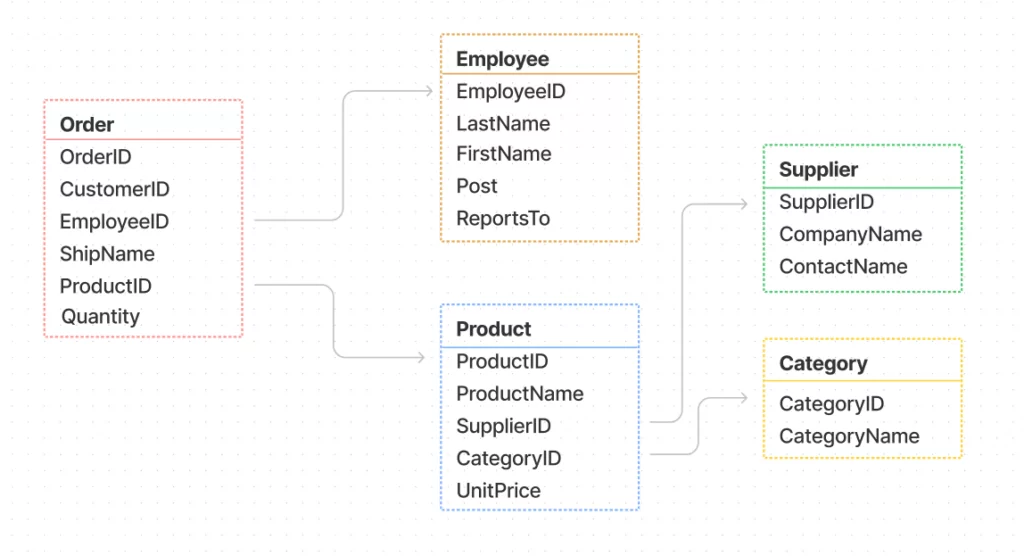
Для того, чтобы работать с любой базой данных, необходимы данные, как бы тавтологично это не звучало. Для примера, будем использовать уже готовые таблицы (формат CSV) с данными, которые содержат информацию о работе интернет-магазина. Все необходимые данные находятся тут.
Ход работы:
- Скачиваем среду разработки Neo4j Desktop с официального сайта. Больше информации можно прочесть в гайде для разработчиков
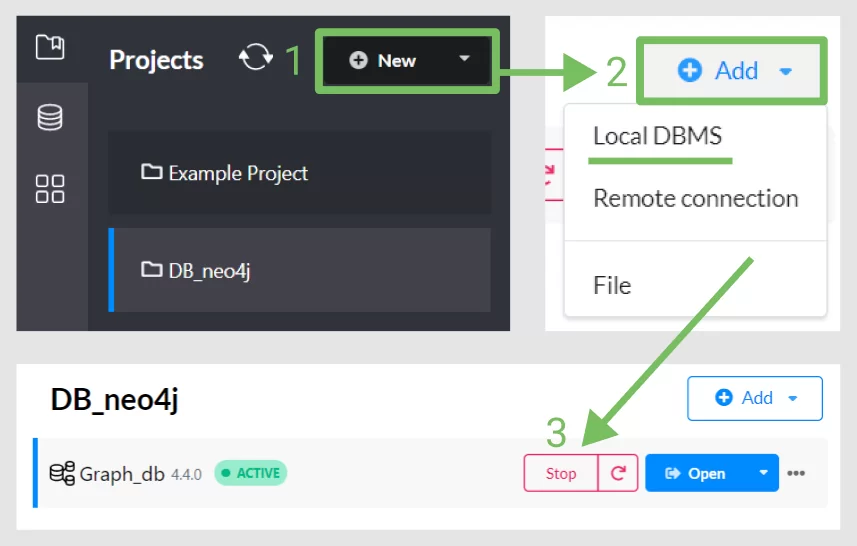
- Создаем базу данных
Кликаем на «New» чтобы создать новый проект. После нажимаем на Add -> local DBMS и уже в самом конце называем её (больше информации тут). После всех проделанных действий нам необходимо запустить её и открыть Neo4j Browser (большая синяя кнопка с надписью «Open»).
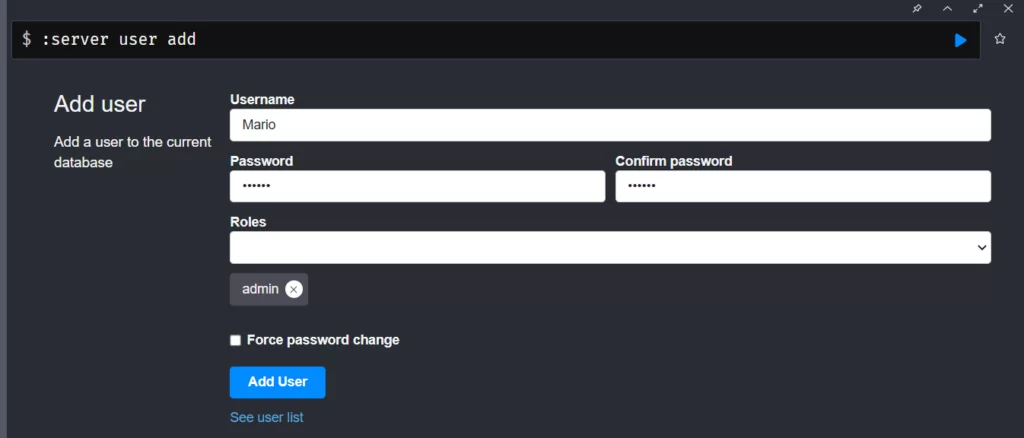
3. Добавляем администратора
В Neo4j browser необходимо ввести команду server user add, для того, чтобы добавить пользователя и после заполнить все поля. В поле roles нужно выбрать admin.
4. Подключимся к СУБД. Python + Neo4j
Для того, чтобы подключится к базе данных, необходимо установить библиотеку neo4j.
pip install neo4jПосле импортируем GraphDatabase для подключения к СУБД.
from neo4j import GraphDatabaseДалее представлен код для подключения
class Neo4jConnection:
def __init__(self, uri, user, password):
self.driver = GraphDatabase.driver(uri, auth=(user, password))
def close(self):
if self.driver is not None:
self.driver.close()
# Метод, который передает запрос в БД
def query(self, query, db=None):
assert self.driver is not None, "Driver not initialized!"
session = None
response = None
try:
session = self.driver.session(database=db) if db is not None else self.driver.session()
response = list(session.run(query))
except Exception as e:
print("Query failed:", e)
finally:
if session is not None:
session.close()
return response
Запросы в Neo4j пишутся на языке Cypher. Он интуитивно понятный для освоения. Документацию по этому языку можно прочитать перейдя по ссылке.
