/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Одной из задач фоноскопической экспертизы является установление подлинности и аутентичности аудио записи — другими словами, выявление признаков монтажа, искажения и изменения записи. У нас возникла задача её проведения в целях установления подлинности записей – определения того, что на записи не осуществлялось никаких воздействий. Но как провести анализ тысяч, и даже сотен тысяч аудиозаписей?
Нам на помощь приходят методы AI, а также утилита по работе с аудио, о которой мы писали ранее «ОБРАБОТКА АУДИО С ПОМОЩЬЮ FFMPEG».
Как проявляются внесенные изменения в аудио? Как отличить файл, который изменили, от нетронутого файла?
Таких признаков несколько и самый простой — это выявление информации по редактированию файла и анализ даты его изменения. Данные способы легко реализуются средствами самой ОС, поэтому на данных способах мы останавливаться не будем. Но изменения может вносить более квалифицированный пользователь, который сможет скрыть или изменить информацию о редактировании, в таком случае применяются более сложные методы, например:
- сдвиг контуров;
- изменение спектрального профиля, записанного аудио;
- появление пауз;
- и многие другие.
И все эти сложно звучащие методы выполняются специально обученными экспертами — фоноскопистами с помощью специализированного софта типа Praat, Speech Analyzer SIL, ELAN, большая часть из которого платная и требует достаточно высокой квалификации для использования и трактовки результатов.
Экспертами анализ аудио осуществляется с использованием спектрального профиля, а именно, анализируя его мел-кепстральные коэффициенты. Воспользуемся опытом экспертов, и заодно используем готовый код, адаптировав его под нашу задачу.
Так изменений, которые можно внести большое множество, как будем выбирать?
Из возможных видов изменений, которые можно внести в аудио файлы, нас интересуют вырезание части из аудио, либо вырезание части и последующая замена оригинальной части аналогичным по длительности куском — так называемые cut/copy изменения, т.к. редактирование файлов в части шумоподавления, изменение частоты тона и прочие не несут рисков сокрытия информации.
И как мы будем выявлять эти самые cut/copy? Их же надо с чем-то сравнивать?
Очень просто – с помощью утилиты FFmpeg мы будем вырезать из файла часть случайной длительности и в случайном месте после чего будем осуществлять сравнение мел-кепстральных спектрограмм оригинального и «порезанного» файла.
Код для их отображения:
import numpy as np
import librosa
import librosa.display
import matplotlib.pyplot as plt
def make_spek(audio):
n_fft = 2048
y, sr = librosa.load(audio)
ft = np.abs(librosa.stft(y[:n_fft], hop_length = n_fft+1))
spec = np.abs(librosa.stft(y, hop_length=512))
spec = librosa.amplitude_to_db(spec, ref=np.max)
mel_spect = librosa.feature.melspectrogram(y=y, sr=sr, n_fft=2048, hop_length=1024)
mel_spect = librosa.power_to_db(mel_spect, ref=np.max)
librosa.display.specshow(mel_spect, y_axis='mel', fmax=8000, x_axis='time');
plt.title('Mel Spectrogram');
plt.colorbar(format='%+2.0f dB');
plt.show();
make_spek('./audio/original.wav')# './audio/original.wav' место расположения аудио файлаПодготовку датасета из исходных и порезанных файлов осуществляем с помощью команды утилиты FFmpeg:
ffmpeg -i oroginal.wav -ss STARTTIME -to ENDTIME -acodec copy cut.wav где STARTTIME и ENDTIME начало и окончание вырезанного фрагмента. А с помощью команды:
ffmpeg -iconcat:"part_0.wav|part_1.wav |part_2.wav" -codeccopyconcat.wavсоединяем часть файла для вставки part_1.wavс оригинальными частями (оборачивание команд FFmpeg в python смотрите нашу статью про FFmpeg).
