/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
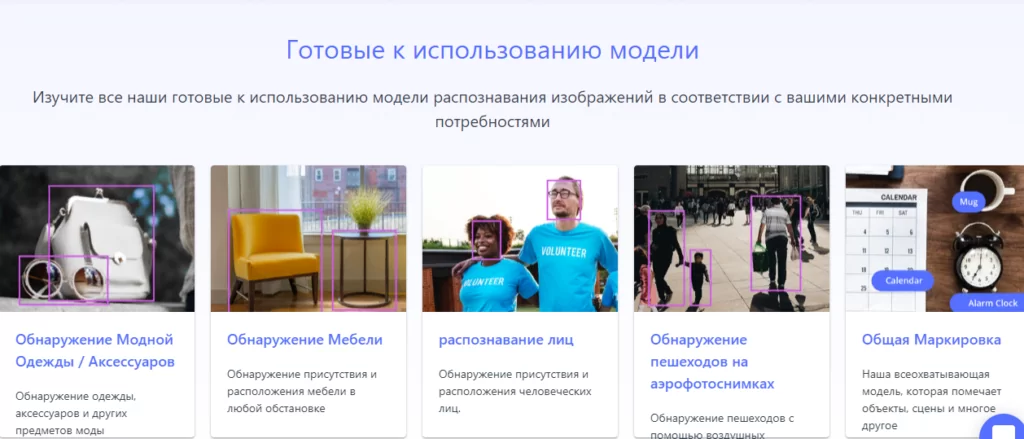
При проведении проверки возникла необходимость в обработке большого количества товарных и кассовых чеков, с дальнейшим заполнением обнаруженных данных в базу данных. Именно в этот момент на глаза попалось довольно интересное API, предназначенное для обработки изображений Nanonets API. В распоряжении данного API существует множество уже обученных моделей распознавания, классификации и кластеризации. Некоторые из этих моделей представлены на рисунке ниже:
Для дальнейшей работы создадим и обучим свою собственную сеть:
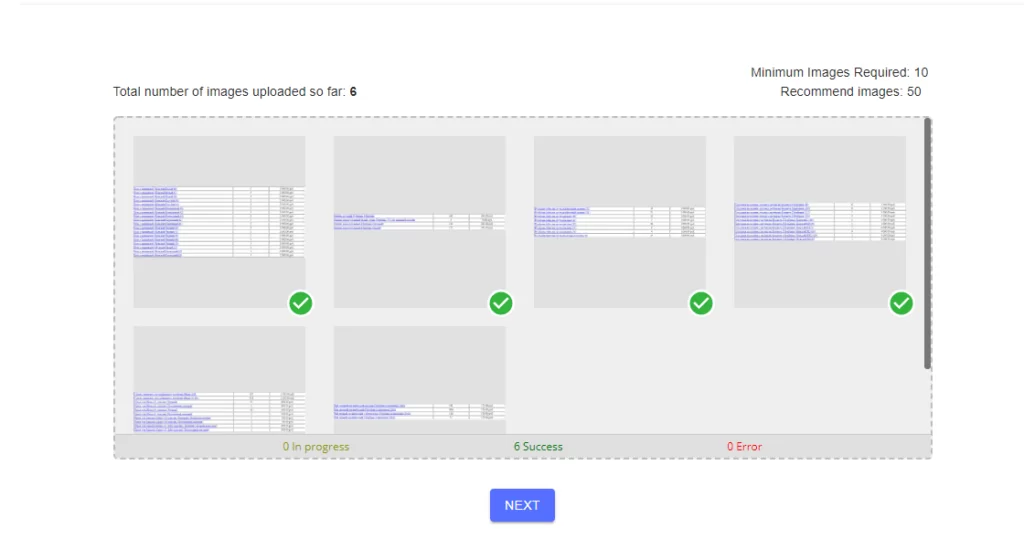
После создания модели, необходимо загрузить данные для её обучения, осуществимого после нанесения меток и их значений на изображения.
