/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Как говорят нам авторы: “Студия машинного обучения (классическая) — это место, где пересекаются обработка и анализ данных, прогнозная аналитика, облачные ресурсы и данные клиента.”
Стоит отметить, что для разработки моделей прогнозной аналитики как правило используются данные из одного или нескольких источников. Эти данные преобразовываются и анализируются с помощью различных операций и статистических функций. Студия машинного обучения Microsoft Azure создана для того чтобы максимально упростить этот итеративный и долгий процесс. Никакое программирование не требуется. Достаточно выполнить визуальное соединение наборов данных и модулей, чтобы создать модель прогнозной аналитики.
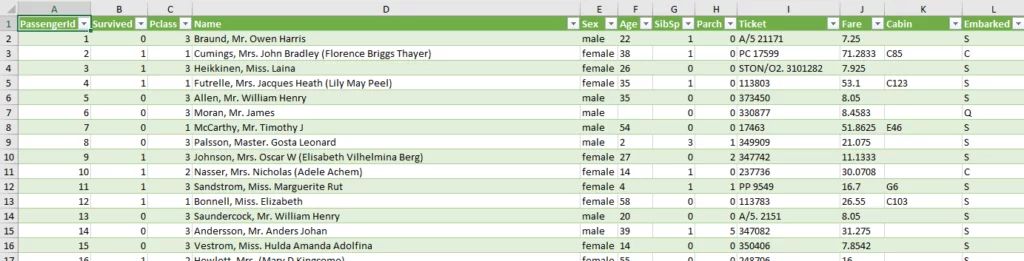
Попробуем создать такую модель, используя данные пассажиров с затонувшего корабля. Данная модель будет прогнозировать возможность спастись с тонущего корабля на основе определенных характеристик пассажира, а также окружающих его обстоятельств.
