/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 10 мин.
Архитектурно DALL-E — это версия GPT-3, к которой был добавлен хитрый способ токенизации изображений, позволяющий создавать мультимодальный словарь, в котором часть токенов отвечает за текст, а вторая часть за изображение.
Что означает мультимодальность? Это модальность в разных сочетаниях: видео и текст, аудио и текст. Таким образом, вы можете представить это себе как классическую задачу для компьютера в сфере искусственного интеллекта, который может обрабатывать происходящее на изображении, интерпретировать и описывать все происходящие события, учитывая фон, изменения положений вещей в пространстве и контекст происходящего.
После некоторого количества исследований, стало понятно, что DALL-E способна порождать широкий ассортимент генеративных изображений. Можно сказать, что охват и виральность мультимодального искусственного интеллекта потенциально широки и, в первую очередь, могут применяться в сферах, связанных с творчеством, дизайном и игровой индустрии. Поэтому наряду с большим успехом визуального представления текста, OpenAI опасаются, что такие модели могут сильно повлиять на социальную и экономическую системы. И, уже по сложившейся традиции, не стали выпускать DALL-E в открытый доступ.
Несмотря на это, они выпустили CLIP (Contrastive Image-Language Pretraining, что можно перевести как контрастное предварительное обучение образному языку), который в своём роде половина движка DALL-E.
CLIP – ещё одна мультимодальная сеть, способная оценить изображение и соотнести, подходит ли к ней подпись или наоборот. Таким образом, CLIP принимает текст и изображение и связывает их непроизвольным способом, что, в свою очередь, позволило применять иные модели, способные генерировать изображения вместе с ним, такие как VQGAN.
VQGAN (Vector Quantized Generative Adversarial Network), что переводится как векторная квантованная генеративная адверсариальная сеть — это генеративно-состязательная нейросеть, которую используют для изучения изображений и создания новых, на основе ранее увиденных. Работая вместе, VQGAN генерирует изображение, а CLIP выступает как ранжировщик, оценивая насколько хорошо изображение подходит тексту. Именно эту связку мы используем ниже для того, чтобы вы сами смогли создать результат их совместной работы, даже не обладая навыками программирования, но не стоит забывать и про ruDALL-E.
По аналогии с ruGPT-3, Сбер выпустил первую мультимодальную нейросеть ruDALL-E, основанную на архитектуре DALL-E, способную понимать русский язык, и сделал её открытой, а также создал сайт, на котором можно по любому запросу попробовать сгенерировать изображение (ссылку приложу в конце статьи).А пока вы можете полюбоваться моими результатами по запросам «Сбер в стиле Ван Гога» и «страшно красиво», кстати, обложка для статьи также создана ru-DALL-E по соответствующему запросу «обложка для статьи».

