/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Исходные данные – скан-копии, большинство файлов достаточно большого объема. Документы были предварительно преобразованы из pdf в txt (с помощью ABBYY). Чтобы не анализировать весь текст документов, которые иногда могут содержать и 500 страниц, будем использовать срезы. Возможна ситуация, когда документ относится сразу к нескольким категориям, к примеру, договор с приложениями. Если для анализа берутся срезы, то идентифицировать приложения в таких случаях не получится, но для нас это не имеет значение, так как «основная» категория всё же договор.
Срезы документов записали в dataframe и сохранили в файл. Было размечено 7500 документов. В результате был получен датасет, содержащий имя файла, его размер, тип и текст документа.
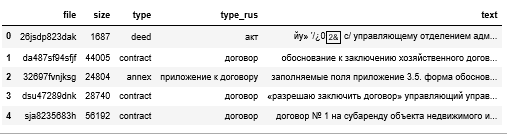
Исходные данные
Документы разделены на 5 классов:
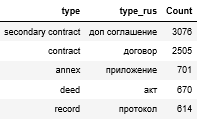
Распределение по классам
Для анализа необходимо произвести предобработку данных. Прежде всего приведем текст к нижнему регистру, а также оставим только буквы русского алфавита (удалим латиницу, цифры, знаки препинания), заменим букву “ё” на “е” для сокращения количества уникальных слов. Избавимся от коротких слов. Используя библиотеку pymorphy2, преобразуем слова в нормальную форму.
morph = pymorphy2.MorphAnalyzer()
def analyser(text):
text = re.sub(r'[^а-яё]+',' ', text)
text = re.sub(r' +',' ', text)
text = text.split(' ')
stopword = stopwords.words(‘russian’)
text = [word for word in text if len(word)>2]
text = [morph.parse(word)[0].normal_form for word in text]
text = [word for word in text if word not in stopword]
return ' '.join(text)
df['text1'] = df['text'].apply(lambda x: str(x))
df['text1'] = df['text1'].apply(lambda x: x.lower())
df['text1'] = df["text1"].str.replace('ё','е')
df['text1'] = df['text1'].apply(lambda x: analyser(x))
df['text1'] = df["text1"].str.replace('инна ','инн ')
Результаты обработки:
Для визуализации частотных характеристик, построим WordCloud общее и для каждой категории.

Теперь подготовим данные к использованию. Преобразуем категориальный признак (type) в числовую форму.
df['type']=df["type"].str.replace(' ','_')
cat_subset=pd.get_dummies(df[['type']])
df=pd.concat([df,cat_subset], axis=1)
df.columns=[re.sub('^type_','',x) for x in df.columns]
Разделим данные на обучающую и тестовую выборки. Соотношение тестовой и тренировочной выборок 30%/ 70%. Так как искусственная нейронная сеть не может работать непосредственно со строками, представим тексты в числовой форме, а затем усечём или дополним входные данные так, чтобы все они были одинаковой длины.
tokenizer=Tokenizer(num_words=15000)
tokenizer.fit_on_texts(list(X_train)
sequence=tokenizer.texts_to_sequences(X_train)
sequence_test=tokenizer.texts_to_sequences(X_test)
xtr=pad_sequences(sequence,maxlen=3000)
x_te=pad_sequences(sequence_test, maxlen=3000)
Теперь реализуем LSTM. Во время обучения, train снова будет разбит на 2 подмножества, одно из которых будет использоваться для обучения, а другая для проверки после каждой эпохи. Для поиска оптимальной модели, стоит поэкспериментировать с параметрами. Для того, чтобы минимизировать вероятность переобучение нейронной сети, предлагаю к использованию метод Dropout, который позволяет выключать нейроны с заданной вероятностью. В качестве оптимизатора будем использовать стохастический вариант оптимизации.
Для реализации будем использовать Keras functional API, основанный на том, что модели глубокого обучения представляют собой DAG (ориентированный ацикличный граф) слоев.
in_node=Input(shape=(3000, )) #определяем входной узел
out_node=Embedding(15000, 128)(in_node)
out_node=LSTM(50, return_sequences=True)(out_node)
out_node=Dense(40, activation='relu')(out_node)
out_node=Dense(5, activation='sigmoid')(out_node)
mod=Model(inputs=in_node, outputs=out_node) #передаем параметры модели как вход и выход
mod.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
mod.fit(xtr,ytr, epochs=5, validation_split=0.20)
Результаты обучения.
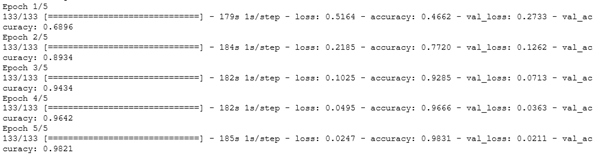
Посмотрим, как изменялись функция потерь и точность в процессе обучения.
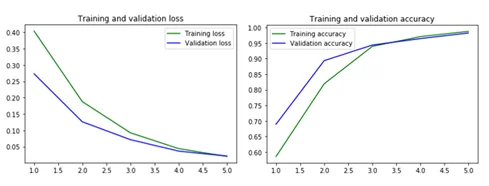
Результат на тестовых данных:

Используя нейронную сеть, удалось значительно сократить трудозатраты на классификацию документов. В дальнейшем можно адаптировать алгоритм для задачи мультиклассовой классификацией.