Итак, подключаемся к СУБД. Создаем объект connection и передаем имя пользователя и пароль (который создавали при регистрации пользователя). Далее передаем запрос на создание самой базы данных «graphDb» — это название БД.
conn = Neo4jConnection(uri="bolt://localhost:7687", user="Mario", password="123123")
conn.query("CREATE OR REPLACE DATABASE graphDb")
Далее необходимо загрузить все данные из таблицы в БД (загружаем таблицу Product). Для этого пишем запрос:
query_string = '''
LOAD CSV WITH HEADERS FROM
'https://raw.githubusercontent.com/Mario-cartoon/bd/main/Product.csv'
AS line FIELDTERMINATOR ','
MERGE (product:Product {productID: line.ProductID})
ON CREATE SET product.productName = line.ProductName, product.UnitPrice = toFloat(line.UnitPrice);
'''
conn.query(query_string, db='graphDb')
Как работает данный запрос? Он загружает CSV-файл из github, после построчно считывает данные, разделяя их по запятой (FIELDTERMINATOR ‘,’). Далее связываем узлы (объекты) и создаем свойства объекта
product.productName = line.ProductNameПосле запускаем код и переходим в Neo4j browser. В окне «Node Labels» кликаем по появившейся кнопке «Product».
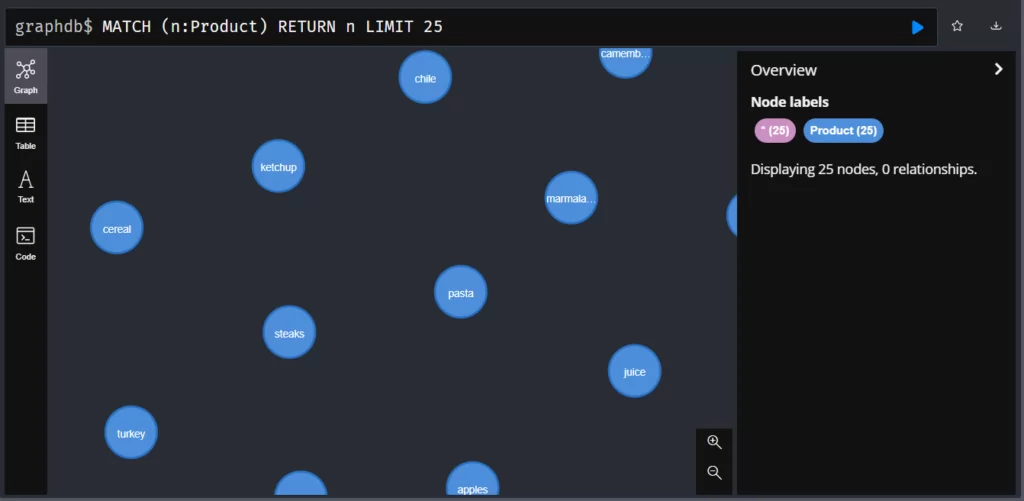
Поздравляю! Вывели узлы Product. Если нажать на один узел, то в окне справа появятся все свойства (productName, productID, UnitPrice), которые мы прописывали в запросе.
Далее создаем запросы на загрузку остальных данных из других таблиц. Код можно посмотреть в GitHub. В итоге в левом окне должно быть 5 узлов:
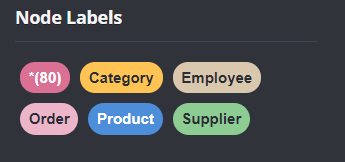
Можно вывести все узлы в одно окно. Для этого необходимо прописать следующий запрос:
MATCH (n) RETURN n 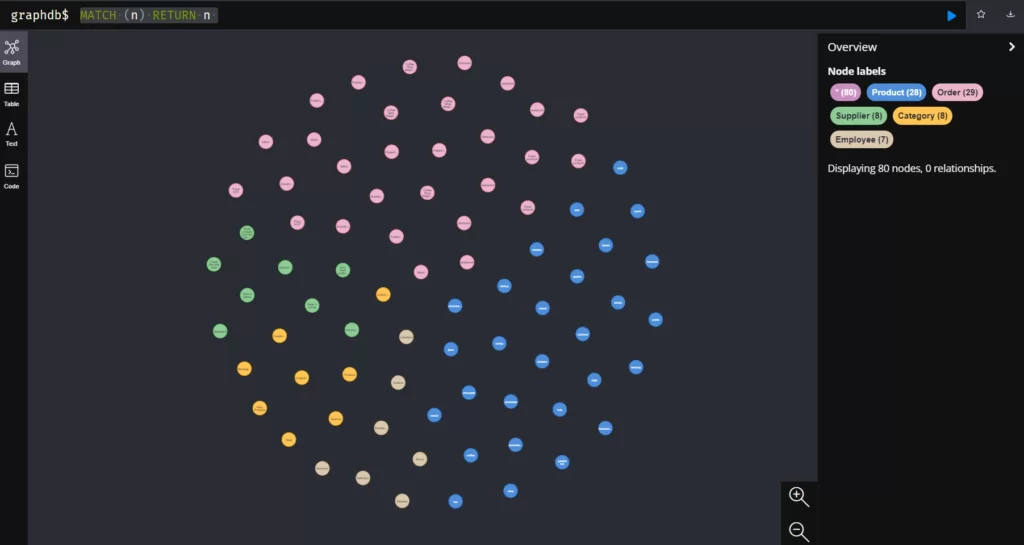
Пока наши узлы (объекты) не имеют отношений с другими узлами.
