/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Часто в базу надо положить несколько однотипных элементов неизвестного количества. Например, номера телефонов у одного человека, зашифрованные (естественно) номера карт, имена авторов у книги. Этот список можно перечислять бесконечно. Создавать 100 столбцов в таблице с названиями “номер телефона 1” и т.д. — непрактично — слишком много ИТполучится пустых значений в конце таблицы. Поэтому некоторые СУБД реализовали у себя поддержку списков и json. Посмотрим, что это такое и как оно работает.
Массивы
В аудите часто встречаются таблицы, в которых есть клиентская информация и затем начинается полотно: “Номер карты 1”, “Номер карты 2”, “Номер карты 3”. И хорошо, что некоторые банки выпускают ограниченное количество карт на одного человека, но это все-таки неправда — банк не запрещает выпустить клиенту хоть 1000 карт. А на базу данных и дальнейшую обработку аудиторами это ложится неудобным образом.
Массивы поддерживались с самого начала в NoSQL-решениях — это базы данных mongo и другие документо-ориентированные базы данных. К сожалению, такая потребность возникла и в SQL-подобных базах данных.
JSON
Но некоторые СУБД пошли дальше и реализовали возможность обращаться не по индексу к значению (например, найти 5 телефон), а по ключу. То есть, здесь мы работаем уже с именованным массивом, форматом данных JSON. Такой способ взаимодействия будет удобен для данных, у которых поля постоянно изменяются.
Например, для разных документов нужны разные данные. Если у нас база данных с договорами, то у каждого договора своя форма и свои поля для заполнения. И будет удобно посмотреть, с кем мы заключили договоры типа А или какие типы договоров у нас заключены с человеком Х.
PostgreSQL
Самой продвинутой оказалась PostgreSQL. Современная, написана на языке С+, текущая версия 12.2.
Начиная с 9.1 версии появилась поддержка массивов. Выглядит она так:
CREATE TABLE books (
name text,
authors text[] -- или можно указать тип text ARRAY
);Выше приведено создание таблицы с массивом значений авторов. В скобках можно указать максимальное число элементов в массиве.
Теперь разберемся со вставкой строк:
INSERT INTO books
VALUES ('От носорога к единорогу. Как управлять',
'{“Орловский В.”, “Коровкин В.”}');
INSERT INTO books
VALUES ('Искусственный интеллект на практике',
'{“Марр Б.”, “Уорд М.”}');SELECT * FROM books;
name | authors |
--------------------------------------+-------------------------------+
От носорога к единорогу. Как управлять|{“Орловский В.”, “Коровкин В.”}|
Искусственный интеллект на практике |{“Марр Б.”, “Уорд М.”} |
Более того, Postgresql поддерживает двумерные массивы или вообще n-мерные. Просто указывайте скобки [], сколько вам их понадобится. Можно также искать минимальное/максимальное значение в массиве или выводить те строки, у которых среди авторов встречается “Орловский В.”. Это можно сделать следующим образом:
SELECT * FROM users where “Орловский В.” = any(authors);
name | authors |
--------------------------------------+-------------------------------+
От носорога к единорогу. Как управлять|{“Орловский В.”, “Коровкин В.”}|
Теперь работа с JSON. Выше уже говорили, зачем нужен JSON в базах данных, здесь поговорим о реализации. Создание полей с таким типом схоже с созданием массива, за исключением того, что вместо ARRAY пишем JSON. Опишем интересные функции при работе с JSON:
SELECT '{"a":1, "b":2}'::jsonb ? 'b';
TrueМожно узнать есть ли ключ ‘b’ в JSON, можно достать значение по этому ключу, а также можно развернуть JSON в таблицу:
select * from json_each_text('{"a":"foo", "b":"bar"}');
key | value |
-----+-------+
a | foo |
b | bar |Функционал очень большой, формата статьи точно не хватит, поэтому смотрите официальную доку, там все подробно и с примерами.
Teradata
Терадата — параллельная база данных с рождения. Подходит для обработки очень больших объемов данных. Последняя версия — 15.10. Терадата тоже обладает хорошей поддержкой массивов и JSON-типов.