Данные представляют из себя следующее (из названий столбцов несложно догадаться на какие именно данные мы будем опираться):
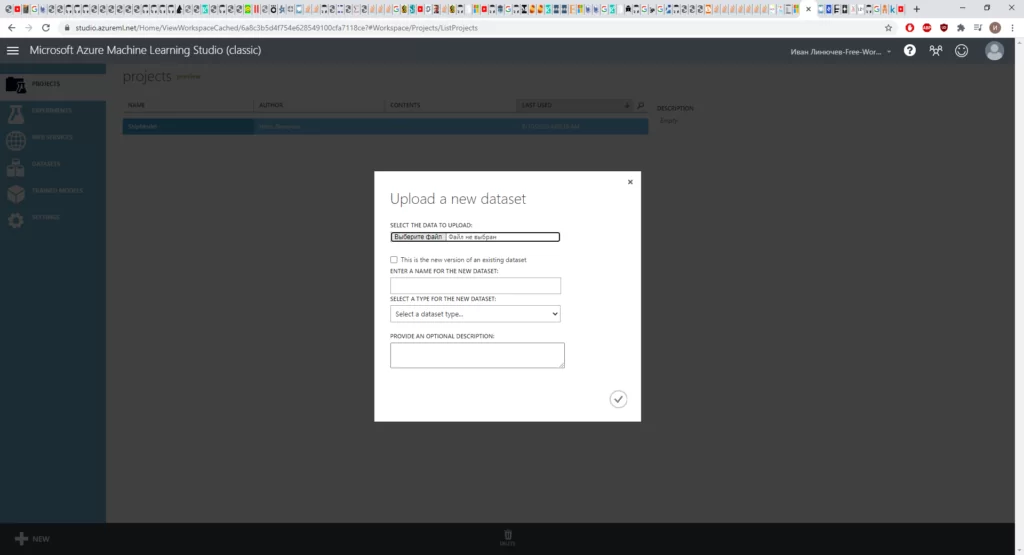
Для начала импортируем данные и разместим их в нашем рабочем пространстве:
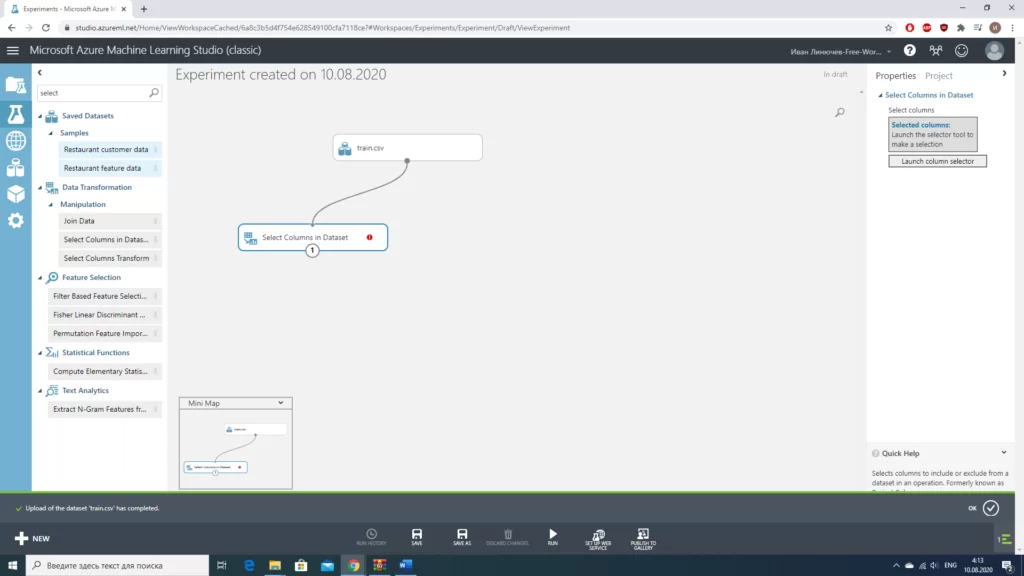
После загрузки данных придется привести некоторые столбцы к соответствующему типу. К примеру столбец «Survived» логично привести к категориальному типу, т.к. возможны значения только 1 и 0(частично живым быть не получится). Столбцы, которые следует отнести к категории категориальных, следующие: Survived, Pclass, Sex и Embarked. Сделать это достаточно просто, достаточно «перетащить» в рабочее пространство необходимый блок и присвоить столбцам нужный тип.
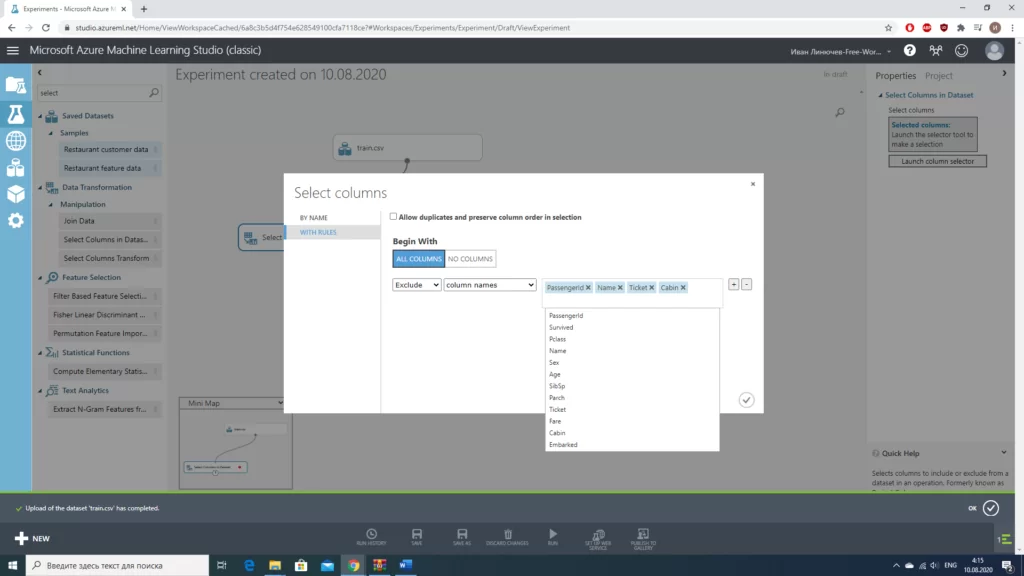
После того, как мы определились с необходимыми данными, неплохо было бы очистить нашу выборку от некорректных значений и заполнить пропуски там, где это возможно.
