/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
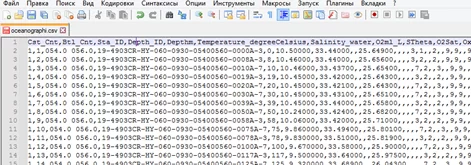
В качестве данных будет использован data set океанографических исследований, насчитывающий более 800 тыс. строк. Фрагмент csv-файла показан на рисунке ниже. Из атрибутов будут выбраны данные об уровне солености воды и температуре воды.
Импортируем необходимые библиотеки (для примера используется Jupyter Notebook):
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn import preprocessing, svm
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
Затем выполним чтение данных из файла oceanographi.csv и сформируем Data Frame:
# Формируем Data Frame из csv файла
df = pd.read_csv('C:/Users/User/oceanographi.csv')
# Используем только необходимые атрибуты из Data Frame
df_bin = df[["Salinity_water", "Temperature_degreeCelsius"]]
# Переименование столбцов в удобный вид
df_bin.columns = ["Salinity", "Temperature"]
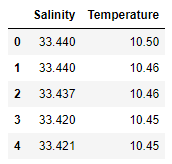
# Выведем на экран первые строки DataFrame
df_bin.head()
Результат работы этого кода:
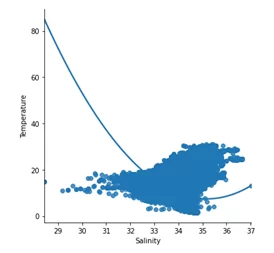
Давайте теперь посмотрим на имеющийся разброс данных:
# Построение графа разброса данных
sns.lmplot(x ="Salinity", y ="Temperature", data = df_bin, order = 2, ci = None)
Граф разброса имеющихся данных выглядит следующим образом:
Следующим шагом выполним очистку данных от значений NaN или отсутствующих значений.
# Удаление NaN или отсутствующих числовых значений
df_bin.fillna(method ="ffill", inplace = True)
Теперь проводим обучение модели данных:
# Разделение данных на независимые и зависимые переменные
# Преобразование DataFrame в массив numpy
X = np.array(df_bin["Salinity"]).reshape(-1, 1)
y = np.array(df_bin["Temperature"]).reshape(-1, 1)
# Удаление любых строк со значениями NaN
df_bin.dropna(inplace = True)
# Разделение данных на данные для обучения и тестирования
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25)
regr = LinearRegression()
regr.fit(X_train, y_train)
print(regr.score(X_test, y_test))
Вывод результата:

Посмотрим на разброс прогнозируемых значений данных — получим граф, выполнив следующий код:
y_pred = regr.predict(X_test)
plt.scatter(X_test, y_test, color ='b')
plt.plot(X_test, y_pred, color ='k')
plt.show()
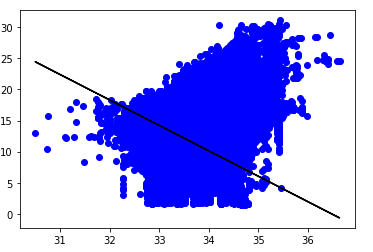
Невысокий показатель точности созданной модели означает, что регрессивная модель плохо соответствует имеющимся данным. Иными словами, данные не подходят для линейной регрессии. Далее рассмотрим только небольшую часть данных – 300 первых строк.
# Выбор первых 300 строк данных
df_bin300 = df_bin[:][:300]
sns.lmplot(x ="Salinity", y ="Temperature", data = df_bin300,
order = 2, ci = None)
Результат работы этого кода представлен на рисунке ниже:
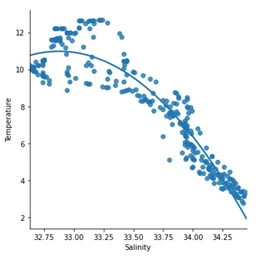
Как видно из этого графа, первые 300 строк соответствуют линейной регрессии модели.
Далее снова выполним все ранее показанные шаги по обучению модели:
df_bin300.fillna(method ='ffill', inplace = True)
X = np.array(df_bin300["Salinity"]).reshape(-1, 1)
y = np.array(df_bin300["Temperature"]).reshape(-1, 1)
df_bin300.dropna(inplace = True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25)
regr = LinearRegression()
regr.fit(X_train, y_train)
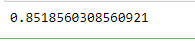
print(regr.score(X_test, y_test))
Вывод результата кода:
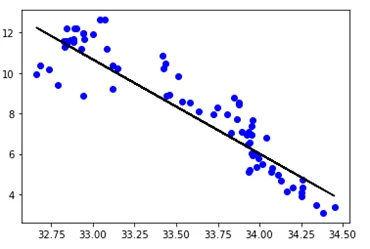
Теперь разброс прогнозируемых значений данных будет таким:
y_pred = regr.predict(X_test)
plt.scatter(X_test, y_test, color ='b')
plt.plot(X_test, y_pred, color ='k')
plt.show()
Использованная в приведенном примере библиотека sklearn имеет важные особенности: наличие в ее составе эффективных инструментов для интеллектуального анализа данных, различных алгоритмов классификации, регрессии и кластеризации, включая support vector machines, random forests, gradient boosting, k-means. Эта библиотека доступна всем и может использоваться повторно в различных контекстах. Она построена на основе NumPy, SciPy, matplotlib. Кроме того, у нее отличная документация и активное сообщество для поддержки и развития.