В качестве тестовых значений будем использовать таблицы с товарами, как показано на рисунке ниже:
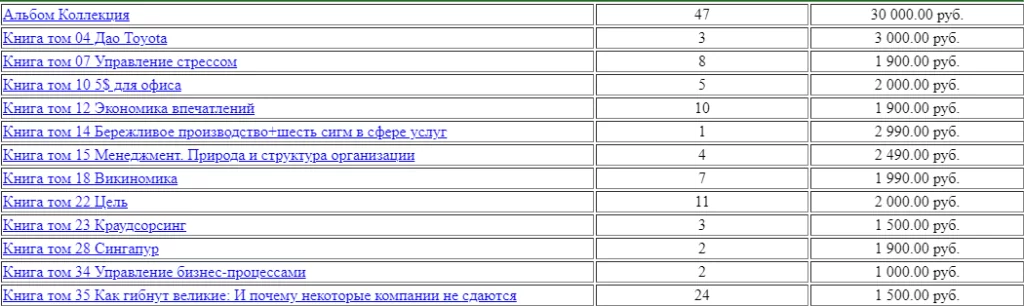
Для разметки нашей модели создадим две метки – Name, соответствующую наименованию товара и Price – цене товара.
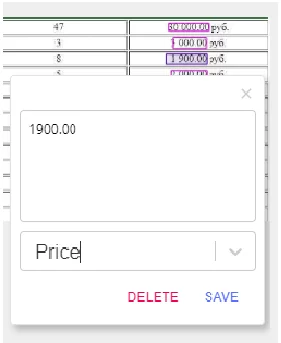
После разметки обучающей выборки переходим к тренировке полученной модели.
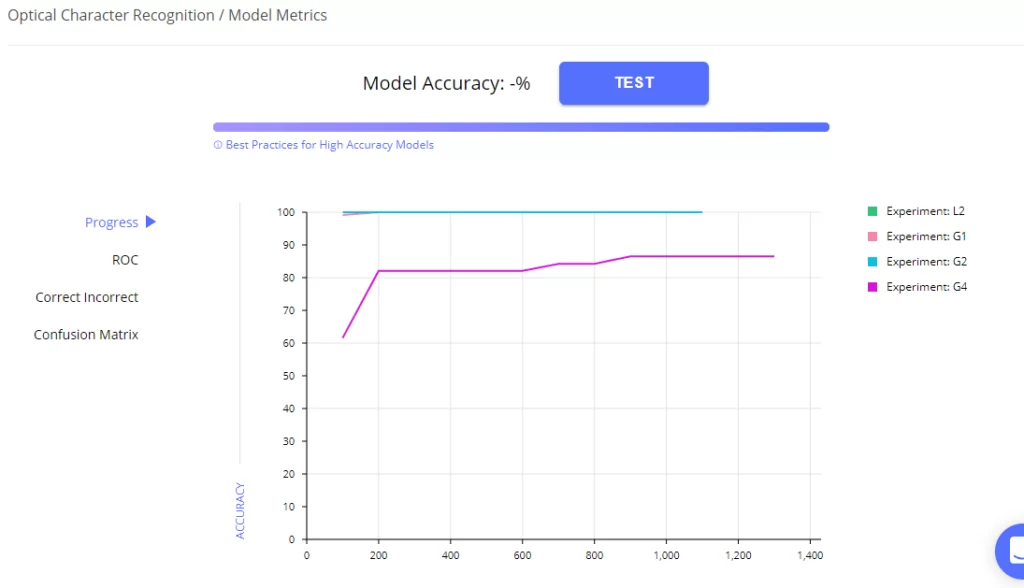
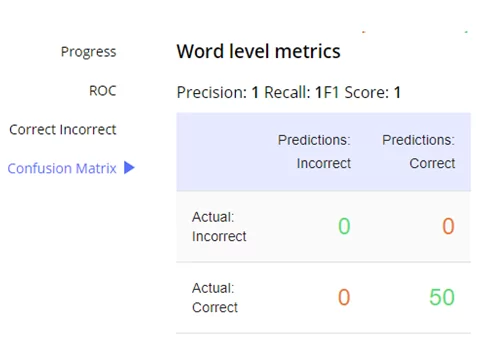
Для обученной модели можно посмотреть наиболее распространенные метрики качества модели:
После тренировки модели необходимо проверить её работоспособность, для выявления недостатков обучения модели и дополнения обучающей выборки новыми, размеченными данными. Использование модели организовано посредством отправки http – запросов к api nanonets и обработке полученного в формате json ответа. Для скачивания кода для дальнейшей работы необходимо выбрать вкладку Integrate, выбрать код для решения нашей задачи (в нашем случае файлы будут находиться непосредственно на рабочем компьютере, поэтому необходимо выбрать вкладку «Code for file»), определиться с языком программирования, используемым для отправки запросов.
