/img/star (2).png.webp)



/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Приветствуем вас, дорогие читатели! Далеко не секрет, что в настоящее время наиболее часто для целей машинного обучения используется язык программирования Python поскольку для него разработано большое количество инструментов, предоставляющих ML-функционал. И даже, если разработчик привык писать на другом языке программирования, то при возникновении задачи, связанной с машинным обучением, с высокой долей вероятности он примет решение в пользу Python.
Но что, если вы- заядлый программист C++ и переходить на другой язык нет никакого желания, либо вы ищете новые инструменты, новые подходы для решения задачи?
Выход есть, и это C++ библиотека для машинного обучения Shark. Но прежде, чем начать пользоваться «акулой», её нужно установить. Опишем этот процесс, упоминая важные моменты, поскольку у кого-то с этим могут возникнуть трудности (для ОС Windows, Visual Studio 17).
Установка.
Со страницы руководства по установке Shark, размещённой на официальном сайте, скачиваем архив с исходниками Shark и распаковываем его в удобное место. Функционал Shark во многом опирается на другой известный набор C++ библиотек Boost. Переходим по ссылке, расположенной на той же странице, и скачиваем архив с файлами Boost, который затем распаковываем (например, по пути «C:\Program Files\boost»). Открываем консоль, переходим в корневую директорию boost и вводим «bootstrap». После выполнения команды вводим команду «.\b2», ожидаем её завершения. На этом сборка библиотек Boost закончена.
Устанавливаем CMake, открываем cmake-gui и проводим следующие действия:
- в поле «Where is the source code» указываем путь к распакованным исходникам Shark;
- в поле «Where to build the directory» указываем путь, где хотим разместить файлы проекта (сборки) Shark (это не ваш проект по ML!);
- нажимаем на «Add Entry», вводим имя «BOOST_ROOT», выбираем тип «PATH» и указываем расположение корневой директории boost (например, «C:\Program Files\boost\boost_1_66_0»);
- нажимаем на «Add Entry», вводим имя «BOOST_LIBRARYDIR», также выбираем тип «PATH» и указываем расположение директории библиотек boost (например, «C:\Program Files\boost\boost_1_66_0\libs»).
Окно Cmake будет выглядеть примерно так:
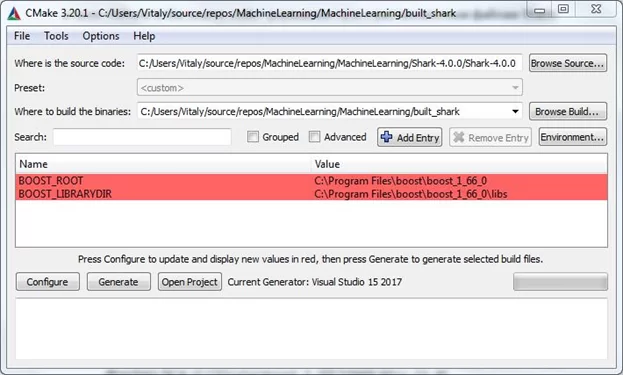
Теперь нажимаем «Configure», выбираем компилятор и нажимаем «Finish». На этом этапе, скорее всего, у вас возникнет ошибка. В нашем случае помогла установка значения «True» для «Boost_USE_STATIC_LIBS»:
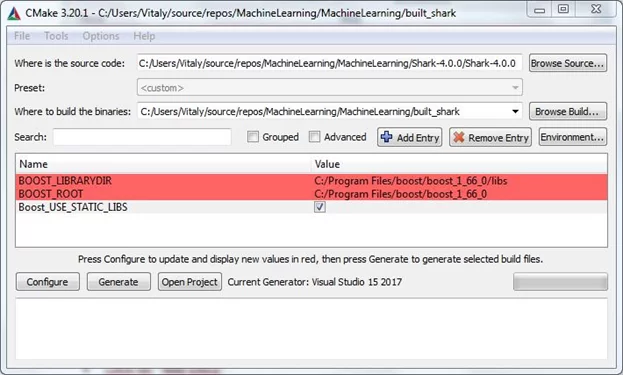
Нажимаем «Generate», после чего сборка будет завершена. Но это ещё не всё. Переходим в директорию со сборкой Shark, открываем файл shark.sln, нажимаем «Сборка» -> «Пересобрать решение» и ожидаем завершения. В результате в директории появится папка lib, которая понадобится нам в дальнейшем. Мы всё ближе к цели!