5. Создаём запросы на создание отношений
Допустим, нам нужно посмотреть какие заказы выполнили сотрудники. Для этого нужно связать узлы (объекты) Order и Employee. Создаем следующий запрос:
query_string ='''
LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/Mario-cartoon/bd/main/Order.csv' AS line
MATCH (order:Order {orderID: line.OrderID})
MATCH (employee:Employee {employeeID: line.EmployeeID})
CREATE (employee)-[:SOLD]->(order);
'''
conn.query(query_string, db='graphDb')
MATCH – это основной способ получения данных в текущем наборе привязок. С помощью CREATE создаем саму связь, синтаксис напоминает строение графа, в «[]» прописываем название связи. Более наглядно это можно продемонстрировать следующим образом:
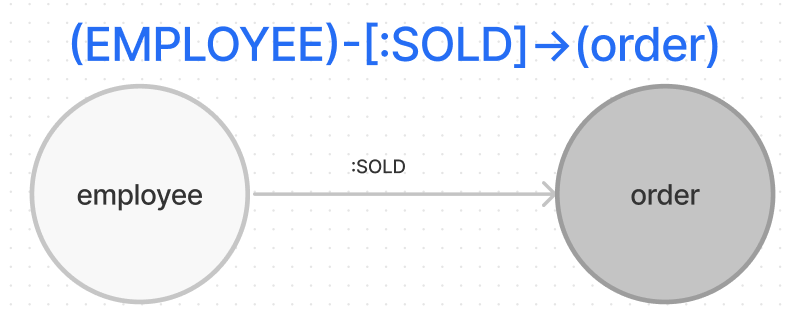
Результат:
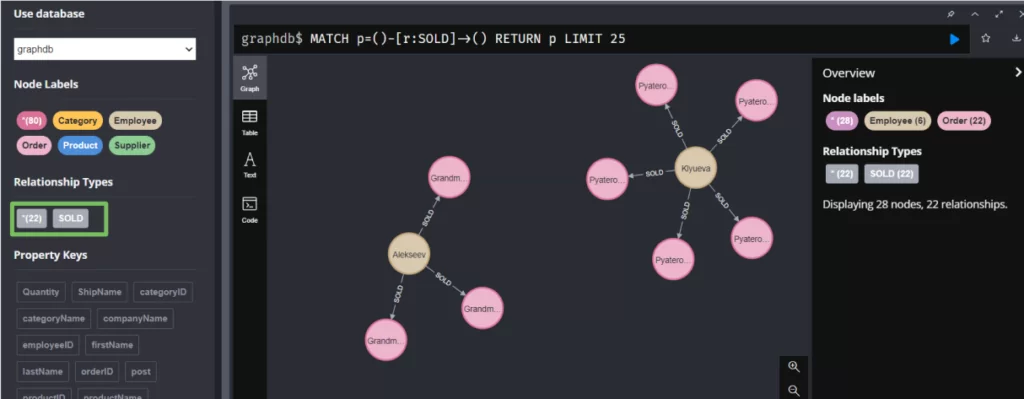
Данный запрос создаст связь, которая отобразиться в левом окне. Эта связь показывает отношение между сотрудником и заказами, который выполнил сотрудник. Например, Aleekseev -> SOLD-> Grandma’s Bakery, означает, что сотрудник Алексеев продал что-то Grandma’s Bakery (это что-то мы узнаем чуть позже).
Чтобы узнать какие данные хранятся в узле, достаточно просто на него нажать и в правом окне появится информация об объекте. Важно отметить, что здесь появляется информация, а именно свойства, которые прописывали в запросе.
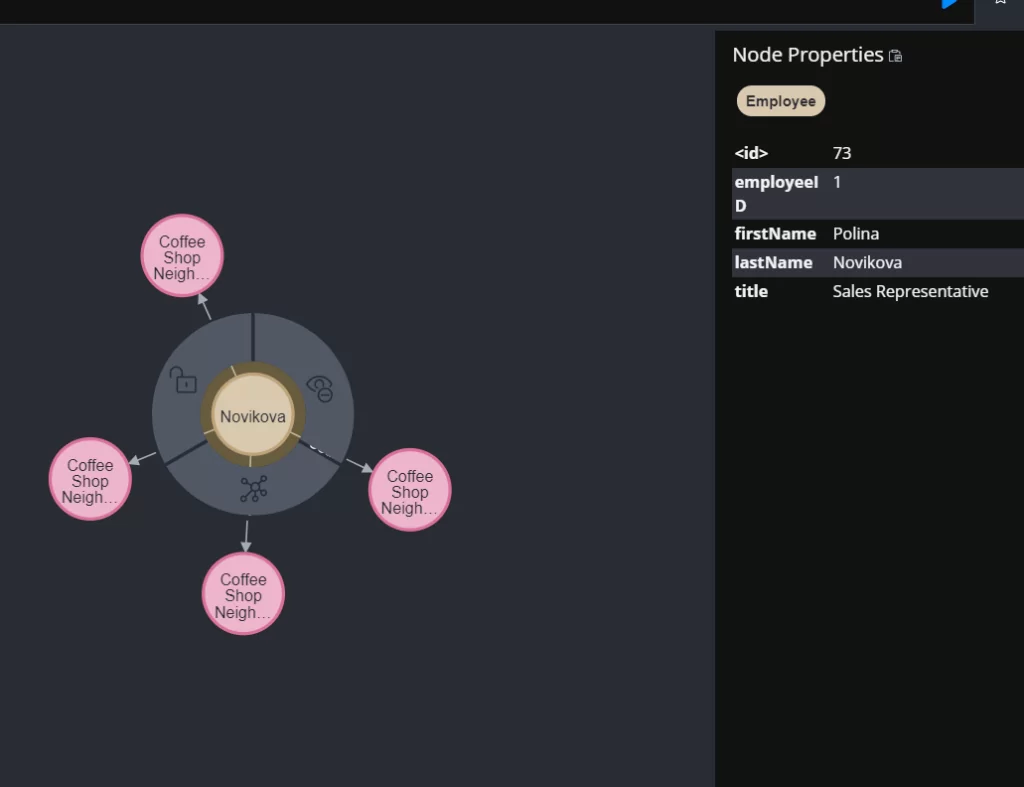
Теперь нам необходимо узнать, какой именно продукт приобрели в заказе. Для этого пишем следующий запрос:
query_string = '''
LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/Mario-cartoon/bd/main/Order.csv' AS line
MATCH (order:Order {orderID: line.OrderID})
MATCH (product:Product {productID: line.ProductID})
MERGE (order)-[op:PURCHASED]->(product)
ON CREATE SET op.quantity = toFloat(line.Quantity);
'''
conn.query(query_string, db='graphDb')
Результат:
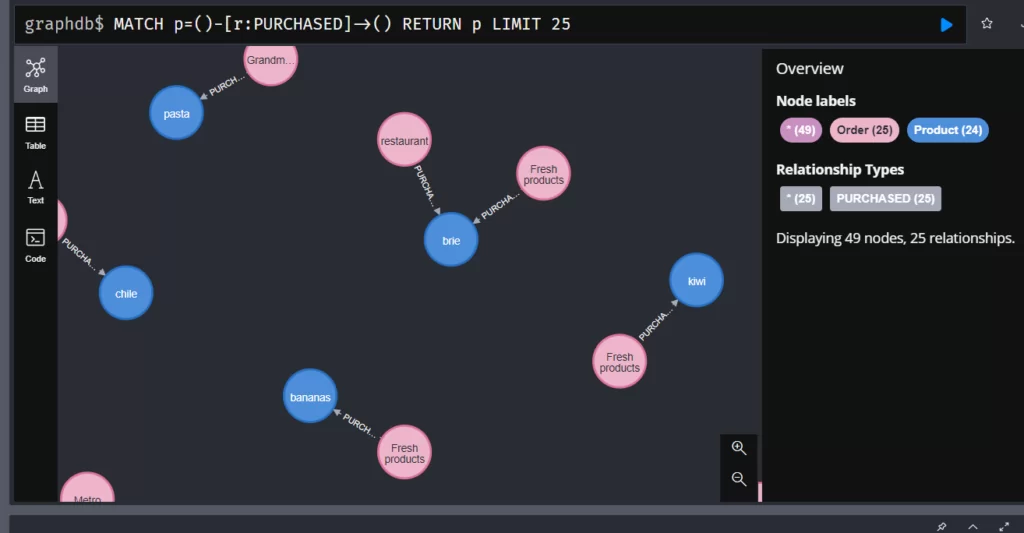
Итак, у нас есть связи сотрудника с заказом и с проданным в заказе продуктом. Теперь создадим связь между продуктом и поставщиком, а также свяжем его с категорией товара. Для этого выполните два запроса:
query_string = '''
LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/Mario-cartoon/bd/main/Product.csv
' AS line
MATCH (product:Product {productID: line.ProductID})
MATCH (supplier:Supplier {supplierID: line.SupplierID})
MERGE (supplier)-[:SUPPLIES]->(product);
'''
conn.query(query_string, db='graphDb'
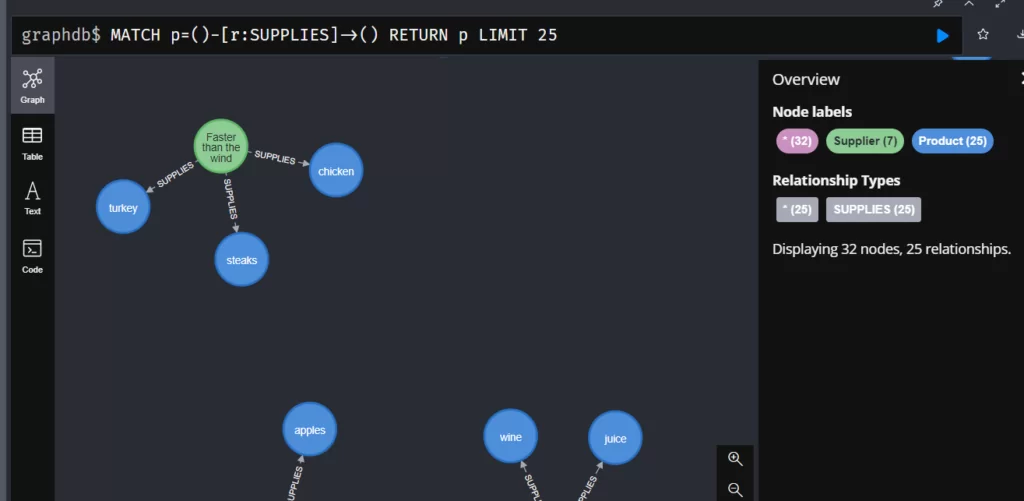
query_string = '''
LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/Mario-cartoon/bd/main/Product.csv' AS line
MATCH (product:Product {productID: line.ProductID})
MATCH (category:Category {categoryID: line.CategoryID})
MERGE (product)-[:IS_CATEGORY]->(category);
'''
conn.query(query_string, db='graphDb')
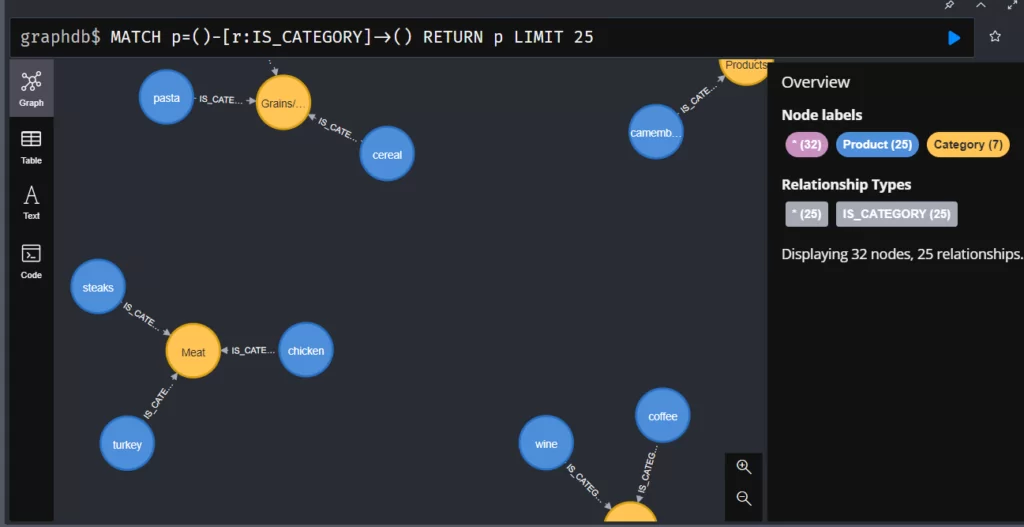
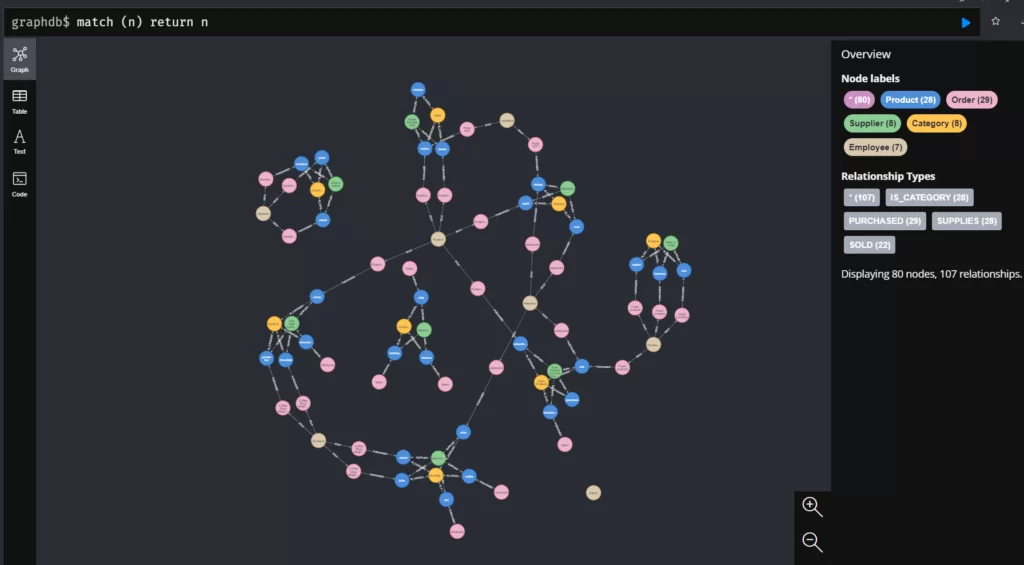
Все узлы имеют отношения. Теперь можно увидеть, как каждый объект связан друг с другом. Для этого выведите все узлы.
