/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 4 мин.
Интересная тема для обсуждения, не так ли? Для начала обратимся к предыдущей статье цикла, описывающей применение методов NLP в аудите, где я использовал линейную обработку русскоязычного текста. Посмотреть статью можно здесь в открытом доступе: https://newtechaudit.ru/nlp-i-audit/
Сложность состоит в том, что я подвергал обработке масштабные русскоязычные тексты, полные уникальных слов. Поэтому использование таких инструментов, как natasha, занимало большое время. Рассмотрим пример используемой функции препроцессинга:
def preproc_line(line, stop_words):
line = ''.join(i for i in line if not i.isdigit())
line = line.translate(str.maketrans('', '', string.punctuation))
line = line.lower()
if len(stop_words):
line = del_stopwords(line, stop_words)
line = pymorphy_preproc(line)
line = ' '.join(line)
line = sub_names(line)
line = sub_dates(line)
return line
Здесь я последовательно очистил данные, удалил стоп-слова, выделил именованные сущности (имена и даты)
vectorizer = TfidfVectorizer(ngram_range = (1, 2))
vect = vectorizer.fit_transform(X_train)
А затем токенизировал и выделил биграммы. Все это я уже демонстрировал ранее, теперь обратимся к главной проблеме: времени исполнения. Воспользуемся классической библиотекой, которая поможет нам измерять время выполнения программы:
import timeИ оценим, как долго будет исполняться целевая функция в стандартном виде:
start_time = time.time()
X_train = preproc_data(outp_df, words_pack_1, 'Text')
print("--- %s seconds ---" % (time.time() - start_time))

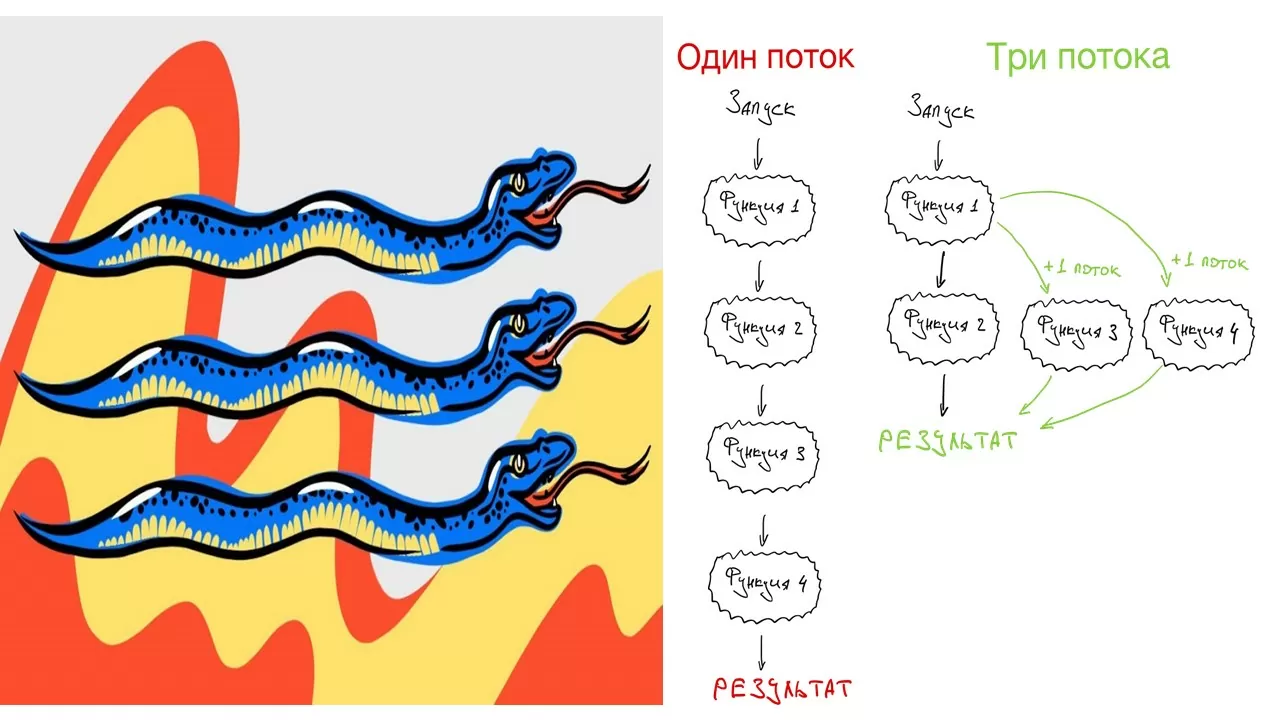
Ого, несколько тысяч коротких сообщений из чат-бота и более минуты исполнения! Как же мы можем ускорить этот процесс? Для этого и используется многопоточность, то есть разделение одного процесса на несколько потоков, работающих независимо. Нашу структуру упрощает также то, что нам не нужна синхронизация потоков, поскольку обрабатывать мы можем датасет частями и последовательно, не обмениваясь информацией при перезаписывании. Для этого волшебства нам понадобятся всего две библиотеки, одна из которых делит процесс на потоки, а вторая нужна для создания физической копии обрабатываемых данных. Выигрыш во времени, проигрыш в памяти.
import threading
from copy import copy
Теперь создадим копию:
data_new = copy(data)И обернем нашу функцию препроцессинга таким образом, чтобы она обрабатывала только часть данных, то есть срез:
def thread_function(data, data_from, data_to, stop_words):
for i in range(data_from, data_to):
data_new[i] = ''.join(preproc_line(data[i], stop_words))
return data
Теперь создадим список для хранения открытых потоков, затем определим размер среза данных, пропорциональный количеству потоков:
threads = []
num_threads = 1
bunch_size = (len(data) + num_threads - 1) / num_threads;
Отлично. Далее пройдемся по всему списку обрабатываемых сэмплов и применим треды к каждому срезу по отдельности:
for i in range(num_threads):
data_from = int(bunch_size * i)
data_to = int(bunch_size * (i + 1))
if data_to > len(data):
data_to = int(len(data))
x = threading.Thread(target=thread_function, args=(data, data_from, data_to, words_pack_1))
threads.append(x)
x.start()
for index, thread in enumerate(threads):
thread.join()
Финал: смотрим на время исполнения всей конструкции (тот же результат, что и без потоков):

Действительно, какой выигрыш во времени! В самом деле, работает. И это может быть гораздо важнее и заметнее на более длинных текстах, на большем количестве сообщений, с применением большего числа функций выделения именованных сущностей.
Также в зависимости от процессора/ОС/движка Python можно использовать и разделение работы на несколько процессов. Для этого легко воспользоваться библиотекой:
from multiprocessing import ProcessА разработка имеет тот же синтаксис:
data = list(outp_df['Text'].astype(str))[:10]
data_new = copy(data)
def proc_function(data, data_from, data_to, stop_words):
for i in range(data_from, data_to):
data_new[i] = ''.join(preproc_line(data[i], stop_words))
return data
processes = []
num_processes = 2
bunch_size = (len(data) + num_processes - 1) / num_processes;
for i in range(num_processes):
data_from = int(bunch_size * i)
data_to = int(bunch_size * (i + 1))
if data_to > len(data):
data_to = int(len(data))
x = Process(target=proc_function, args=(data, data_from, data_to, words_pack_1))
processes.append(x)
x.start()
for index, process in enumerate(processes):
process.start()
for index, process in enumerate(processes):
process.join()
Однако на физическом уровне работа такого алгоритма серьезно отличается от использования потоков: исполнение переносится уже на несколько независимых процессов по разным ядрам машины. Это может быть много быстрее, чем разделение на потоки, однако требует большего количества ресурсов CPU, а также особенностей движка, например, механизмов очистки мусора.