Теперь создаём проект простого консольного приложения в Visual Studio. В обозревателе решений переходим в свойства проекта, переходим во вкладку «C/C++» -> «Общие» и в поле «Дополнительные каталоги включаемых файлов» добавляем путь к корневой директории boost, путь к папке «include», находящейся в директории со сборкой shark (например, «C:\Users\User\Project\built_shark\include») и путь к папке «include», находящейся в директории с исходниками Shark (например, «C:\Users\User\Project\Shark-4.0.0\Shark-4.0.0\include»).
Теперь переходим во вкладку «Компоновщик» -> «Общие», в поле «Дополнительные каталоги библиотек» добавляем путь с библиотеками Boost (например, «C:\Program Files\boost\boost_1_66_0\stage\lib»). Наконец, в той же вкладке переходим в «Ввод» и в поле «Дополнительные зависимости» добавляем путь к скомпилированной во время сборки Shark библиотеке «shark_debug.lib»:
«C:\Users\User\Project\built_shark\lib\Debug\shark_debug.lib»Применение.
Теперь мы готовы писать нашу программу по машинному обучению на C++! Для общего понимания принципов работы с Shark приведём ниже в качестве примера небольшой код, в котором будем использовать алгоритм Random Forest (Случайный Лес) для задачи классификации. Сначала делаем необходимые включения:
#include "stdafx.h"
#include <iostream>
#include <shark/Data/Csv.h>
#include <shark/Algorithms/Trainers/RFTrainer.h>
#include <shark/ObjectiveFunctions/Loss/ZeroOneLoss.h>
Далее продолжаем в теле функции main(). Объявляем переменную, в которую загрузим размеченный csv файл с датасетом для обучения:
shark::ClassificationDataset dataSet;
shark::importCSV(dataSet, "heavy_data.csv", shark::LAST_COLUMN, ';');
Параметру lp мы передали аргумент LAST_COLUMN, это означает, что целевая переменная расположена в последнем столбце датасета. Если указать FIRST_COLUMN – это будет соответствовать первому столбцу.
Теперь нам нужно разделить датасет на тренировочную и обучающую выборки. Но для начала перемешиваем датасет случайным образом, потому что функция splitAtElement только делит датасет, привязываясь к номеру строки, и возвращает «правую» половину, которую мы считаем тестовой выборкой. Делим в соотношении 67% — тренировочная, 33% — тестовая:
dataSet.shuffle();
shark::ClassificationDataset dataTest = shark::splitAtElement(dataSet, static_cast<std::size_t>(0.67*dataSet.numberOfElements()));
Создаём объект trainer класса RFTrainer. Здесь мы можем изменить количество деревьев, максимальную глубину и другие параметры:
shark::RFTrainer<unsigned int> trainer;
trainer.setNTrees(100);
trainer.setMaxDepth(500);
Создаём объект модели и проводим обучение:
shark::RFClassifier<unsigned int> model;
trainer.train(model, dataSet);
После завершения обучения мы можем «прогнать» через модель тестовую выборку и проверить, насколько хорошо обучилась модель:
shark::ZeroOneLoss<> loss;
shark::Data<unsigned int> predictionData;
predictionData = model(dataTest.inputs());
std::cout << "Random Forest prediction accuracy: " << 1. - loss.eval(dataTest.labels(), predictionData) << std::endl;
Есть к чему стремиться! Но это пример на довольно сырых данных. Библиотека Shark включает в себя все основные алгоритмы для регрессии, классификации, кластеризации, функции для обработки датасетов и даже позволяет проводить глубокое обучение нейронных сетей. Всё это можно изучить на официальном сайте библиотеки. К слову, библиотека компьютерного зрения Open CV так же предоставляет некоторый функционал машинного обучения, что можно использовать при написании программы на C++, но Shark в этой области предлагает больше.
Что касается установки, то возможно, вы знаете более лёгкий способ. Пишите об этом в комментариях, будем рады.
Надеемся, что для кого-то изложенная информация будет полезной. Ставьте лайки, спасибо за внимание!