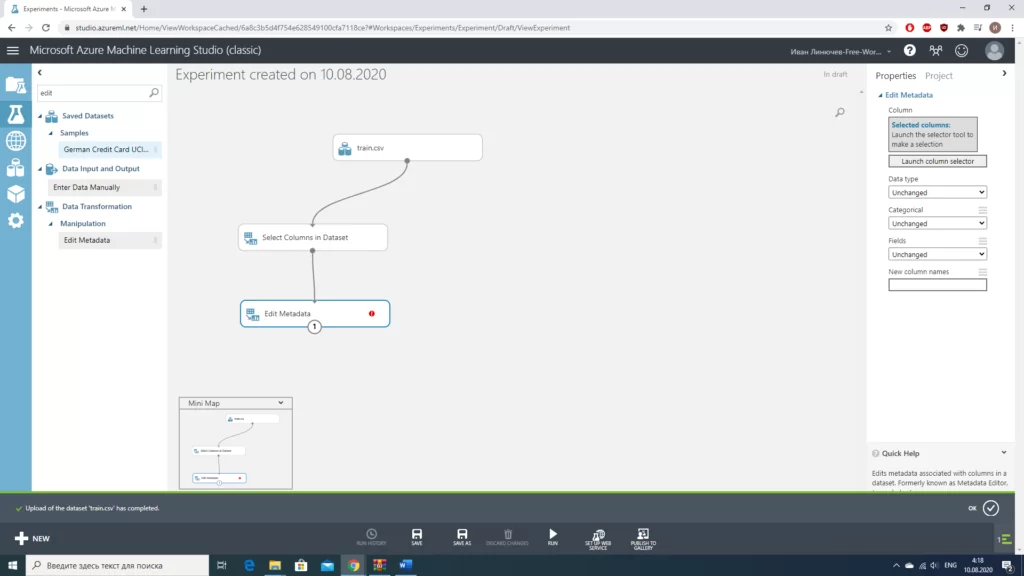
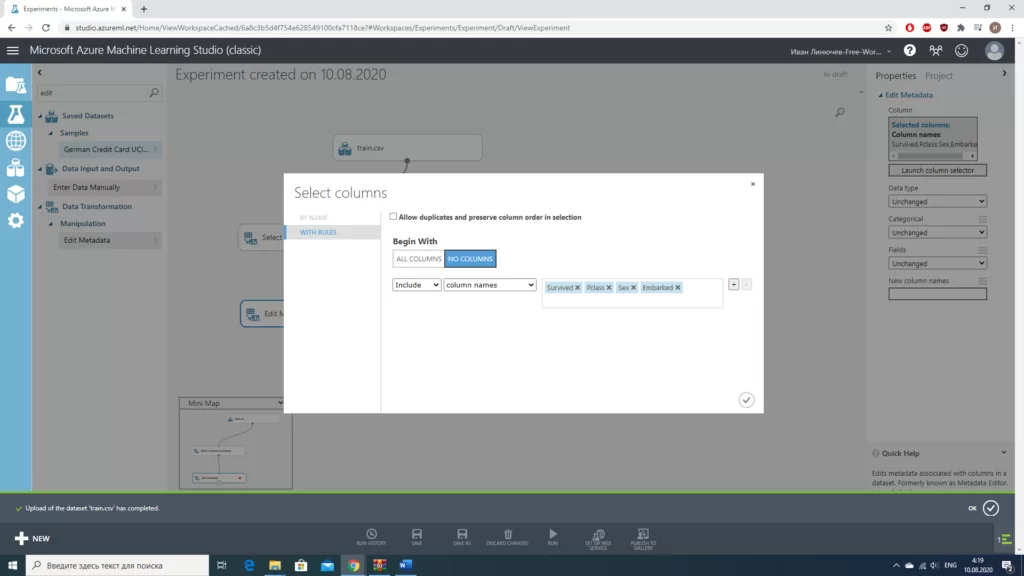
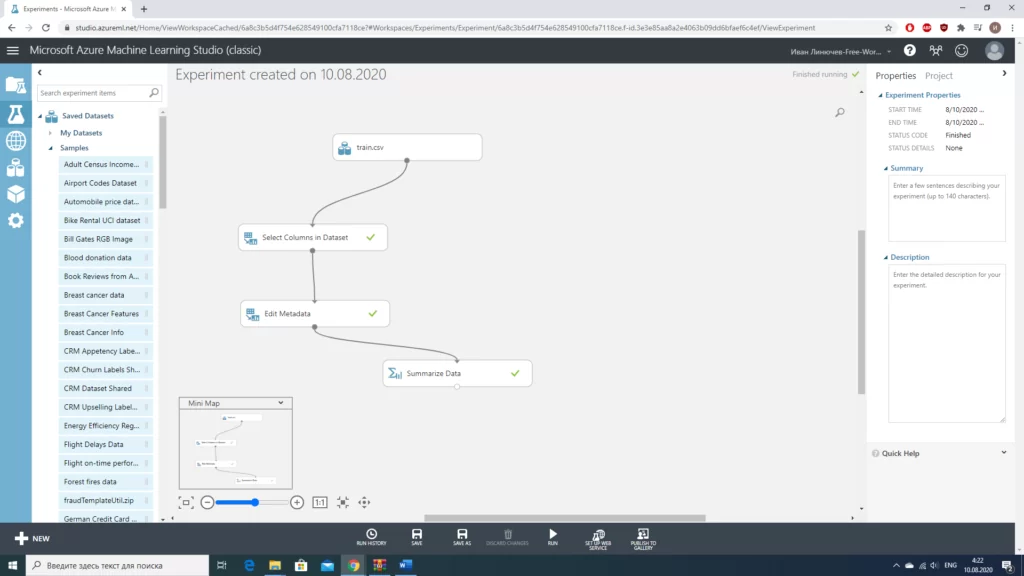
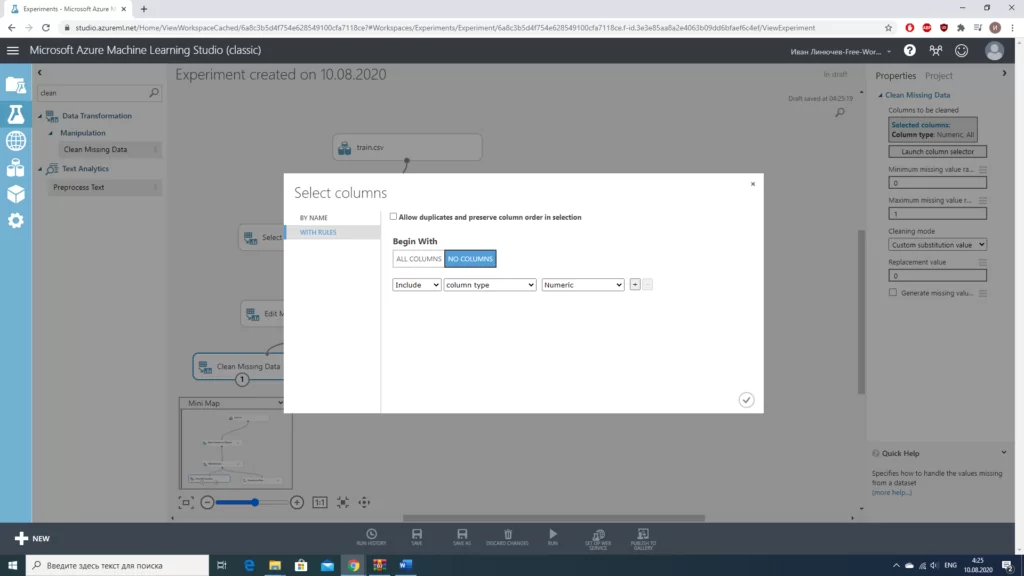
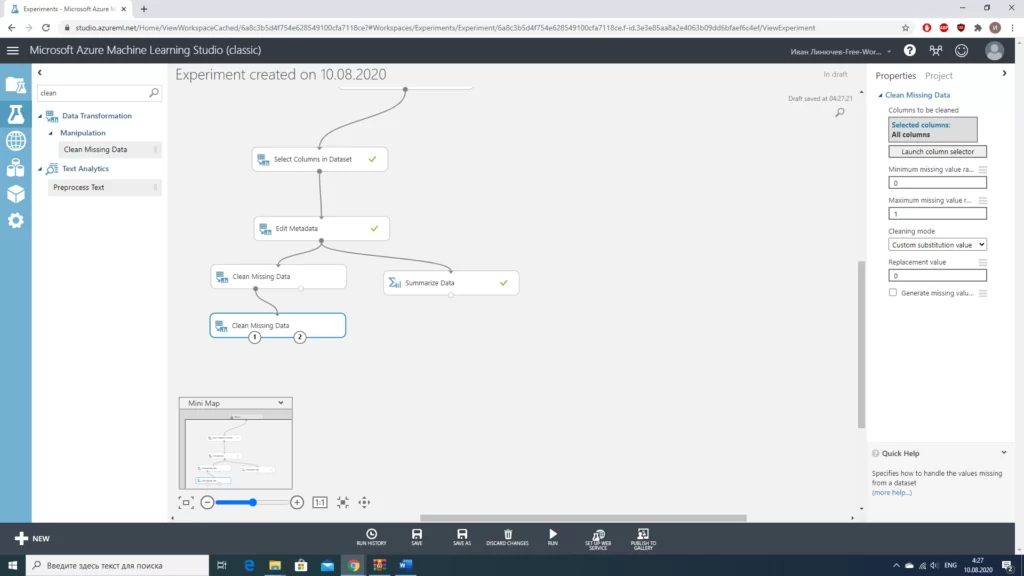
