/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Датасет
Датасет можно скачать по ссылке.
Для обучения в датасете есть 4 подкласса.
- real — «живое» лицо
- replay — кадры с видео
- printed — распечатанная фотография
- 2dmask — надетая 2d маска
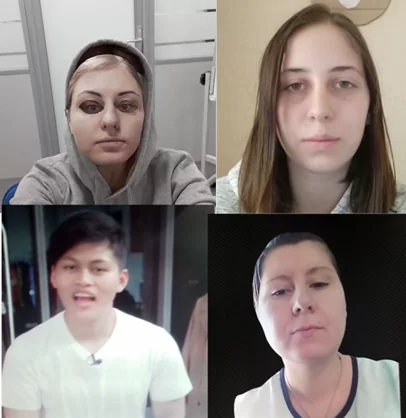
Каждый образец представлен последовательностью из 5 картинок.
Строим модель
Для решения задачи классификации изображений на принадлежность «живому» пользователю будем обучать нейронную сеть, используя фреймворк pytorch.
Решение строится на работе с последовательностью картинок, а не с каждой картинкой отдельно. Используем небольшую претренированную сеть Resnet18 на каждую картинку из последовательности. Затем стакаем полученные фичи и применяем 1d свертку и далее fully connected слой на 1 класс.
Таким образом, наша архитектура выглядит следующим образом:
class Empty(nn.Module):
def __init__(self):
super(Empty, self).__init__()
def forward(self, x):
return x
class SpoofModel(nn.Module):
def __init__(self):
super(SpoofModel, self).__init__()
self.encoder = torchvision.models.resnet18()
self.encoder.fc = Empty()
self.conv1d = nn.Conv1d(
in_channels=5,
out_channels=1,
kernel_size=(3),
stride=(2),
padding=(1))
self.fc = nn.Linear(in_features=256, out_features=1)
def forward(self, x):
vectors = []
for i in range(0, x.shape[1]):
v = self.encoder(x[:, i])
v = v.reshape(v.size(0), -1)
vectors.append(v)
vectors = torch.stack(vectors)
vectors = vectors.permute((1, 0, 2))
vectors = self.conv1d(vectors)
x = self.fc(vectors)
return x
Для примера мы будем тренировать нашу модель 5 эпох с батч сайзов 64, что займёт примерно 1 час с учетом валидации на одной 2080TI.
На валидации смотрим 3 метрики: f1, accuracy и f2 score.
Код для валидации:
def eval_metrics(outputs, labels, threshold=0.5):
return {
'f1': f1_score(y_true=labels, y_pred=(outputs > threshold).astype(int), average='macro'),
'accuracy': accuracy_score(y_true=labels, y_pred=(outputs > threshold).astype(int)),
'fbeta 2': fbeta_score(labels, y_pred=(outputs > threshold).astype(int), beta=2, average='weighted'),
'f1 weighted': f1_score(y_true=labels, y_pred=(outputs > threshold).astype(int), average='weighted')
}
def validation(model, val_loader):
model.eval()
metrics = []
batch_size = val_loader.batch_size
tq = tqdm(total=len(val_loader) * batch_size, position=0, leave=True)
with torch.no_grad():
for i, (inputs, labels) in enumerate(val_loader):
inputs = inputs.cuda()
labels = labels.cuda()
outputs = model(inputs).view(-1)
tq.update(batch_size)
metrics.append(eval_metrics(outputs.cpu().numpy(), labels.cpu().numpy()))
metrics_mean = mean_metrics(metrics)
tq.close()
return metrics_mean
В качестве оптимайзера используем SGD c learning rate = 0.001, а в качестве loss BCEWithLogitsLoss.
Не будем использовать экзотических аугментаций. Делаем только Resize и RandomHorizontalFlip для изображений при обучении.
