/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 13 мин.
Был обычный денек, сидел я на работе и занимался своими айтишными делами. Но ко мне пришел boss и сказал: “Нужно рассчитать дистанцию до границы регионов для этих адресов”. При этом без всяких платных сервисов и API онлайн карт, и своими усилиями. Айтишник понял, айтишник принял, айтишник получил свою заветную иксельку и пошёл работать.
Из школьных уроков географии я помнил, что для определения километража требуется знать координаты (широту и долготу) двух точек. И исходя из этого, я как “гуру-программист”, разделил задачу на 4 части:
- Поиск координат границы;
- Предобработка данных;
- Поиск координат адресов;
- Непосредственный расчёт расстояний между координатами.
Ниже продемонстрирован весь путь решения данной задачи, небольшие нюансы, проверка результатов и непосредственно код. И, познакомив читателя с моей маленькой предысторией, расскажу об инструментах, которыми я пользовался.
В качестве основного инструмента для парсинга, обработки и расчётов я использовал всемогущий язык Python. Он очень удобен, богат большим количеством подходящих библиотек для решения моей задачи и обладает высокой скоростью написания кода.
Средой разработки выступали Jupyter Notebook (Anaconda), PyCharm и DataSpell от компании JetBrains (дело вкуса).
Также были замечены py-библиотеки, которые мне пригодились при работе с данным проектом: Numpy, Pandas, Plotly, Geopy, Selenium.
На этом прелюдия заканчивается, переходим к интересному.
Начало начал
Для расчёта дистанции до границы нужны координаты, что неудивительно, самой границы. Вручную прокликивать точки на карте мне не очень хотелось, а попытка поиска готовых координат полностью провалилась. Но, к счастью, удалось найти “.json”-файлик с положением границ субъектов нашей необъятной Родины, среди которых и находятся нужные точки.
Для начала достаю нужные области. Импортирую библиотеки для дальнейшей работы, сохраняю данные файла в словарь (dict) и смотрю на содержимое объекта:
#Библиотека для работы с ".json"-файлами
import json
#Библиотека для обработки и анализа данных
import pandas as pd
#Библиотека для работы с многомерными массивами
import numpy as np
# Считываем файл с координатами всех регионов
with open('data//gadm41_RUS_1.json', encoding = 'utf-8') as js:
dict_coordin_border = json.load(js)
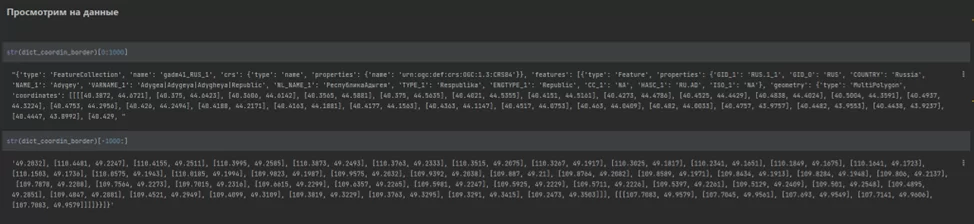
Видно, что “json” хорошо структурирован, и с ним достаточно легко работать. Названия регионов и координаты можно найти по следующим ключам:
- dict_coordin_border[‘features’] [‘properties’][‘NL_NAME_1’] – название субъекта федерации
- dict_coordin_border[‘features’] [‘geometry’][‘coordinates’] – координаты границ тех же субъектов
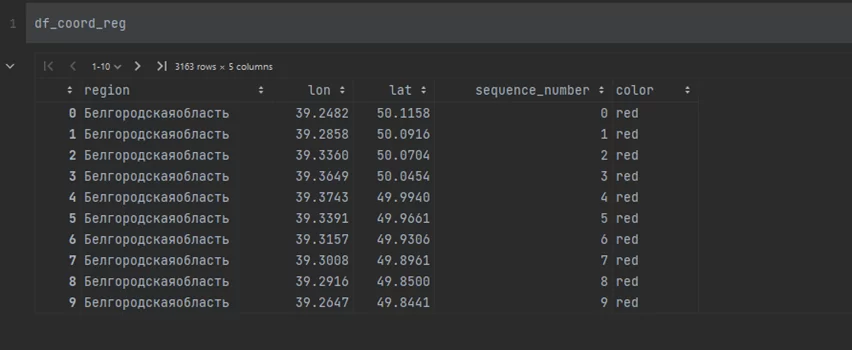
Выделяю из данного словаря только нужные пять областей, и записываю в pandas.DataFrame данные, где:
- “region” — название региона
- «lon» – долгота точки границы
- «lat» — широта точки границы
- «sequence_number» — порядковый номер записи
- «color» — цвет региона