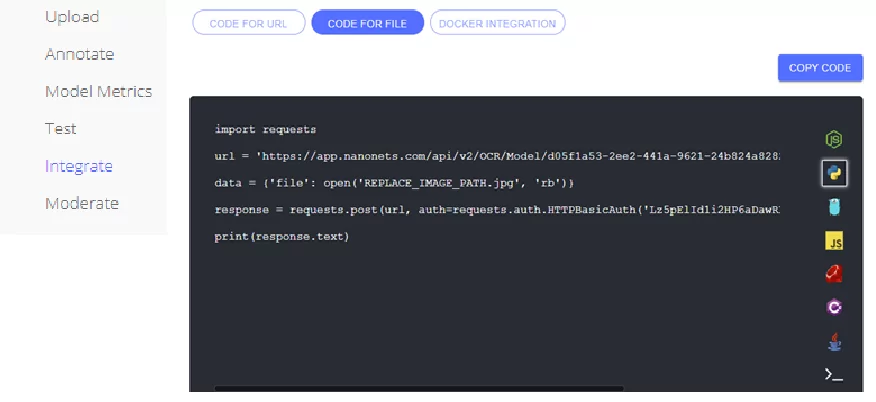
В результате выполнения представленного кода, получим json-файл следующего формата:

Так же результат работы модели можно увидеть в личном кабинете платформы Nanonets:
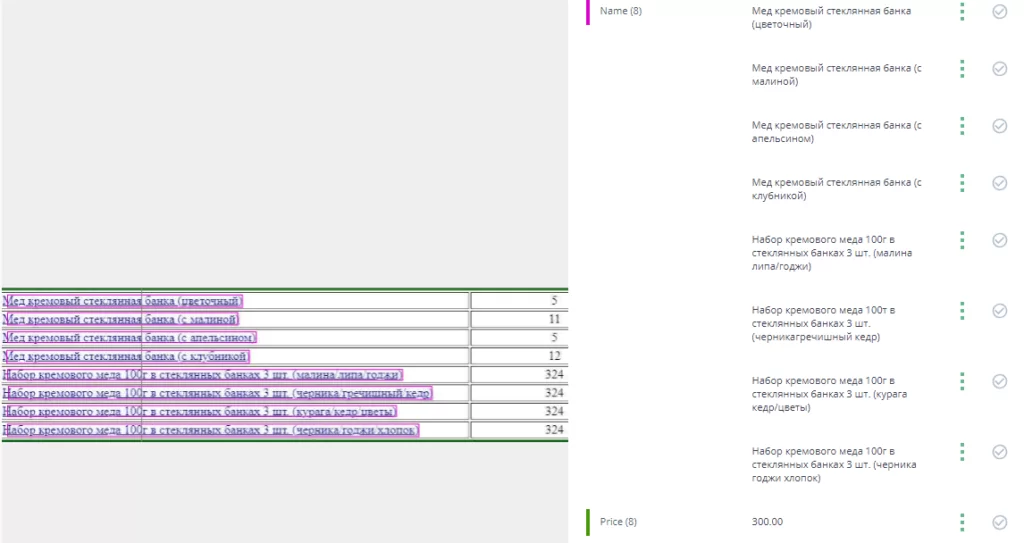
Если в результирующем изображении обнаружены недостатки при распознавании, можно произвести исправление ошибок в метках и полученных для них значениях, чтобы дополнить модель и улучшить модель.
Как видно из примера, использование данной платформы для обучения моделей распознавания текстовых данных даёт довольно хорошие результаты после разметки небольшого количества тестовых изображений.