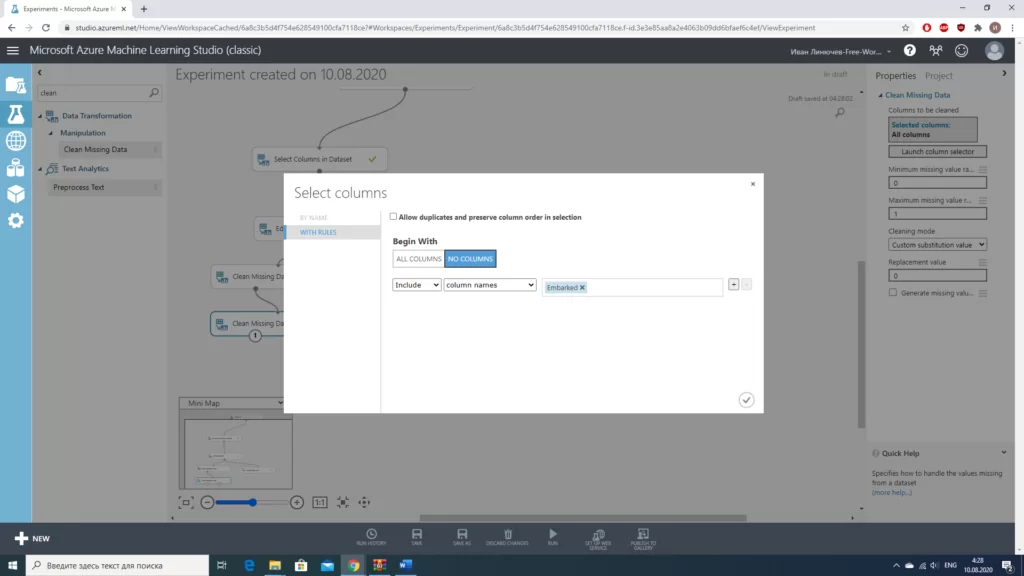
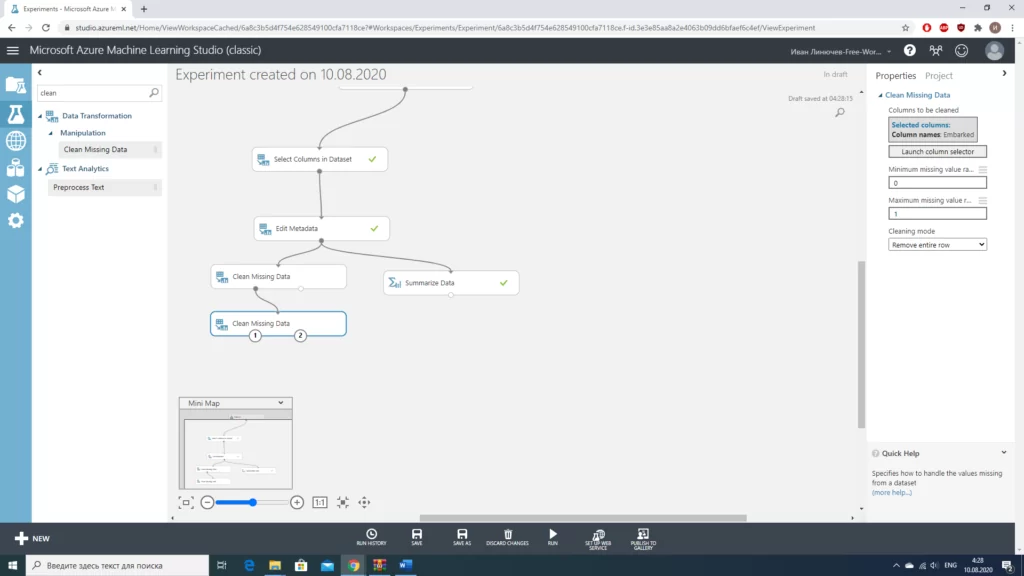
Стоит отметить, что для столбцов «Age» и «Embarked» мы использовали разные значения. В случае с «Age» мы работаем с числовым значением, можем просто заполнить пропуски медианным значением. В случае с «Embarked» намного проще «выбросить» те 2 строки, в которых отсутствуют значения(из общего количества в почти 900 значений это совсем немного). Количество строк с пропусками мы получали, используя блок «Summarize Data».
Теперь наши данные полностью готовы к обучению модели. Перед обучением необходимо выполнить последнее действие – преобразовать атрибут «Survived» в метку.