Зачем цвет и порядковый номер? Расскажу далее, а сейчас предлагаю рассмотреть код:
df_coord_reg = pd.DataFrame()
sequence_number = 0
for regions in dict_coordin_border['features']:
#Ставим условия для поля названия субъектов
if regions['properties']['NL_NAME_1'] in ['Воронежскаяобласть',
'Брянскаяобласть',
'Курскаяобласть',
'Ростовскаяобласть',
'Белгородскаяобласть']:
for list_coordin_lv_1 in regions['geometry']['coordinates']:
for list_coordin_lv_2 in list_coordin_lv_1:
for list_coordin_finish_lvl in list_coordin_lv_2:
#Заполняем df: Название региона, координаты точки границы, порядковый номер записи, цвет региона
if regions['properties']['NL_NAME_1'] == 'Воронежскаяобласть': color = 'purple'
elif regions['properties']['NL_NAME_1'] == 'Брянскаяобласть': color = 'white'
elif regions['properties']['NL_NAME_1'] == 'Курскаяобласть': color = 'blue'
elif regions['properties']['NL_NAME_1'] == 'Ростовскаяобласть': color = 'yellow'
elif regions['properties']['NL_NAME_1'] == 'Белгородскаяобласть': color = 'red'
df_coord_reg = df_coord_reg.append({'region': regions['properties']['NL_NAME_1'], #Название региона
'lon': list_coordin_finish_lvl[0], #Долгота точки границы
'lat': list_coordin_finish_lvl[1], #Широта точки границы
'sequence_number': str(sequence_number), #Порядковый номер записи
'color': color}, #Цвет региона
ignore_index = True)
sequence_number += 1
В итоге получается такой красивый frame:
На данном этапе я получил координаты границ регионов со всех сторон. Но это не совсем нужный результат, требуется только та часть границ, которые не совпадают друг с другом. И здесь я хочу рассказать про библиотеку plotly.
Plotly Python – это графическая библиотека для интерактивной визуализации данных. С её помощью можно создавать диаграммы, гистограммы, карты распределения, 2D-диаграммы, 3D-графики и многое другое. Эта библиотека — сильный «зверь» для визуала, и она поможет расположить полученные точки на карте. Подробнее ознакомиться можно по ссылке.
Изображаю точки на географической карте Европы:
#Импортируем библиотеки для визуализации данных
import plotly.graph_objs as go
#Визуализируем на карте точки с координатами для проверки и дальнейшего анализа
fig = go.Figure(data=go.Scattergeo( #Scattergeo - данные, визуализируемые в виде точек географической карте
lon = df_coord_reg['lon'], #Долгота точки
lat = df_coord_reg['lat'], #Широта точки
mode = 'markers', #Вид точки
marker_color = df_coord_reg['color'], #Цвет точки
text = df_coord_reg['region'] + ' ' + df_coord_reg['sequence_number'] #Текст при наведении на точку
),
)
fig.update_layout(
title = 'Субъекты РФ ', #Задаем название карты
geo = dict(
scope='europe', #Шаблон карты
landcolor = "green", #Цвет для стран
countrycolor = "black", #Цвет границ между странами
),
width=1500, #Ширина карты
height=750 #Высота графика
)
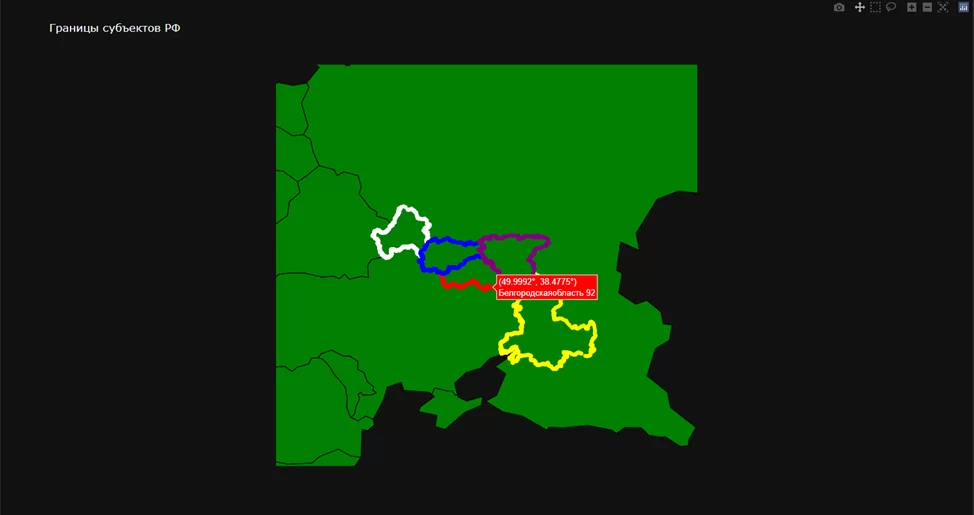
Как видно на рисунке, все точки находятся на своих местах. Осталось из них выбрать только точки, не являющиеся общими для регионов. Для этого я и задавал цвет областей и их порядковый номер.