CREATE TYPE shot_ary AS VARRAY(1:50)(1:50) OF INTEGER DEFAULT NULL;
CREATE TABLE seismic_data (
id INTEGER,
shot1 shot_ary,
shot2 shot_ary);
Для Терадаты написанный выше код не будет синтаксической ошибкой. Мы можем создавать массивы как поле таблицы. Также, как и в Постгресе, мы можем создать двумерные и n-мерные массивы.
Что же у Терадаты с JSON? Создание таблицы выглядит так:
CREATE TABLE json_table(id INTEGER, json_j1 JSON);
INSERT INTO json_table(1, '{"name":”Inna”, “age”: 14}');Извлечение информации — вот так:
SELECT json_j1.name
FROM json_tableМожно обращаться к именованному элементу JSON, хранить в значениях ключа массив и обращаться к элементу массива по его индексу.
Все также хорошо, Терадата прекрасно справляется и с JSON.
Остальные нижеприведенные СУБД поддерживают только JSON, по ним кратко посмотрим на примеры кода.
MySQL
Последняя версия — 8.0.19. Еще одна база данных, которая может работать с JSON (поддержка с 5.7.8 версии), но, к сожалению, не с массивами. Это не проблема, так как в JSON мы можем подставить вместо ключа порядковый номер элемента.
Работа с JSON в мускуле тоже не совсем однозначна — у MySQL нет возможности напрямую индексировать документы JSON, но есть альтернатива: генерируемые столбцы.
Пример кода ниже:
CREATE TABLE `players` (
`id` INT UNSIGNED NOT NULL,
`player_and_games` JSON NOT NULL,
PRIMARY KEY (`id`)
);
`names_virtual` VARCHAR(20) GENERATED ALWAYS AS (`player_and_games` ->> '$.name');
ALTER TABLE `players` ADD COLUMN `battlefield_level_virtual` INT GENERATED ALWAYS AS (`player_and_games` ->> '$.games_played.Battlefield.level') NOT NULL AFTER `names_virtual`;
Oracle
СУБД, написанная на Assembly, C, C++. Поддерживает только JSON. Посмотрим на работу с ним:
CREATE TABLE j_purchaseorder
(id RAW (16) NOT NULL,
date_loaded TIMESTAMP WITH TIME ZONE,
po_document CLOB
CONSTRAINT ensure_json CHECK (po_document IS JSON));
INSERT INTO j_purchaseorder
VALUES (SYS_GUID(),
SYSTIMESTAMP,
'{"PONumber" : 1600,
"Reference" : "ABULL-20140421",
"Requestor" : "Alexis Bull",
"User" : "ABULL",
"CostCenter" : "A50",
"ShippingInstructions" : {...},
"Special Instructions" : null,
"AllowPartialShipment" : true,
"LineItems" : [...]}');MS SQL Server
СУБД, разработанная Microsoft на C, C++. Имеет только поддержку JSON, но работа с ним может принести муки, так как обращение к полям структуры не особо очевидное. Пример кода ниже:
SELECT Name, Surname,
JSON_VALUE(jsonCol, '$.info.address.PostCode') AS PostCode,
JSON_VALUE(jsonCol, '$.info.address."Address Line 1"') + ' '
+ JSON_VALUE(jsonCol, '$.info.address."Address Line 2"') AS Address,
JSON_QUERY(jsonCol, '$.info.skills') AS Skills
FROM PeopleИтог
В других СУБД представить поле таблицы как массив или JSON — это синтаксическая ошибка.
Подытожим и объединим информацию в табличный вид:
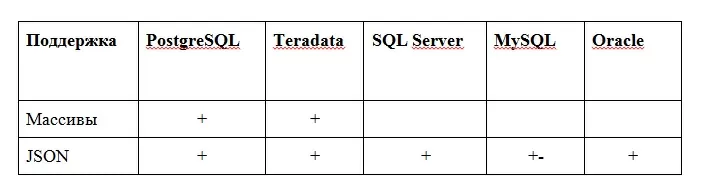
Использование массивов и JSON типов данных очень удобно при определенных условиях. Поэтому при проектировании баз данных подумайте, прежде чем использовать старые знакомые типы полей.