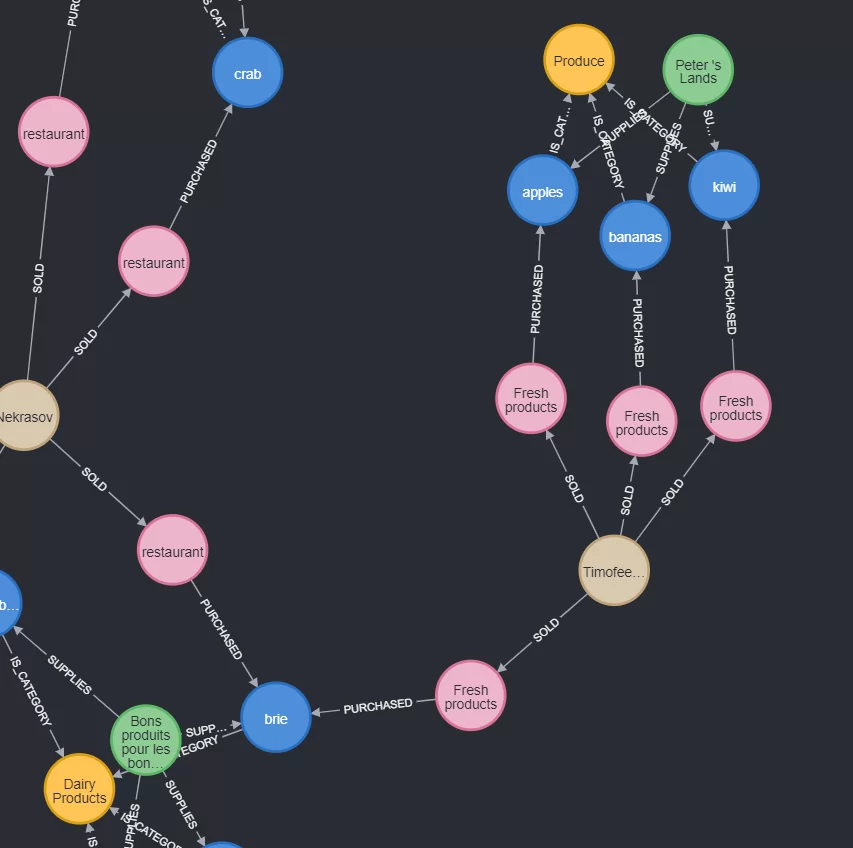
Давайте проанализируем сотрудника Timofeeva. Из графа видно, какие именно товары она продала «Fresh product», и кто был поставщиком данных товаров.
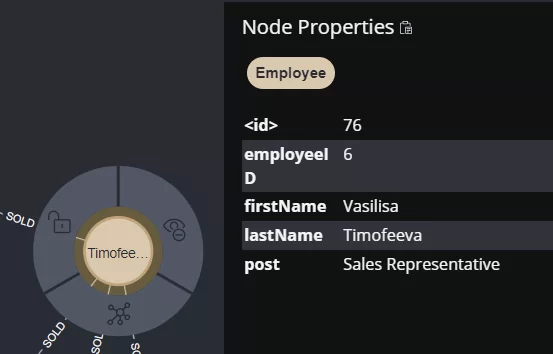
Также помним, что это все-таки база данных, и здесь можно узнать имя, фамилию и должность сотрудника — кликнув по объекту.
6. Создаём запросы для поиска конкретной информации
До этого все запросы писались через Python, но их можно создавать в самой Neo4j browser (в строке сверху).

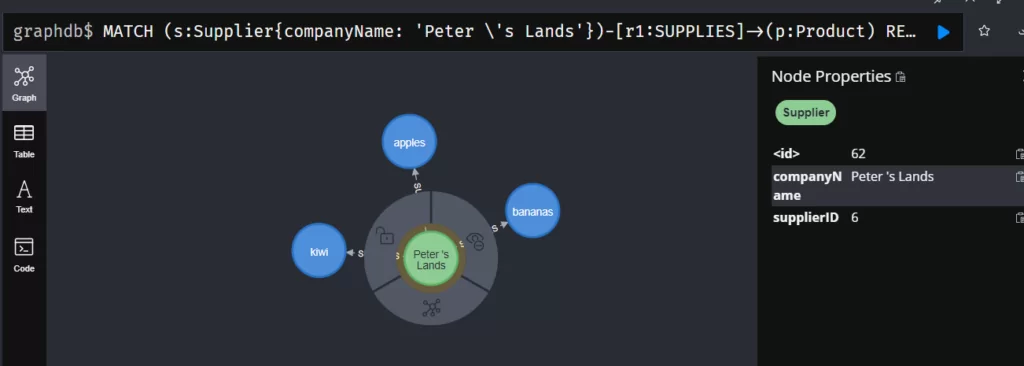
Допустим, нужно найти конкретного поставщика (например, Peter ‘s Lands), и какие продукты он поставляет. Пишем запрос:
MATCH (s:Supplier{companyName: 'Peter \'s Lands'})-[r1:SUPPLIES]->(p:Product)
RETURN s, r1, p;
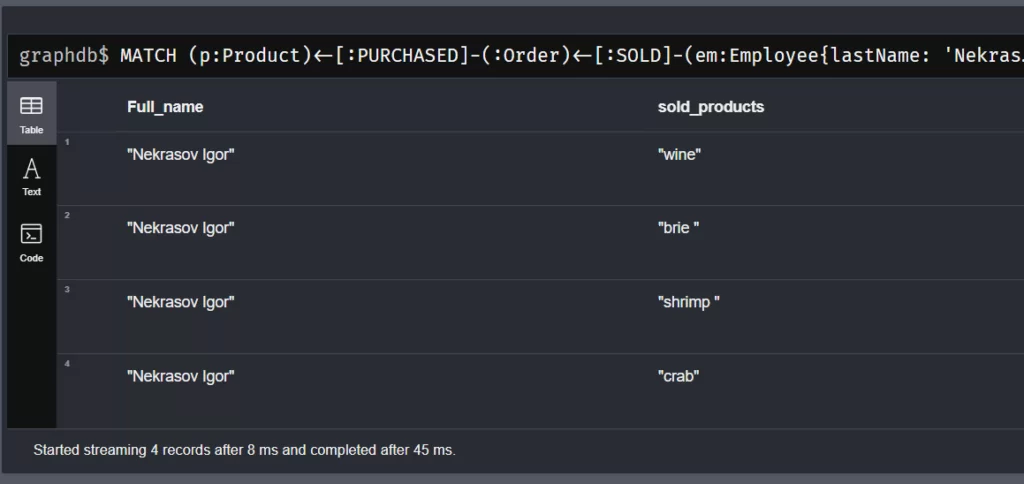
Необязательно всегда выводить нужную информацию в графах, можно и в таблице. Например, выведем информацию о том какие продукты продал сотрудник Nekrasov.