Выбираю номера точек, которые находятся на границе, и перезаписываю данные в dataframe:
#Исходя из карты, выбираем следующие срезы df и записываем их в новую переменную
df_coord_border = pd.concat([df_coord_reg[11:411],
df_coord_reg[1278:1459],
df_coord_reg[974:1226],
df_coord_reg[3084:3157],
df_coord_reg[2004:2413]])
Для проверки повторно визуализирую данные и сохраняю полученные координаты в “.json”-файл.
#Визуально проверяем полученный dataframe
fig = go.Figure(data=go.Scattergeo(lon = df_coord_border['lon'],
lat = df_coord_border['lat'],
mode = 'markers',
marker_color = df_coord_border['color'],
text = df_coord_border['region'] + ' ' + df_coord_border['sequence_number']))
fig.update_layout(
title = 'Субъекты РФ',
geo = dict(
scope='europe',
landcolor = "green",
countrycolor = "black",
),
width=1500, #Ширина карты
height=750 #Высота графика
)
#Сохраняем данные в json
df_coord_border[['lon', 'lat']].to_json('data//border.json')
Кто? А главное, зачем?
Помните о той иксельке, о которой я упоминал в начале? Вот теперь пришло и её время. Создаю новую тетрадку, импортирую библиотеки, читаю “xlsx”-файл. Смотрю на данные.
import pandas as pd
import numpy as np
import json
#Возьмем данные из входного файла
df_start_adress = pd.read_excel('data//starting_address.xlsx')
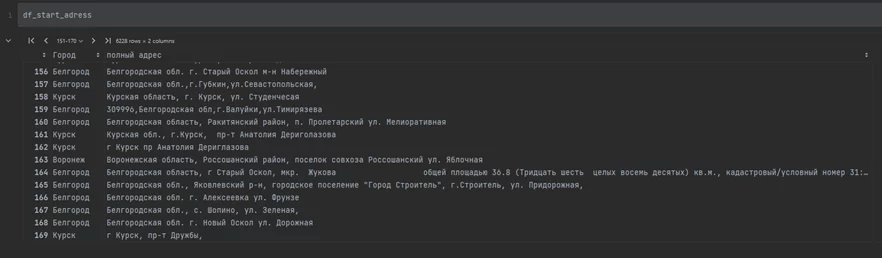
border_coord_df.head()
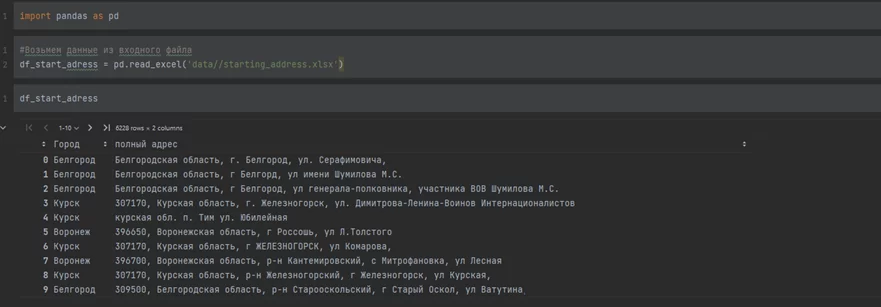
Что же получается? В файле хранятся 6 228 адресов, и, даже взглянув на эту выборку, закрадывается подозрение, что данные не имеют строгого формата. Необходимо удалить дубликаты из dataframe и проверить на пустоту:
