/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Банки получают огромное количество заявок на выдачу кредитных карт. Значимую часть заявок отклоняют по различным причинам, самые простые из которых – наличие высокой долговой нагрузки, низкие доходы и прочее. Ручная обработка таких заявок чревата человеческими ошибками и занимает сравнительно много времени. Методы машинного обучения позволяют в значительной степени автоматизировать эти процессы, и банки активно их применяют. Цель этой статьи – показать, как на базовом уровне методы машинного обучения могут помогать в решении подобных задач.
Почему бы не применять алгоритм, который научится на прошлых данных и решениях, принятых вручную людьми, и будет автоматически одобрять или отклонять заявки? Давайте рассмотрим упрощенный пример построения таких алгоритмов на основе набора данных Credit Approval, предоставленного UCI Machine Learning Repository. В нем содержится информация о заявках на получение кредитных карт. Загрузим и внимательно посмотрим на данные:
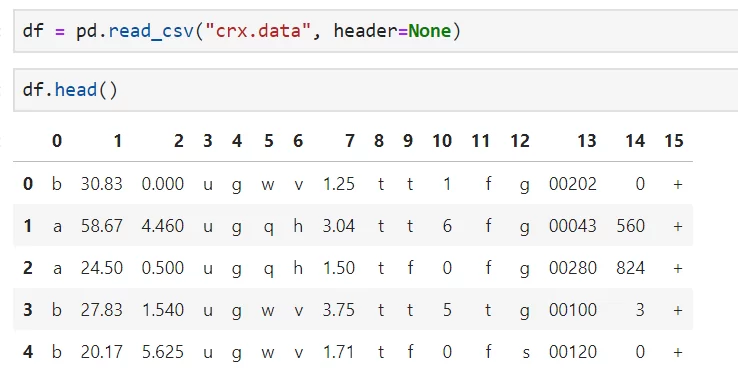
Можно увидеть, что названия признаков были удалены, а их значения изменены авторами, чтобы не нарушать конфиденциальность. Скорее всего, среди признаков присутствуют возраст, пол, доход, семейное положение, образование, данные о прошлых просрочках платежей по кредитам и другие признаки, которые используются в подобных алгоритмах.
Первые 14 столбцов – признаки, а 15 содержит целевую переменную. Метод info() и value_counts() позволяют получить информацию о том, что в данных представлены числовые (int64, float64) и нечисловые признаки (object), 307 заявок было одобрено, 383 – отклонено.
Перед нами стоит задача классификации в чистом виде, так как нужно прогнозировать целевой признак, который принимает ограниченное число значений (2 – одобрение или неодобрение заявки).
Прежде чем перейти непосредственно к обучению моделей необходимо сделать несколько подготовительных шагов:
- при внимательном изучении данных можно обнаружить, что в них присутствуют значения, которые представлены, как «?» – это пропуски в данных. Они присутствуют в столбцах, как с числовыми (1), так и нечисловыми признаками (0, 3-6, 13). От них необходимо избавиться, так как они могут сильно влиять на точность моделей. Для начала заменим все «?» на NaN при помощи метода replace, а далее пропуски в числовых признаках заменим на их средние значения, пропуски в категориальных – на моду;
- нам необходимо преобразовать нечисловые признаки (для этого будем использовать кодировшик OneHotEncoder) и целевую переменную в числовой вид, иначе мы не сможем применять подавляющие число алгоритмов;
- так как многие модели машинного обучения показывают лучшие результаты, когда значения признаков лежат в одинаковых диапазонах, а в исходных данных это не так, то используем MinMaxScaler, которая преобразует значения числовых признаков таким образом, что они будут лежать в диапазоне от 0 до 1.
Для решения этих задач (предварительно отделив категориальные признаки от числовых) мы воспользуемся классами Pipeline и ColumnTransformer из библиотеки SciKit-learn, в последствии передав эти шаги в наши модели.
Разделим нашу выборку на тренировочную (на которой будем обучать модели) и тестовую (на которой будем проверять результаты) при помощи функции train_test_split в соотношении 70/30 и приступим к обучению моделей. Будем использовать следующие алгоритмы: логистическую регрессию, дерево решений, случайный лес и метод опорных векторов. Для базового перебора параметров моделей применим функцию RandomSearchCV, а потом на лучших параметрах будем проверять модель.