MATCH (p:Product)<-[:PURCHASED]-(:Order)<-[:SOLD]-(em:Employee{lastName: 'Nekrasov'})
RETURN em.lastName + ' '+em.firstName as Full_name, p.productName as sold_products
Результатом этого запроса будет:
Разница в том, какие данные возвращаем. Если это свойства объекта, то результатом выполнения запроса будет таблица.
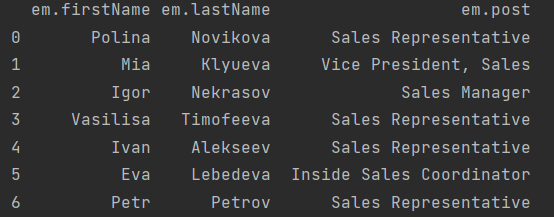
Также мы можем выгрузить данные из БД. Для этого импортируем pandas.
query_string = '''
MATCH (em:Employee)
RETURN em.firstName, em.lastName, em.post
'''
dtf_data = DataFrame([dict(_) for _ in conn.query(query_string, db='graphDb')])
print(dtf_data)
Результат:
Вы можете создавать любые запросы, и для этого в документации есть очень хорошая карта со всем синтаксисом Cypher Refcard.
После того, как рассмотрели базовые вопросы, касаемые Neo4j, нужно разобраться с вопросом, где же все-таки применяются графовые базы данных в реальных проектах? Один из таких примеров — это рекомендации по предложению продукта (товара). Мы же рассмотрим пример «Рекомендация статей для читателей» с использование Neo4j.
Пример «Рекомендация статей для читателей»
Суть нашей системы рекомендаций статей следующая: необходимо предлагать нашим читателям альтернативную статью. Например, если читатель проявляет интерес к определенной категории статей, можно создать рекомендацию, содержащую альтернативные статьи.
Чтобы показать, как это работает, давайте создадим модель данных:
- Создаем модель данных:
Наша система рекомендаций будет содержать следующие объекты с атрибутами:
- articles – title,
- category_articles – title,
- reader – name, email, nickname,
- RecommendationArticleToReader – nickname
Отношения будут следующие:

На этом у нас закончилось моделирование сущностей.
Также стоит обратить внимание, что в Neo4j нет необходимости моделировать двунаправленные отношения, например, статья находится в категории, а категория имеет множество статей. Графические базы данных позволяют отслеживать ребра в обоих направлениях.
Кстати одним из преимуществ графических баз данных от реляционных в том, что мы можем добавлять, изменять и удалять сущности (узлы) и связи (ребра), не беспокоясь о внешних ключах.
2. Работаем в Neo4J:
Заполняем нашу БД в соответствии с моделью, которую мы определили выше. Запросы будем писать в Neo4j Browser.
Загружаем данные в формате csv c github:
# LOAD CATEGORY
query_string = '''
LOAD CSV WITH HEADERS FROM
'https://raw.githubusercontent.com/Mario-cartoon/ArticleBD/main/Category.csv'
AS line FIELDTERMINATOR ','
MERGE (category:Category {categoryID: line.title})
ON CREATE SET category.title = line.title;
'''
conn.query(query_string, db='graphDb')