#Удалим дубликаты
df_start_adress = df_start_adress.drop_duplicates()
df_start_adress
#None отсутствуют
df_start_adress.info()
#NaN,None и пустота могут быть в виде строки. Проверяем по длине строки
df_start_adress[df_start_adress['полный адрес'].str.len() <= 5]
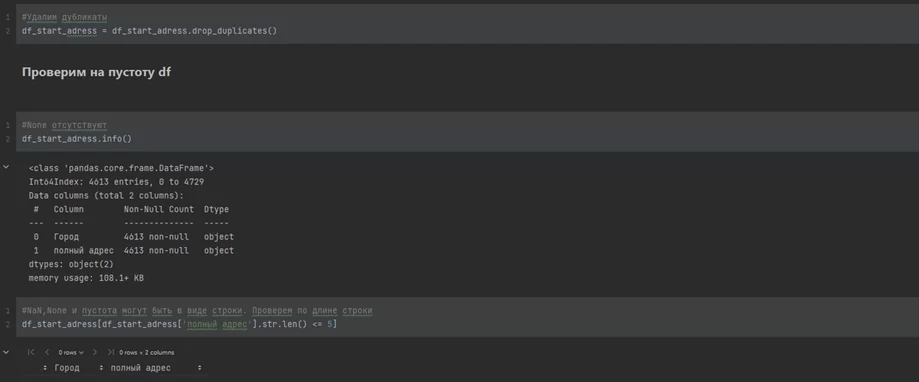
К счастью, пропусков не наблюдается, а после удаления дубликатов dataframe сократился на 2 000 строк.
Проанализировав данные глазками и используя библиотеку pandas, можно выделить несколько проблем:
- Нет строгой типизации формата адресов. Это сильно ограничивает библиотеки и технологии, такие как запросы HTTP и бесплатные API сайтов.
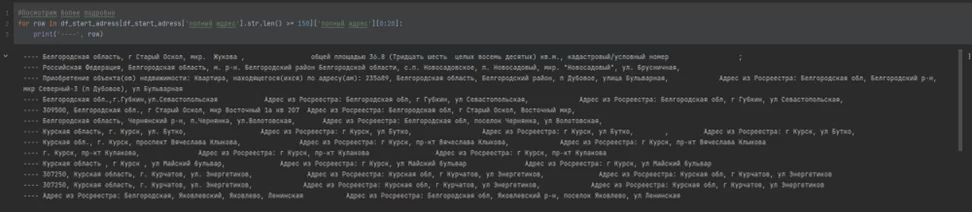
2. В адресах присутствует подстрока “Адрес из Росреестра:». При проверке таких адресов в ”Яндекс.Картах”, выдается адрес отдела Росреестра города исходного адреса или пустой результат поиска:

3. Дублируются данные внутри ячеек. При проверке в онлайн картах данные не выдаются, или строится маршрут движения по этим адресам, точнее, путь от себя к себе:
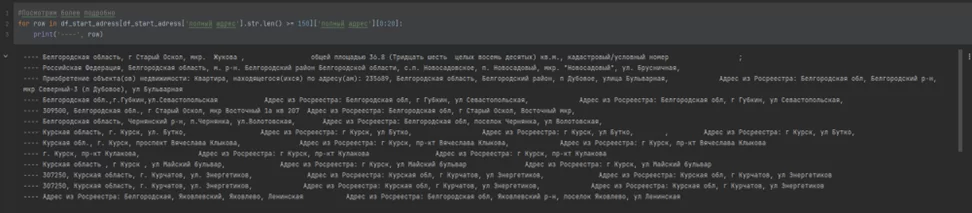
4. Присутствуют лишние данные, которые мешают поиску.
Обработать полученные данные и привести их к одному виду показалось очень трудозатратной задачей. Проверив несколько адресов, я решил использовать сервис “Яндекс Карты”. Он показал, что может работать с различными адресами и выдавать корректный результат.
Но обработать адреса все равно необходимо и избавиться хотя бы от некоторых проблем: подстрока с Росреестром и повторяющиеся данные.