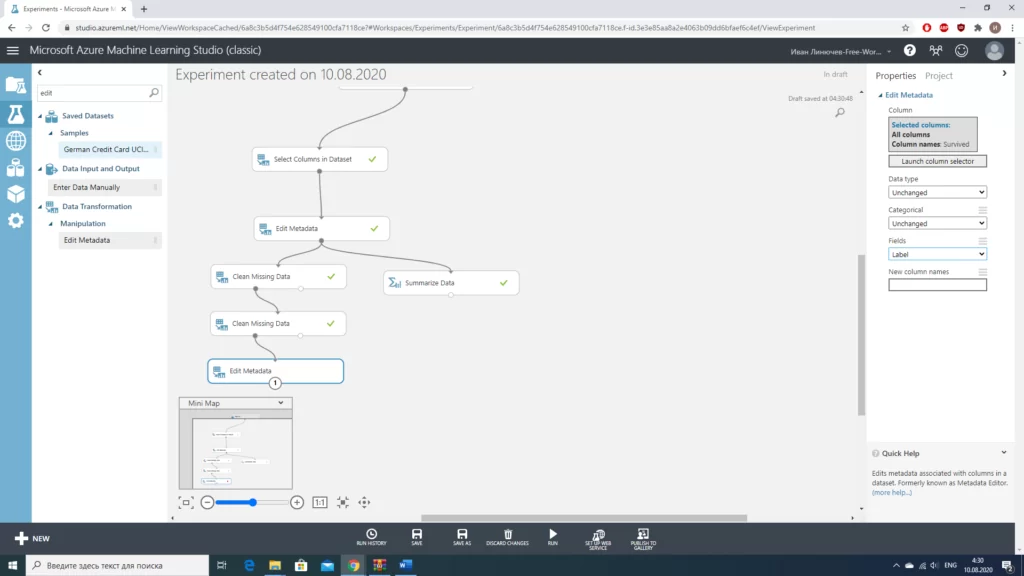
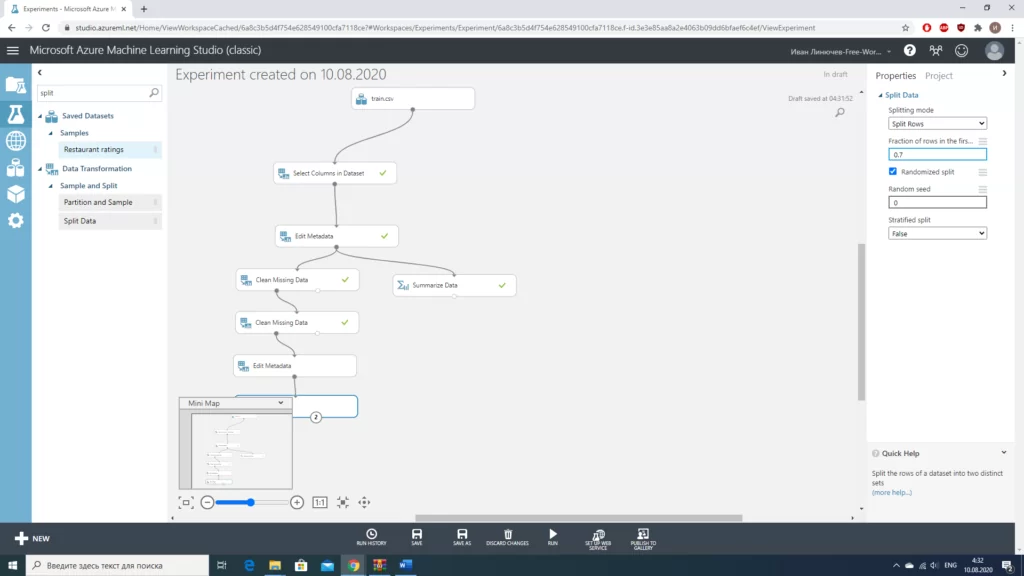
Для того чтобы оценить качество работы модели разделим нашу выборку на 2 части в соотношении 70/30. Для этого можно использовать блок «Split data».