Важно минимизировать и число невыданных карт тем, кому их стоило бы выдать (иначе банк недополучит прибыль) и число выданных карт тем, кому их нельзя было выдавать (иначе возрастет риск убытков). Поэтому за метрику качества моделей примем F-меру, которая представляет собой гармоническое среднее между точностью (соотношением корректных прогнозов модели к общему числу позиций в выборке) и полнотой (соотношением верно классифицированных положительных позиций – «кредитная карта выдана» ко всем верно классифицированным позициям). Рассмотрим код на примере логистической регрессии:
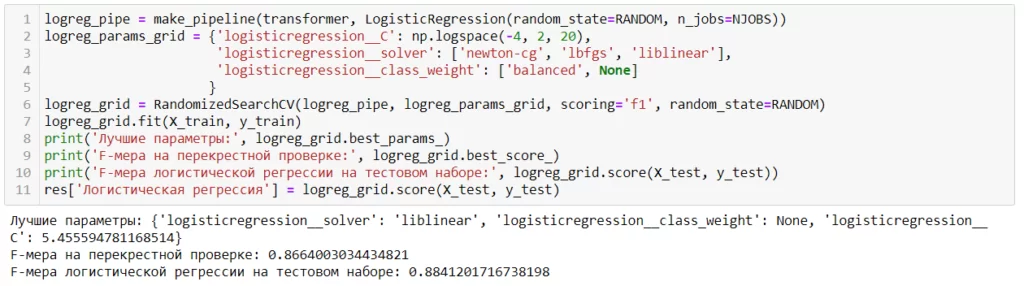
После обучения всех моделей, получаем следующие F-меры для каждой из них:

Лучшее качество мы получили, используя логистическую регрессию (F-мера – 0,88), а сравнительно худшая модель – дерево решений с F-мерой 0,85. Можно посмотреть, как выглядит матрица ошибок нашей лучшей модели, чтобы понять сколько и как она ошибалась:

Модель одобрила 77 заявок, которые надо было одобрить и отклонила 103 заявки, которые должно были быть отклонены. Но есть и ошибки: 11 заявок модель ошибочно отклонила, а 16 – ошибочно одобрила. Таким образом, модели на основе входных данных научились обобщать решения людей и на таких же принципах уже на новых данных принимать самостоятельные решения с некоторой погрешностью. Это, конечно не идеальный результат, но для базовой реализации алгоритмов – хорошая отправная точка. При наличии большего объема исходных данных и интерпретируемых признаков можно продолжать работу по повышению качества и довести ее до оптимального результата. Специалистам нашего маленького воображаемого банка не надо будет тратить время на ручной скоринг, и они смогут направить силы на другие не менее важные задачи.
Теперь давайте вообразим ситуацию, в которой мы доработали наш алгоритм и внедрили его идеальную реализацию в скоринговые процессы банка. Является ли это волшебной таблеткой, которая повысит скорость принятия решений, их качество и снизит сопутствующие риски, не имея никаких отрицательных сторон? Конечно, нет и вот почему:
- Сложные алгоритмы бывают очень трудноинтерпретируемые. Мы можем видеть результаты работы конкретных моделей, но способ получения результата может быть недоступен. Ситуация, в которой бизнес не может в полной мере объяснить регуляторам и клиентам то, как именно принимаются решения, является неоднозначной. Данный процесс еще только предстоит формализовать с технологической и юридической точки зрения.
- Для построения качественных моделей, как правило, требуются большие массивы актуальных и достоверных данных (в нашем случае – это персональные данные о клиентах). Вопросы, связанные с получением, хранением и защитой данных затрагивают не только технологическую, но и этическую сторону. Границы комфортной людям прозрачности в современном обществе еще окончательно не сформировались. Насколько людям принадлежит информация, которая генерируется в огромных количествах и как они могут ею распоряжаться (в том числе ограничивать к ней доступ) еще только предстоит решить.
- Человеческие решения не идеальны, нередко предвзяты и ошибочны. В нашем случае модели обучались на решениях, которые были приняты людьми, поэтому модели так же перенесут в себя все эти недостатки и будут их воспроизводить из раза в раз. С учетом отсутствия возможности в полной мере интерпретировать логику принятия алгоритмом решений, мы даже не сможем понять, насколько накопленные искажения в принятии решений влияют на результат, критичны ли они и как от них избавиться.
Несмотря на эти недостатки, технологии машинного обучения уже сейчас чрезвычайно помогают повышать эффективность многих бизнес-процессов. Их внедрение с учетом здравого понимание возможностей и ограничений позволит получить не только конкурентные преимущества, но и сильно улучшить клиентский опыт.
С полным кодом вы можете ознакомиться на GitHub.