# LOAD ARTICLES
query_string = '''
LOAD CSV WITH HEADERS FROM
'https://raw.githubusercontent.com/Mario-cartoon/ArticleBD/main/Articles.csv'
AS line FIELDTERMINATOR ','
MERGE (article:Article {articleID: line.title})
'''
conn.query(query_string, db='graphDb')
# LOAD READER
query_string = '''
LOAD CSV WITH HEADERS FROM
'https://raw.githubusercontent.com/Mario-cartoon/ArticleBD/main/Reader.csv'
AS line FIELDTERMINATOR ','
MERGE (reader:Reader {readerID: line.name})
ON CREATE SET reader.nickname = line.nickname,reader.email = line.email;
'''
conn.query(query_string, db='graphDb')
Далее создаем отношения article-[:IS_IN]-> category и reader-[:READ]->article:
# LOAD CATEGORY_ARTICLES
query_string ='''
LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/Mario-cartoon/ArticleBD/main/Category_articles.csv' AS line
MATCH (category:Category {categoryID: line.title_category})
MATCH (article:Article {articleID: line.title_article})
CREATE (article)-[:IS_IN]->(category);
'''
conn.query(query_string, db='graphDb')
# LOAD READ_ARTICLES
query_string ='''
LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/Mario-cartoon/ArticleBD/main/read_articles.csv' AS line
MATCH (reader:Reader {readerID: line.name})
MATCH (article:Article {articleID: line.title_article})
CREATE (reader)-[:READ]->(article);
'''
conn.query(query_string, db='graphDb')
Итог:
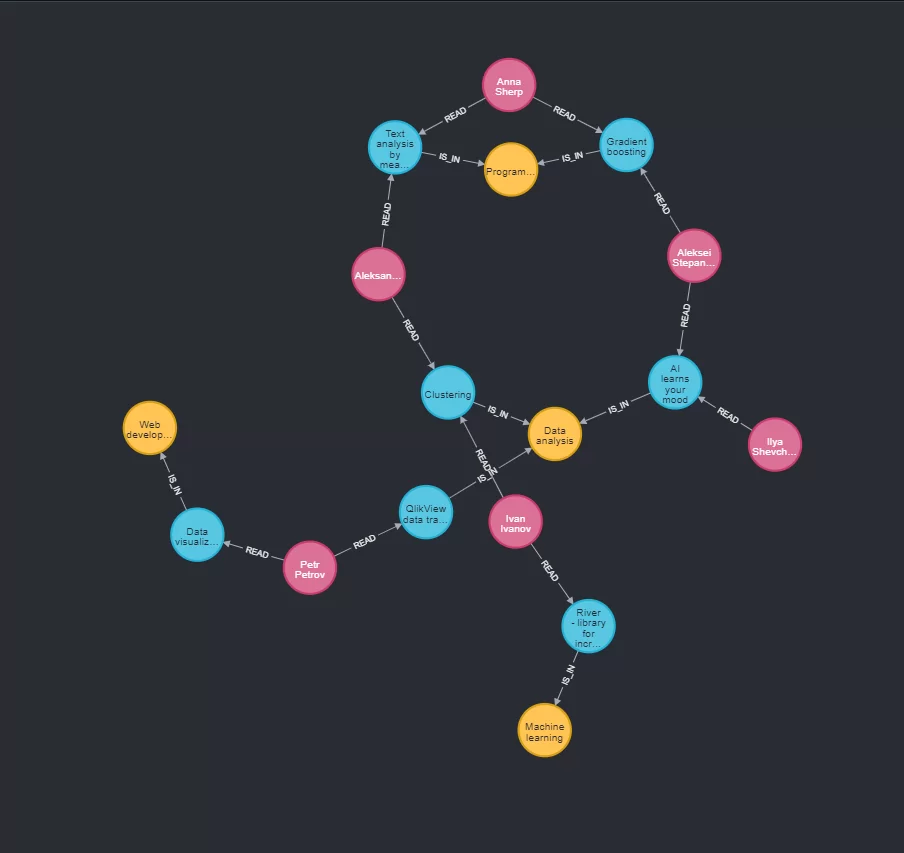
3. Создаём рекомендации статей для читателей основываясь на прочитанных статьях
Для этого пишем запрос:
MATCH (reader:Reader)
MATCH (unread_article:Article)
WHERE NOT ((reader)-->(unread_article))
MATCH (article:Article)
WHERE ((reader)-->(article))
MATCH (unread_article)-[:IS_IN]->()<-[:IS_IN]-(article)
CREATE(rec: RecommendationArticleToReader {nickname: reader. nickname })
WITH rec, unread_article, reader
MERGE(rec)-[rel:USED_TO_PROMOTE {email: reader.email}]->(unread_article)
RETURN rec, unread_article, rel;
В запросе отбираем прочитанные статьи от непрочитанных, создавая новую сущность RecommendationArticleToReader, которая содержит nickname читателей. После создаем новую связь: RECOMMEND_READING, где связываем непрочитанную статью, той же категории, что и статьи, которые уже прочитал читатель. В итоге получим следующий граф:
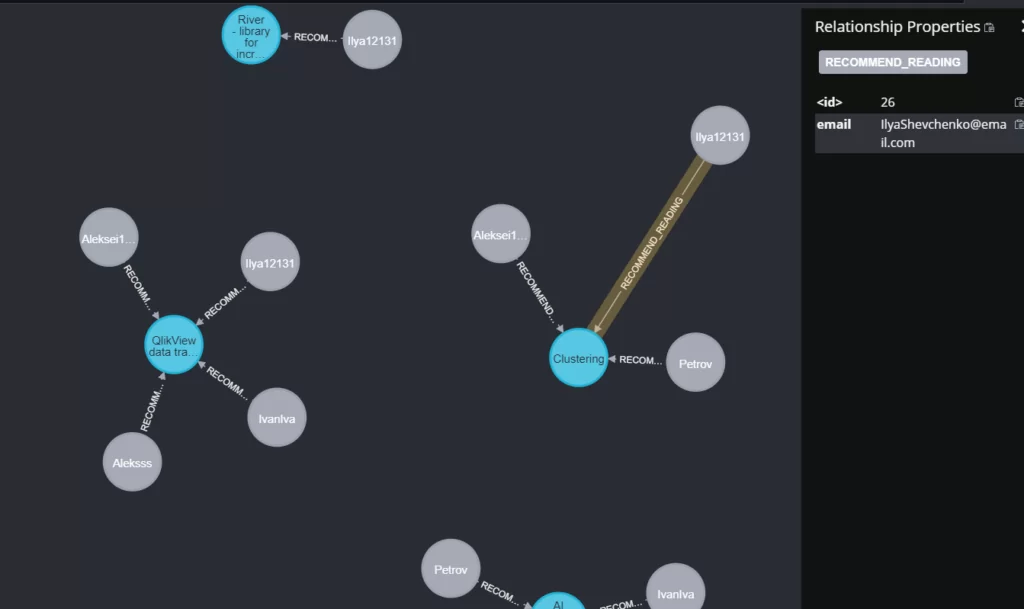
Обращаю внимание, что в связи: RECOMMEND_READING передается email читателя.
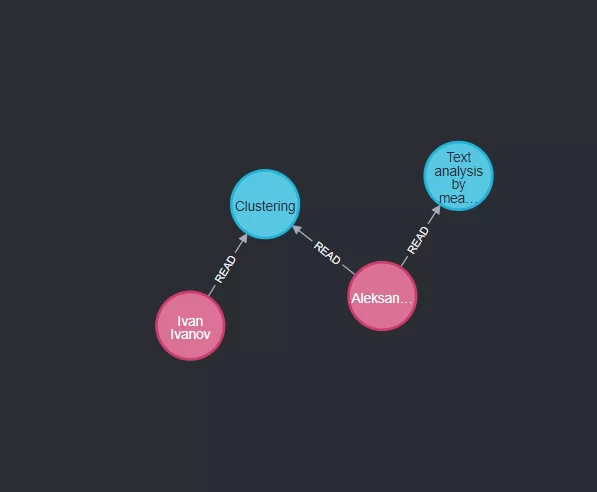
Теперь выведем все связи и сущности, а также проанализируем получившийся граф, а именно, возьмем одного читателя и посмотрим все связи. Для примера возьмем Ivan Ivanov. Из графа видно, что он прочёл, и какие статьи ему предлагается прочитать.