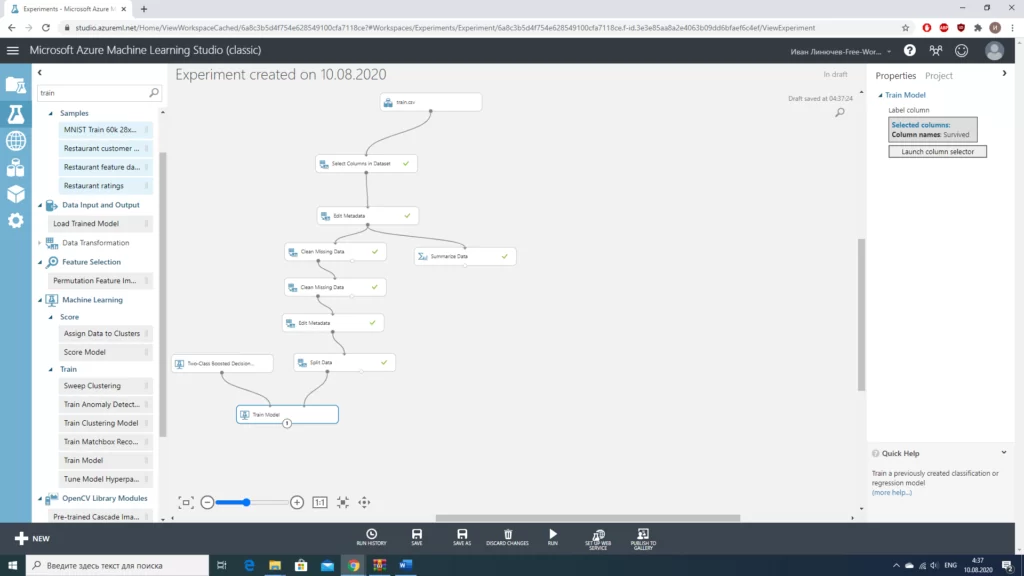
Т.к. в рамках нашей задачи нам необходимо предсказать только два возможных результата «выжил» или «не выжил», подойдет любой из алгоритмов бинарной классификации. Переносим модуль с алгоритмом в рабочее пространство и соединяем его и модуль «Split Data» с модулем «Train Model».
В конце, для оценки модели добавим еще два блока «Score Model», куда войдут данные из модели и «проверочной» выборки, а также модуль «Evaluate Model». После запуска построенной нами последовательности действий получаем следующее:
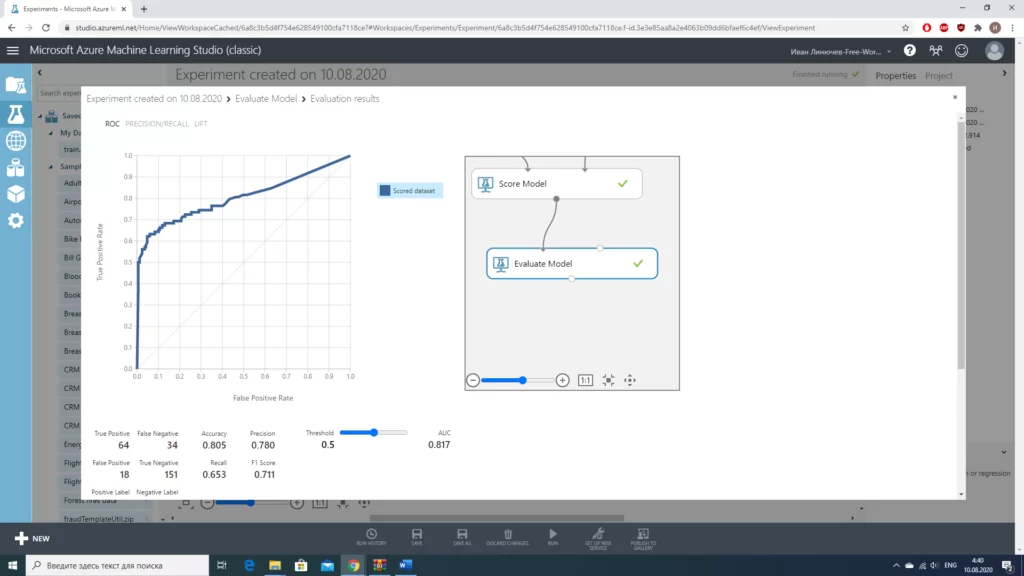
Точность нашей модели получилась больше 0.8, что можно назвать удовлетворительным результатом. Безусловно можно еще немного поработать с параметрами, возможно подобрать другой алгоритм классификации. Но уже и этих результатов достаточно для понимания самого главного -данный инструмент предоставляет достаточно широкий спектр возможностей и может быть крайне полезен для людей, знакомых с аналитикой данных, но не обладающих достаточными навыками в части самостоятельной разработки решений на одном из соответствующих таким задачам языков программирования.