По словам управляющего директора департамента SberDevices Сергея Маркова, несмотря на то, что в описании к DALL-E содержалась информация про архитектуру решения, pipeline, который использовался, но сведений все равно было недостаточно. Поэтому для создания своей версии модели требовалось пробовать и экспериментировать, отталкиваясь от полученных результатов. А самое большое количество сил было потрачено на сбор данных.
Вернёмся к связке VQGAN + CLIP. Сейчас будет описание, каким образом VQGAN генерирует изображения, которое в последствии оценивает CLIP. Если вас не очень интересует, что там под капотом VQGAN, то можете смело перейти к следующей части создания своего изображения.
Рассмотрим, как VQGAN в VQGAN-CLIP работает для генерации и синтеза изображений с высоким разрешением, которые мы видим сегодня.
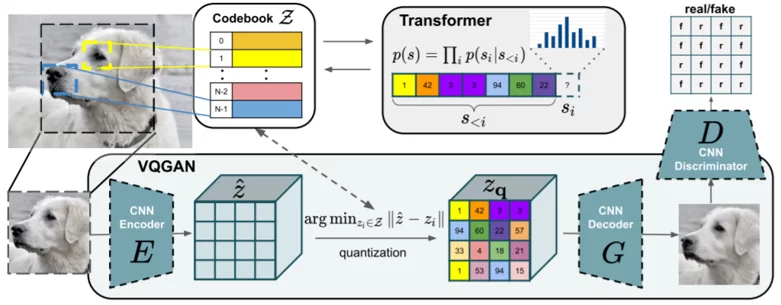
Метод преобразования для синтеза изображений в высоком разрешении состоит из двух этапов.
На первом этапе (нижняя половина изображения) кодировщик и декодер обучаются восстанавливать изображения. Это базовый квантованный автоматический кодировщик плюс дискриминатор, который классифицирует образцы как настоящие или поддельные. Взаимодействие с ним улучшает реконструкцию, позволяя синтезировать убедительно поддельные образцы.
Имеется входное изображение, и мы хотим обучить такое скрытое пространство, которое закодировало бы всю семантическую информацию об этом изображении. Информацию, которую можно было бы использовать для восстановления изображения.
Используемый квантованный кодировщик, был предложен ранее в другой статье (VQ-VAE, van den OORD et al., 2018). Стоит уточнить, что векторное квантование — это метод обработки сигналов для кодирования векторов. Он представляет все визуальные части, обнаруженные на этапе свертки, в квантованной форме, что делает его менее затратным с точки зрения вычислений после передачи в трансформер.
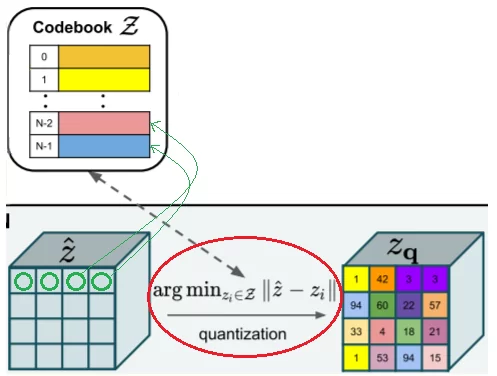
Основная идея здесь заключается в том, что для каждого в ячейке тензора мы находим ближайшего соседа слова в кодовой книге. После чего используем его вместо исходного вектора, поэтому в основном на этом этапе мы вычисляем аргумент для каждой ячейки в тензоре и заменяем его на кодовое слово, которое было получено из кодовой книги, и вместо того, чтобы использовать кодировщик только на полученных словах, мы также применяем его к кодовой книге.
Таким образом, VQGAN использует кодовую книгу как промежуточное представление, после чего кодовая книга изучается с использованием векторного квантования (VQ).
VQGAN делает векторы признаков похожими на присвоенные кодовые слова в кодовой книге, и в то же время кодовые слова также обучаются напоминать распределение векторов признаков в наборе данных.
Проблема здесь в том, что свёрточная природа кодировщика и декодера не позволяет им моделировать долгоиграющие взаимосвязи, потому что поле восприятия каждого свёрточного слоя ограничено, что обычно не позволяет моделировать и генерировать большие изображения. В то же время трансформер – это архитектура, которая позволяет моделировать такие взаимосвязи, но у него есть свои ограничения, он не может работать с действительно большими последовательностями, потому что для этого требуется вычислять взаимосвязь между каждой парой элементов этой последовательности, что требует больших вычислительных ресурсов из-за квадратичной масштабируемости.
Создатели предлагают, моделировать изображение не на уровне пикселей напрямую, а на основе кодовых слов изученной кодовой книги. То есть после того, как модель первого этапа узнала, что у нас есть кодовая книга, и мы можем использовать её, чтобы обучить трансформер для генерации последовательности этих кодовых слов.
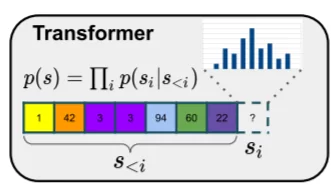
Таким образом, у нас есть закодированная последовательность с индексами s<i , которая может быть очень длинной, а трансформер прогнозирует распределение возможных следующих индексов p(si|s<i) .
Преимущество заключается в том, что разрешение, с которым мы работаем, намного ниже, чем разрешения исходного пиксельного изображения, поэтому мы можем моделировать более длинные взаимосвязи внутри изображений. Каждый блок последовательности соответствует местоположению, которое представляет собой сотни пикселей.
Обучение этого трансформера является вторым этапом. Мы не обновляем модель первого этапа, а генерируем последовательность кодовых слов, которая будет образовывать желаемое разрешение, а затем мы используем тензор кодовых слов и передадим его в декодер для создания нового изображения, в основном не ограниченного размером.
Чтобы повысить эффективность вычислительных ресурсов трансформера, авторы ограничивали контекст с помощью скользящего окна. Это означает, что при генерации каждого патча он получает информацию только от своих соседей.