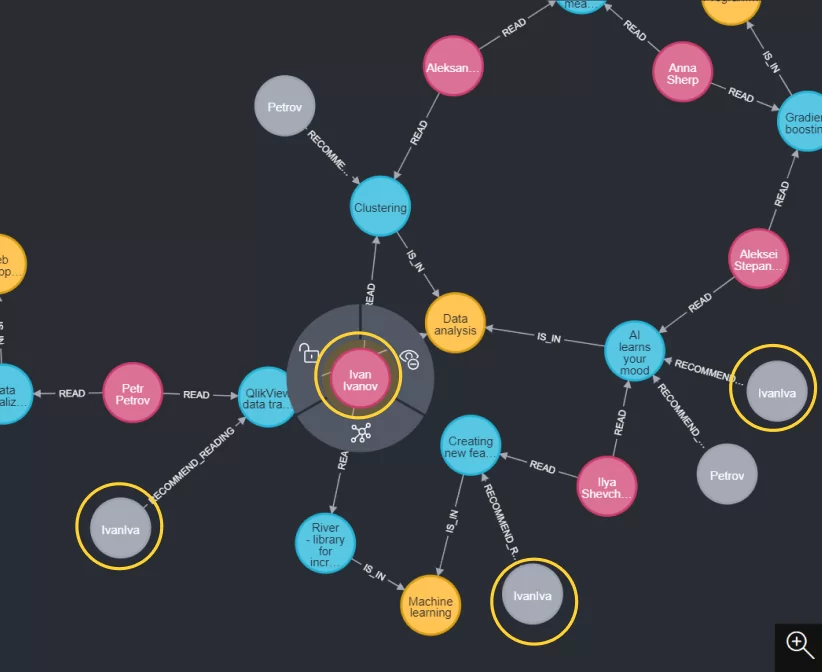
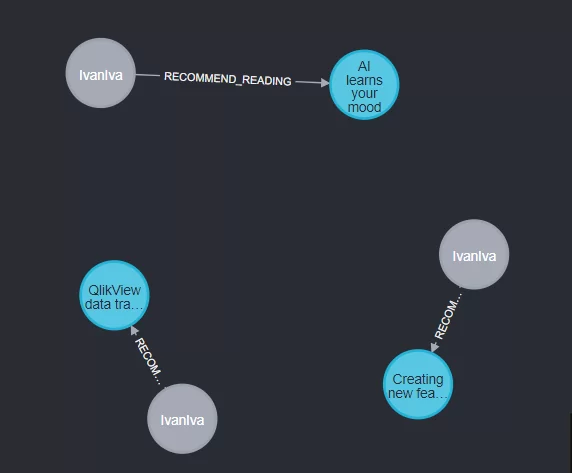
Давайте напишем запрос чтобы вывести только рекомендации по читателю Ivan Ivanov:
MATCH (rec: RecommendationArticleToReader {type:'IvanIva'})-[:RECOMMEND_READING]->(article:Article)
RETURN article,rec;
Получаем:
4. Пробуем рекомендовать статьи
Основываемся на прочтённых статьях других читателей, которые имеют хотя бы одну прочтённую статью с другим читателем. Для этого пишем запрос, который выведет всех читателей и прочтённые статьи:
MATCH (reader:Reader)-->(article:Article)
RETURN reader, article;
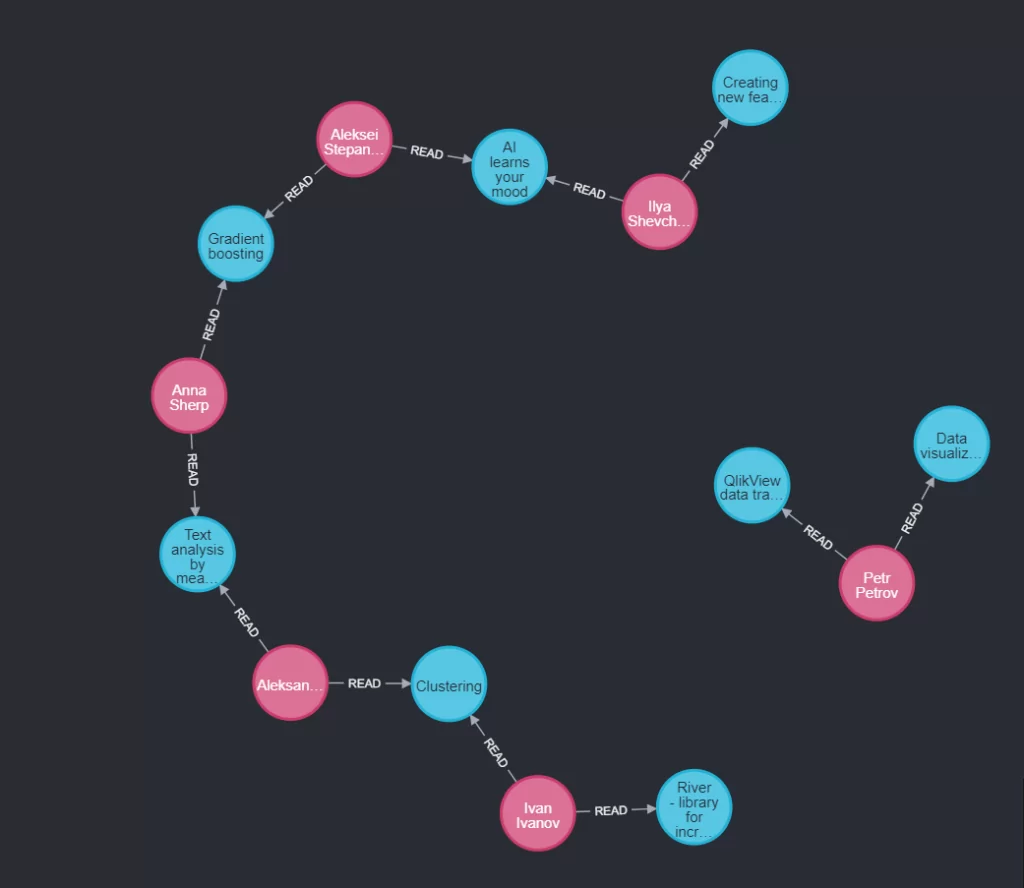
Из графа видно, что у многих читателей есть общие прочитанные статьи, и мы можем рекомендовать им те статьи, которые прочёл читатель (с которым есть общая прочтённая статья), но не прочел другой. Для примера возьмем читателя Ivan Ivanov. Пишем запрос:
MATCH (reader_1:Reader{nickname:'IvanIva'})-->(article_1:Article)<--(reader_2:Reader)
MATCH (reader_2)-->(article_2:Article)
WHERE (article_2 <> article_1)
RETURN reader_1, reader_2, article_2,article_1;
С помощью этого запроса мы возвращаем статью, не прочитанную Ivan’ом, но прочитанную читателем, с которым у Ivan’a есть общая прочитанная статья. Т.е. в переменной article_2 хранится статья, не прочитанная Ivan’ом. Для примера возвратили все переменные чтобы увидеть связь между сущностями.
Но, чтобы вывести только нужные статьи, достаточно вернуть только переменную article_2.
В данной статье был рассмотрен базовый функционал Neo4j и примеры его использования. Это очень удобный и понятный инструмент графовых баз данных. Но использовать его стоит только для решения задач, которые решаются с использованием графов. Важно также отметить, что Neo4j это не фреймворк и сравнивать его с gephi или networkx нет смысла. Потому что Neo4j не просто визуализирует данные, но и содержит их, так как является базой данных.