Для этого применяю функцию «formating_text». В функции создаю список, разбиваю строку на слова и помещаю их в список поочередно. Если данное слово уже существует в списке, то его в список не добавляю. В конце удаляю из итоговой строки «Росреестр»:
def formating_text(text):
old_text = text.split()
new_text = []
for word in old_text:
if word not in new_text:
new_text.append(word)
return ' '.join(new_text).replace('Адрес из Росреестра: ', '')
df_start_adress['formating_adress'] = df_start_adress['полный адрес'].apply(lambda x: formating_text(x))
Сохраняю полученный результат и перехожу к следующему этапу.
Дёшево и сердито
Самые внимательные читатели могли заметить, что для данного проекта я использовал библиотеку Selenium. Почему именно она? Она обладает преимуществами на фоне остальных библиотек и методов парсинга. Её ближайшие аналоги:
- API “Яндекс.Карт”. Данная система хоть и очень удобна в использовании для этой задачи, но она не бесплатна. А мы договаривались в начале публикации, никаких дополнительных вложений.
- Http/Https-запросы. В отличие от системы, описанной выше, для запроса требуется только возможность подключения к нужному сайту. Но с моими данными написание “get”/”post”- запросов — довольно сложная задача. К примеру, запрос “https://yandex.ru/maps/213/moscow/house/mokhovaya_ulitsa_11s1” состоит из названий города, улицы и номера дома на транслите. Преобразовать входящие данные в такой формат будет непосильной задачей для меня.
Методом исключения осталась только библиотека Selenium, которая будет симулировать действие человека в браузере на сайте. Это позволит обойти системы защиты Яндекса, воспользоваться их алгоритмами обработки данных и найти координаты объекта.
Сразу скажу, здесь я не буду обучать вас данной библиотеке. Лишь разберу основной алгоритм работы скрипта, покажу некоторые нюансы и возможные методы их решения.
Подключение драйвера. В данном проекте я использовал браузер Google Chrome, и примеры будут для Google. Библиотека Selenium уже имеет в себе драйвер для работы с Google, и для его подключения просто нужно прописать команду “webdriver.Chrome()”. Для перехода на сайт используйте функцию “get”.
from selenium import webdriver
#Адрес сайта "Яндекс.Карты"
url_adress = 'https://yandex.ru/maps'
#Подключение драйвера Google
driver = webdriver.Chrome('chromedriver.exe')
#Переход на сайт
driver.get(url_adress)
time.sleep(5)
Поиск адреса. Адрес вписывается в поле формы поиска, код данного элемента «<input class=”input__control_bold” >». Для поиска элемента использовал комбинацию функций “WebDriverWait” и “ExpectedCondition”. Selenium будет производить поиск элемента, пока он не будет найден или не кончится время ожидания.
Далее заполняю найденную форму адресом с помощью функции «send_keys» и запускаю поиск, имитируя нажатие клавиши “Enter” функцией «send_keys(Keys.ENTER)».
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Время ожидания
delay = 10
# Поиск формы ввода на сайте
elem_search_string = WebDriverWait(driver, delay) \
.until(EC.presence_of_element_located(
(By.XPATH, "//input[@class='input__control _bold']")))
# Вписываем данные в форму
elem_search_string.send_keys(adress)
# Запускаем поиск
elem_search_string.send_keys(Keys.ENTER)
Результат поиска. Если все отработало штатно, Яндекс должен выдать географические координаты адреса. С помощью уже знакомой комбинации “WebDriverWait” и “ExpectedCondition” записываю координаты в переменную:
# Поиск координат на сайте
elem_search_2 = WebDriverWait(driver, delay) \
.until(EC.presence_of_element_located(
(By.XPATH, "//div[@class='toponym-card-title-view__coords-badge']")))
# Запись в переменную координат адреса
coord = elem_search_2.text
Но Яндекс — не всемогущая машина, он не всегда находит однозначный ответ, поэтому на некоторые адреса он предлагает несколько вариантов. Как, например, здесь:

На случай таких ситуаций я брал первый предложенный вариант. Скорее всего он и будет являться нужным мне адресом:
elem_first_list = WebDriverWait(driver, delay) \
.until(EC.presence_of_element_located(
(By.XPATH, "//div[@class='search-snippet-view__body _type_toponym']")))
elem_first_list.click()
И напоследок очищаю форму записи:
try:
elem_clear = WebDriverWait(driver, 2) \
.until(EC.presence_of_element_located(
(By.XPATH, "//a[@class='small-search-form-view__pin']")))
except:
elem_clear = WebDriverWait(driver, 2) \
.until(EC.presence_of_element_located(
(By.XPATH, "//div[@class='small-search-form-view__icon _type_close']")))
Рекомендую объединить поиск координат на сайте и очистку формы записи на случай, если сервис не найдет никакого результата. Это позволит продолжить работу скрипта и не перезапускать программу.
