/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Искусственный интеллект, самообучаемые модели, градиентный бустинг… Данные слова все чаще звучат в нашем окружении, но, в большинстве случаев, простому обывателю разобраться в этом крайне сложно. 80% статей по машинному обучению либо содержат огромное количество научных слов, которые никому не понятны, либо истории, которые больше похожи на выдуманные рассказы.
Давайте попробуем разобраться и рассказать простым языком то, что приходится изучать годами, без формул и с реальными примерами. Поехали?
Что значит машинное обучение?
Предположим, что вы хотите купить себе квартиру. Проанализировав рынок, вы видите, что новые квартиры стоят 3 млн, 2-х летние стоят уже 4 млн, а 5 летние — под 4 млн, и так далее.
Исходя из имеющихся данных, вы сделали расчет в уме – квартиры на этапе строительства стоят дешевле, а затем дорожают на определенную сумму каждый год, пока не дойдет до какой-то определенной суммы – допустим, это 6 млн рублей.
Перед вами стандартный пример регрессии – предсказание целевой переменной по известным данным. Мы постоянно делаем эту работу, например, когда хотим продать что-нибудь ненужное на сайтах объявлений – анализируем цены на схожие товары и формируем то значение, которое считаем адекватным.
Универсальной формулы расчета, к сожалению, не существует, потому что мы должны учитывать огромное количество факторов, влияющих на цену, таких как: площадь квартиры, район, количество комнат, год постройки дома. И, благодаря математике, компьютер может находить закономерности, которые позволяют предсказывать искомое значение. Это и называется машинным обучением.
Цели машинного обучения
Основная цель машинного обучения – предсказать целевую переменную, основываясь на полученных данных.
Какие данные нам нужны? Все, что нужно – это примеры того, что мы хотим получить. Пример – хотим рассчитать стоимость акций – нужны данные по стоимости акций, нужны стоимости машин – берем историю продаж машины. Чем больше данных мы сможем собрать – тем лучше. На малых объемах данных обучить машину проблематично, и полученные результаты могут быть неточными.
Данные можно собирать автоматизировано, а можно — вручную. Набор данных называется датасетом. Хорошие датасеты всегда идут на вес золота, так как на препроцессинг (подготовку данных) может уходить много времени и сил. К слову – когда где-то на просторах интернета вас просят на картинке отметить светофоры, это один из примеров, когда вы помогаете размечать датасет и, кстати, делаете это совершенно бесплатно. 😊 Так же существуют сервисы по типу Яндекс.Толока, где можно за деньги отдать ваши данные, а армия работников за небольшую плату сделает за вас всю работу, а на выходе вы получите готовый размеченный датасет.
После сбора данных, мы должны явно указать машине, на какие отличительные свойства ей нужно смотреть. Эти свойства называют фичами (от англ. Features ). Далее называть их будем только так. Что является фичей – вернемся к квартирам – это может быть вид покрытия на полу, размер ванной, и даже количество раз, когда менялись владельцы соседних квартир может быть нужной фичей.
Чаще всего отбор нужных фичей занимает большую часть времени, чем остальное обучение. Отбор правильных фичей напрямую влияет на результат, и, если вы выберете на ваш субъективный взгляд «правильные» фичи, может получиться так, что ваша модель начнет давать ложные результаты.
Основные виды машинного обучения:
Всего здесь выделено 4 вида машинного обучения. Они, довольно-таки, условные, на самом деле классификация насчитывает больше разделов, но для базового понимания будет достаточно того, что приведено ниже.
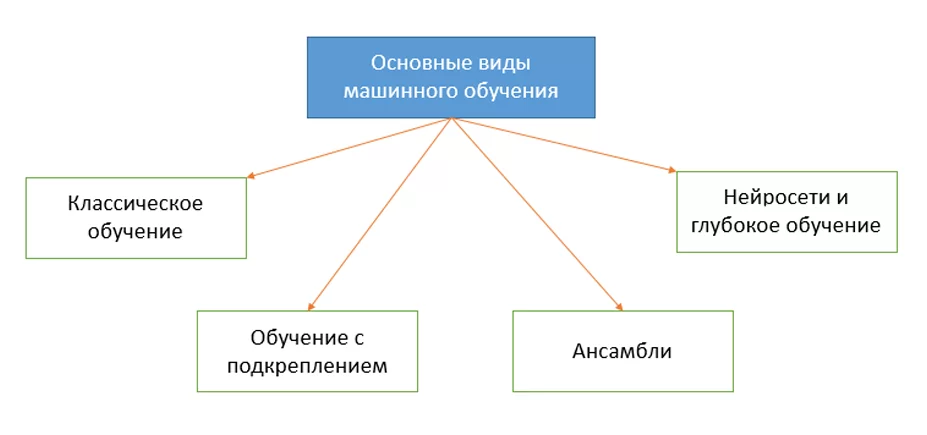
В нашем цикле статей мы постараемся разобраться во всех видах МО, но в сегодняшней статье мы разберем первый элемент схемы – классическое обучение и основную его концепцию – обучение с учителем.
Классическое обучение с учителем
Само название параграфа уже говорит о себе – человек является учителем для машины. Условно говорит ей как ребенку: это правильно, а это неправильно. Если машину обучают для разметки фотографий, учитель заранее говорит ей – здесь автомобиль, а здесь пешеход. И машина учится на конкретных примерах. Этот вид обучения так же называется Supervised Learning.
Прямая противоположность данному методу – Unsupervised Learning. Это когда машине дают кучу картинок, и она сама должна разобраться и найти закономерности, по которым будет проходить классификация. Как работает данный метод мы поговорим позже, в следующих статьях.
Сделаем вывод – обучение с учителем быстрее и точнее, поэтому в большинстве задач его используют чаще. Supervised Learning делится на два типа задач: классификация – разделение объектов по категориям и регрессия – предсказание целевой переменной.
Итак, в первой части статьи мы познакомились только с малой частью понятий машинного обучения. Этого явно недостаточно чтобы стать дата-саентистом уже завтра, но у вас еще все впереди! В следующий раз мы рассмотрим детально – что такое классификация и регрессия, и, возможно, захватим еще Unsupervised Learning. До скорой встречи!