Полный код функции для тренировки:
def train():
path_data = 'data/'
checkpoints_path = 'model'
num_epochs = 5
batch_size = 64
val_batch_size = 32
lr = 0.001
weight_decay = 0.0000001
model = SpoofModel()
model.train()
model = model.cuda()
epoch = 0
if os.path.exists(os.path.join(checkpoints_path, 'model_.pt')):
epoch, model = load_model(model, os.path.join(checkpoints_path, 'model_.pt'))
optimizer = torch.optim.SGD(model.parameters(), lr=lr, weight_decay=weight_decay)
criterion = torch.nn.BCEWithLogitsLoss()
path_images = []
for label in ['2dmask', 'real', 'printed', 'replay']:
videos = os.listdir(os.path.join(path_data, label))
for video in videos:
path_images.append({
'path': os.path.join(path_data, label, video),
'label': int(label != 'real'),
})
split_on = int(len(path_images) * 0.7)
train_paths = path_images[:split_on]
val_paths = path_images[split_on:]
train_transform = torchvision.transforms.Compose([
torchvision.transforms.ToPILImage(),
torchvision.transforms.Resize(224),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
val_transform = torchvision.transforms.Compose([
torchvision.transforms.ToPILImage(),
torchvision.transforms.Resize(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
train_dataset = AntispoofDataset(paths=train_paths, transform=train_transform)
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=8,
drop_last=True)
val_dataset = AntispoofDataset(paths=val_paths, transform=val_transform)
val_loader = DataLoader(dataset=val_dataset,
batch_size=val_batch_size,
shuffle=True,
num_workers=8,
drop_last=False)
tq = None
try:
for epoch in range(epoch, num_epochs):
tq = tqdm(total=len(train_loader) * batch_size, position=0, leave=True)
tq.set_description(f'Epoch {epoch}, lr {lr}')
losses = []
for inputs, labels in train_loader:
inputs = inputs.cuda()
labels = labels.cuda()
optimizer.zero_grad()
with torch.set_grad_enabled(True):
outputs = model(inputs)
loss = criterion(outputs.view(-1), labels.float())
loss.backward()
optimizer.step()
optimizer.zero_grad()
tq.update(batch_size)
losses.append(loss.item())
intermediate_mean_loss = np.mean(losses[-10:])
tq.set_postfix(loss='{:.5f}'.format(intermediate_mean_loss))
epoch_loss = np.mean(losses)
epoch_metrics = validation(model, val_loader=val_loader)
tq.close()
print('\nLoss: {:.4f}\t Metrics: {}'.format(epoch_loss, epoch_metrics))
save_model(model, epoch, checkpoints_path, name_postfix=f'e{epoch}')
except KeyboardInterrupt:
tq.close()
print('\nCtrl+C, saving model...')
save_model(model, epoch, checkpoints_path)
Итоговый ход тренировки выглядит так:
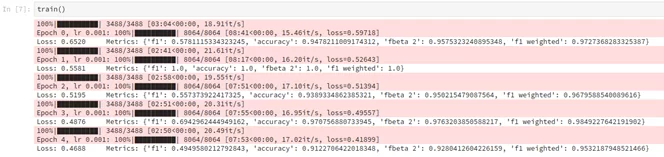
В качестве модели для проверки используем веса с 3 эпохи.
Для проверки у нас есть 10 примеров. Построим confusion matrix:
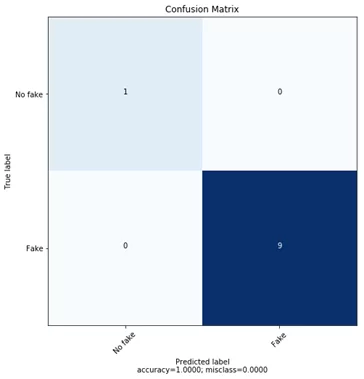
На 10 примерах мы достигли 100% точности. Конечно, для идеальной проверки модели требуется данных значительно больше.
Таким образом, в своей статье я предложил один из вариантов реализации liveness detection с помощью классификации изображений нейронной сетью. Полный код размещен по ссылке
Канал автора статьи в Telegramm