Повторяю все вышеперечисленные действия ещё 3 000 раз для укрепления здоровья и сохраняю результат в файл.
Финишная прямая
Осталось дело за малым: рассчитать дистанцию между координатами адресов и кратчайших точек построенной границы. С этим поможет библиотека Geopy.
Geopy — это сторонняя библиотека Python для определения географического местоположения. Она позволяет разработчикам Python легко находить координаты адресов, городов, стран и достопримечательностей по всему миру, используя сторонние геокодеры и другие источники данных. Ознакомиться с библиотекой можно по ссылке.
Для начала импортирую библиотеки и данные с файлов, которые получил ранее: координаты границы и адреса. Преобразую их в нужный формат для удобства в работе.
#Импортируем библиотеки
import pandas as pd
from geopy.distance import geodesic as GD
import json
from tqdm import tqdm
#Ипортируем данные с координатами
with open("data/adress_coord.json", 'r', encoding='utf-8-sig') as ad_cor:
adress_coord_dict = json.load(ad_cor)
border_coord_df = pd.read_json("data//border.json")
#Для удобства словарь с координатами адресов преобразуем в df
atress_coord_df = pd.DataFrame(adress_coord_dict.items(), columns=['adress', 'coord'])
# Преобразуем координаты границы в список
list_border_coord = list([(row['lat'], row['lon']) for index, row in border_coord_df.iterrows()])
Из библиотеки Geopy меня интересует только одна функция, которая как раз и рассчитает расстояние между двумя координатами – “geodesic”. Показываю, как она работает на примере:
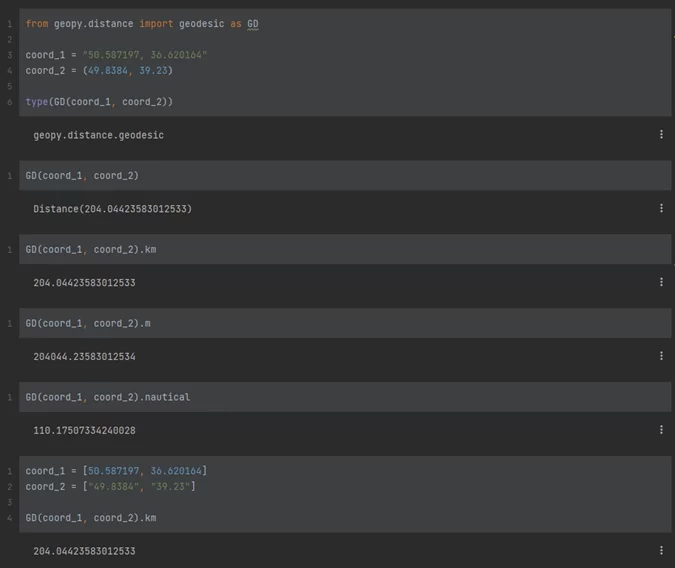
Как видно из примера, в функцию нужно подавать широту и долготу в виде списка, множества, строки или кортежа. Главное, чтобы данные подавались попарно. В конце можно добавить единицу измерения расстояния: километры (“km”, “kilometers”), метры (“m”, “meters”), мили (“mi, ”miles”) и т.д.