Что должно работать, когда изображение имеет некоторые однородные структуры, например, различные изображения пейзажей.
Делая выводы, мы можем сказать, что реализованный в VQGAN двухэтапный подход состоит из свёрточной нейронной сети в форме GAN, который состоит из кодировщика и декодера, и трансформера, использующего окно скользящего внимания при выборке изображений, и который требует использования кодовой книги, полученной с помощью векторного квантования для улучшения масштабирования. Кодовая книга же обучается вместе с двумя моделями.
Всё это демонстрирует нам возможность синтеза изображений с высоким разрешением, позволяя создавать в своём роде произведения искусства.
Для создания своего изображения, воспользуемся данным колабом https://colab.research.google.com/github/justin-bennington/somewhere-ml/blob/main/S2_VQGAN%2BCLIP_Classic.ipynb
и скажем спасибо за него Кэтрин Кроусон.
Google Colab — это бесплатный сервис, представляющий всё необходимое для машинного обучения, разделенный на множество отдельных ячеек.
Итак, для того, чтобы попробовать сгенерировать изображения, для начала нужно настроить, так называемый, блокнот. В правом верхнем углу блокнота (рис.1) вы увидите кнопку с надписью: «Подключиться», нажав на которую, вы сможете начать выполнение кода. Это так же потребует от вас войти в свой аккаунт Google.

Затем запустите первую ячейку (рис.2) (соглашение с лицензией MIT) и переходите сразу к четвертой (рис.3), так же запустив её, нажав на треугольник в кружке. Это установит все нужное для процесса генерации изображений.


Следующая ячейка (рис.4) позволяет вам выбрать одну из моделей VQGAN, что по своей сути влияет на то, какой набор данных использовался для обучения. Вы можете попробовать все и посмотреть, что даст для вас лучший результат. После чего смело запускайте следующую ячейку (рис.5) с загрузкой, ранее установленных в ячейке 4, библиотек.


Дальше идёт ячейка (рис.6), отвечающая за параметры изображения, именно эти параметры отвечают за изображение, которое мы хотим сделать. Приведём их краткое описание:
Prompts: в это поле нужно вводить запрос, по которому вы желаете создать изображение (на английском языке).
width: ширина генерируемого изображения в пикселях.
height: высота сгенерированного изображения в пикселях.
model: выбираем желаемую модель.
display_frequency: VQGAN+CLIP берет исходное изображение и многократно повторяет его, пока оно не превратится в последовательное изображение. Частота отображения определяет, сколько раз машина выполнит повтор изображения, прежде чем показать его вам, т.е. указав число 15, вам будут демонстрироваться изображения, порядковый номер которых кратен пятнадцати.
initial_image: вы можете задать изображение, с которого будет начат путь по генерации, указав путь до файла в вашем гугл-диске
target_images: вы можете задать изображение, к которому будет стремиться изображение, указав путь до файла в вашем гугл-диске
seed: Если вы не указываете начальное изображение, то этот параметр задаёт случайное изображение для старта, если выбрано “-1”, а при использовании любого целого положительного числа будет генерироваться одно и то же изображение, соответствующее этому числу.
max_iterations: количество повторов, которое машина выполнит перед завершением процесса. Если указать “-1”, то процесс будет выполняться до тех пор, пока вы его не остановите.

Выполнив ячейку с параметрами, вы можете нажимать следящую ячейку (рис.7), которая непосредственно запустит работу алгоритма. Вам останется только дождаться генерации изображений, а затем собрать из них видеопредставление (рис.8) и наслаждаться получившимся. Вы так же можете скачать его себе, используя данные две строчки кода:
from google.colab import files
files.download(video_filename)


Напоследок напишу, что Кэтрин Кроусон не советует использовать очень большие разрешения для изображений, зачастую колабу не хватает памяти для реализации такого контента. А также, что вы можете придавать больший вес некоторым из своих заданных слов, добавив двоеточие, а затем число до 100, например: пустыня:50 | в снегу:25″, при условии, что вы задаёте множественный запрос. От себя добавлю, что проблемы начинали возникать при попытке сгенерировать изображения свыше 700 на 700.
Как видите, использовать подобные технологии становится всё проще, а их результат, не в единичных случаях, вызывает интерес. Студия Артемия Лебедева уже в 20 году во всю использовала нейронную сеть под человеческим именем “Николай Иронов”, как автоматизацию творческого процесса с коммерческим потенциалом, а нашумевшая NFT-токенизация подстегнула рядовых пользователей к цифровому искусству, частью которого является генеративное искусство. Лично меня прельщает мысль о подобном выходе за рамки восприятия искусства человеком, когда грань между произведением и созерцателем практически стёрта, искусство приобретает новые инструменты, а инструменты порождают искусство. А вас?
P.s. Полезные ссылки.
Мой пост про GPT-J-6B GPT-J-6B языковая модель с открытым исходным кодом (newtechaudit.ru)
ruDALL-E: https://rudalle.ru/
Статья про VQGAN: https://arxiv.org/pdf/2012.09841.pdf
Более подробное объяснение работы VQGAN: https://ljvmiranda921.github.io/notebook/2021/08/08/clip-vqgan/