Вот как выглядят оригинальные мел-спектрограммы файлов из которых были вырезаны части аудио по 0.2-2.5 секунды, и мел-спектрограммы файлов, из которых были вырезаны части аудио по 0.2-2.5 секунды, а после вставлены аудио фрагменты аналогичной длительности из этого аудиофайла:
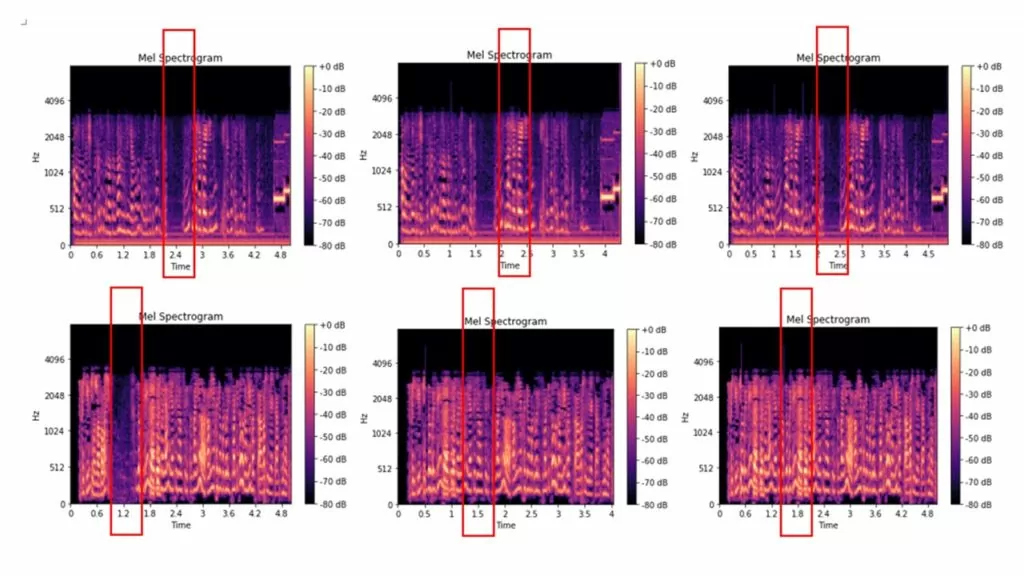
Некоторые изображения различимы даже зрительно, другие выглядят практически одинаковыми. Распределяем полученные картинки по папкам и используем как исходные данные для обучения модели по классификации изображений. Структура папок:
model.py # модель
/input/train/original/ # оригинальные файлы аудио
/input/train/cut_copy/ # измененные файлыДля нас нет никакой разницы был ли измененный аудио файл дополнен или сокращен — мы делим все результаты на хорошие, то есть файлы без изменений, и плохие. Таким образом, у нас решается классическая задача бинарной классификации. Классифицировать будем с использованием нейросетей, код для работы с нейросетью возьмем готовый из примеров работы с пакетом Keras.
# Импортируем необходимые библиотеки и пакеты
from keras.models import Sequential
from keras.layers import Flatten
from keras.layers import Dense
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
# Проводим инициализацию нейросети
classifier = Sequential()
classifier.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Conv2D(32, (3, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Flatten())
classifier.add(Dense(units = 128, activation = 'relu'))
classifier.add(Dense(units = 1, activation = 'sigmoid'))
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
# Обучаем нейросеть на изображениях
from keras.preprocessing.image import ImageDataGenerator as img
train_datagen = img(rescale = 1./255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
test_datagen = img(rescale = 1./255)
training_set = train_datagen.flow_from_directory('input/train',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
test_set = test_datagen.flow_from_directory('input/test',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
classifier.fit_generator(
training_set,
steps_per_epoch = 8000,
epochs = 25,
validation_data = test_set,
validation_steps = 2000)Далее, после того как модель обучилась, проводим классификацию с её помощью
import numpy as np
from keras.preprocessing import image
test_image = image.load_img('dataset/prediction/original_or_corrupt.jpg', target_size = (64, 64))
test_image = image.img_to_array(test_image)
test_image = np.expand_dims(test_image, axis = 0)
result = classifier.predict(test_image)
training_set.class_indices
ifresult[0][0] == 1:
prediction = 'original'
else:
prediction = 'corrupt'На выходе получаем классификацию аудио файла — ‘original’/’corrupt’, т.е. файл без изменений и файлы, в которые изменения были внесены.
Мы лишний раз доказали, что сложно выглядящие вещи можно сделать просто – использовали не самый трудный механизм методов AI, готовые решения и провели проверку аудио на предмет внесения изменений. Ну и побыли экспертами из детектива.