Теперь пишу функцию, которая и будет считать минимальное расстояние между точками границы и адресом:
def distance_calculation(start_coord):
list_dist = []
for bord_coord in list_border_coord:
#Для расчета расстояния используем функцию GD([1 координаты точки],[2 координаты точки].[единица измерения расстояния])
dist = GD(start_coord, bord_coord).km
#Добовляем в список результат
list_dist.append(dist)
#Возвращаем минимальную дистанцию из списке
return min(list_dist)
tqdm.pandas()
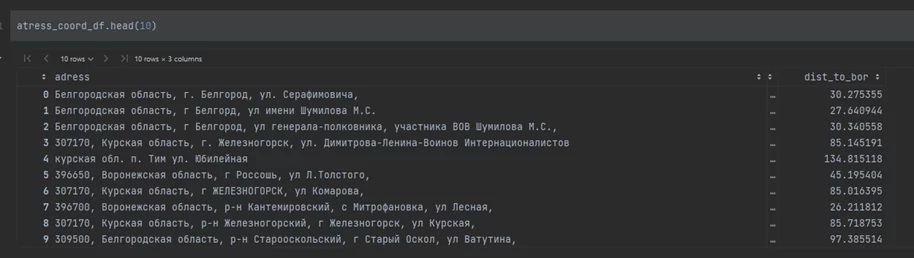
atress_coord_df['dist_to_bor'] = atress_coord_df['coord'].progress_apply(lambda x: distance_calculation(x))
Итоговый результат:
Оценка качества
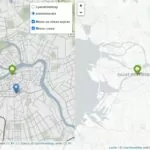
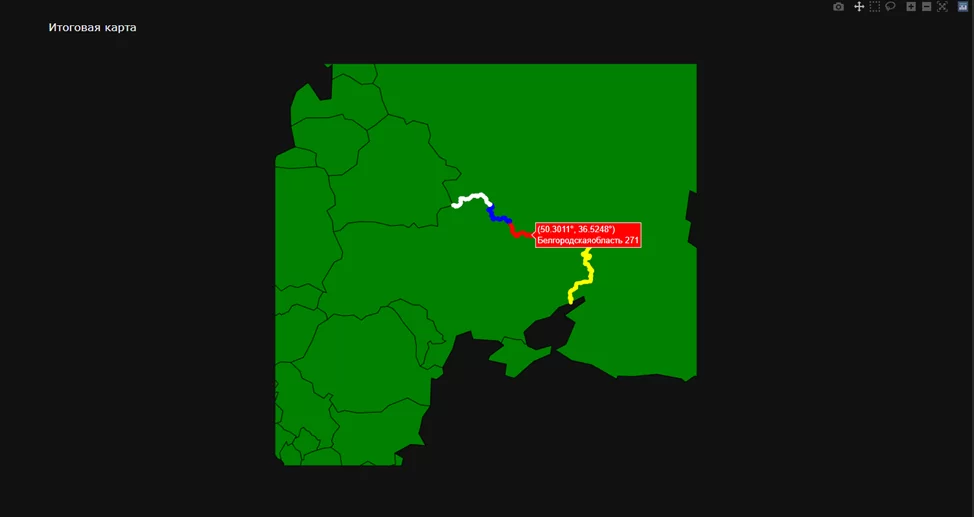
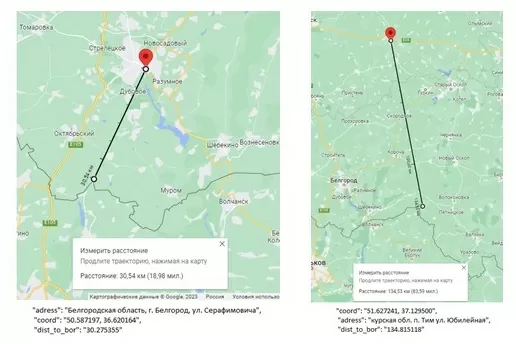
Для сдачи итоговых результатов нужно их проверить, ведь плохой результат никто не любит. Открываю Google Maps и адреса из первоначальной иксельки, расстояние до границы и линейку. И, как видно из рисунков, результаты корректны, а погрешность — в допустимых нормах.
Вывод
Что я могу сказать по итогу? Задача необычная, интересная и в меру сложная. Попрактиковался с библиотеками Pandas, Selenium, Plotly и посмотрел на новую библиотеку Geopy. Результат работы корректен, а погрешность — в допустимых рамках. Старшие довольны, и данные пошли дальше в работу. Написал публикацию и загрузил работу на Github.
Кстати, чуть не забыл, с кодом вы можете ознакомиться по ссылочке на гите.
В общем, задача мне понравилась. Я получил дополнительный опыт и даже некие новые знания, и на этом я заканчиваю пост. Желаю всем удачи!)