/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Сегодня мы продолжим рассматривать Spark, в частности расскажем о способах конфигурирования SparkSession.
Кратко напомним о Spark и его архитектуре.
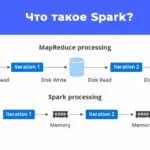
Apache Spark – вычислительная система с набором библиотек для распределенной обработки данных. Spark используется для разработки витрин, моделей, работы с графами и для обработки огромных массивов данных.
Архитектура Spark приложения.
Spark Core архитектура состоит из следующих основных компонентов:
- Driver
- Cluster Manager
- Executor
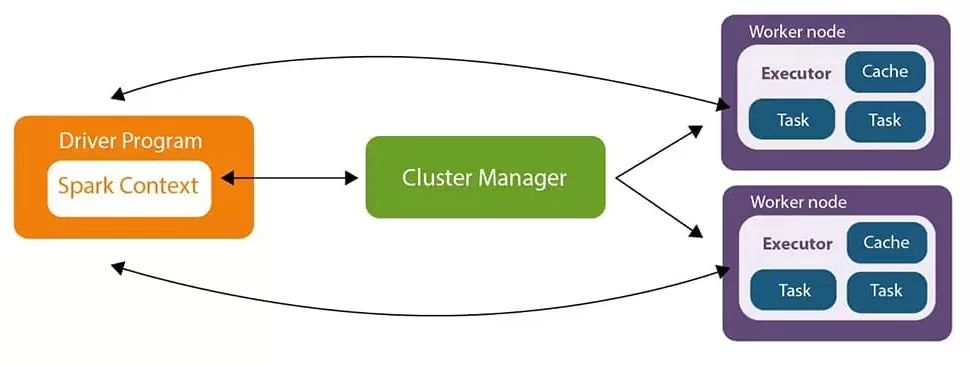
Driver выступает в роли планировщика задач для исполнителей.
Cluster Manager отвечает за выделение кластерных ресурсов, необходимых для решения задачи.
Executors – сущности, которые выполняют некоторую часть работы, распределенную Driver, исходя из поставленной задачи. Исполнители обладают важным свойством – отказоустойчивостью, т.е. при сбое в работе одного из исполнителей, его задача передается другому исполнителю.
Объем памяти, используемый каждым процессом-исполнителем в конфигурациях Spark имеет тот же формат, что и в конфигурациях JVM, например, 512m, 2g.
Выделение ресурсов – основной этап конфигурирования spark приложения. Кроме этого, Spark позволяет использовать при конфигурировании множество других настроек, например, количество партиций, степень параллелизма и т.д.
Первоначально определимся с тем, как выделять ресурсы кластера для разрабатываемого приложения. Далее в качестве примера будем рассматривать кластер со следующими характеристиками при конфигурировании spark приложения.
Кол-во узлов: 6
CPU: 16 ядер
RAM: 128 GB
HDD: 500 GB
Конфигурирование Spark приложения
Под конфигурированием понимается возможность управлять свойствами Spark приложения. Spark позволяет гибко настраивать конфигурации, от данных настроек зависит скорость работы приложения.
Существуют следующие способы конфигурирования Spark, приоритетность использования которых, определена ниже:
- SparkSession
- Command Line Interface (CLI) / spark2-submit
- spark-defaults.conf
Например, при разных значениях одного и того же параметра в SparkSession и spark2-submit будет использована конфигурация из SparkSession.
SparkSession
Конфигурирование SparkSession происходит непосредственно в коде приложения при создании SparkSession, либо позднее, путем редактирования SparkSession.
Пример создания SparkSession:
protected def getSparkSession : SparkSession = {
SparkSession.builder
.setAppName(getClass.getSimpleName)
.set(“spark.executor.memory” “10g”)
.set(“spark.executor.cores” “5g”)
.config("hive.exec.dynamic.partition","true")
.enableHiveSupport.getOrCreate
}
Spark2-submit
Spark2-submit – это скрипт, который позволяет запускать spark код, написанный на любом языке программирования, доступном Spark. Spark2-submit позволяет динамически конфигурировать spark приложение и передавать аргументы без пересоздания jar файла.
Минимально необходимая конфигурация в spark2-submit для запуска spark приложения имеет следующий вид:
spark2-submit --class ru.sbrf.test.data.TEST_T /home/username/./common.jarSpark-defaults.conf
Ресурсы и настройки, которые не указаны в SparkSession и spark2-submit, будут использованы из конфигурационного файла spark-defaults.conf.
Файл spark-defaults.conf размещен в папке, в которую производилась установка Spark.
$SPARK_HOME/conf/spark-defaults.conf /* $SPARK_HOME – директория spark */
Пример пути с расположением файла spark-defaults.conf: /etc/spark/conf/spark-defaults.conf
Пример конфигурации с выделением ресурсов кластера:
spark2-submit --driver-memory $DRIVER_MEMORY --num-executors $NUM_EXECUTORS --executor-cores $EXECUTOR_CORES --executor-memory $EXECUTOR_MEMORY --class ru.sbrf.test.data.TEST_T /home/username/./common.jarДалее рассмотрим, как выделять ресурсы для нашего spark приложения.
Количество ядер на узел
Первоначально определимся, что одно ядро на каждом узле кластера должно быть выделено под нужды ОС.
Не рекомендуется выделять более чем 5 ядер на исполнителя на каждом узле кластера. Кроме этого нецелесообразно выделять 1 ядро, т.к. в данном случае не будут использованы преимущества параллелизма.
При 15 ядрах выбор производится между 3 и 5 ядрами на исполнителя (т.к. 15 без остатка делится только на 3 и 5) и разделение ядер между исполнителями будет равномерное.
При выборе 5 ядер будет выделено 3 исполнителя на узел (с учетом драйвера на последнем узле), по 3 ядра на каждого исполнителя.
При выборе 5 ядер преимущества параллелизма проявляются лучшим образом. —executor-cores = 5
Количество исполнителей на узел
Для расчета количества исполнителей на узел, возьмем количество исполнителей кратным 3 с учетом драйвера. Num-executor рассчитывается по следующей формуле:
--num-executor = 3x – 1
--num-executor = 3 * 6 (количество узлов) – 1
--num-executor = 17 (18-й - Driver)
| Node №1 | Node №2 | Node №3 | Node №4 | Node №5 | Node №6 |
| Executor | Executor | Executor | Executor | Executor | Executor |
| Executor | Executor | Executor | Executor | Executor | Executor |
| Executor | Executor | Executor | Executor | Executor | Driver |
Объем памяти на узел
Для расчета объема памяти на узел предварительно необходимо узнать, сколько оперативной памяти доступно на кластере. Как было описано выше, каждый узел рассматриваемого кластера имеет 128 ГБ RAM, однако часть памяти автоматически резервируется под нужды ОС. Проверить доступную память возможно в Cloudera Manager.
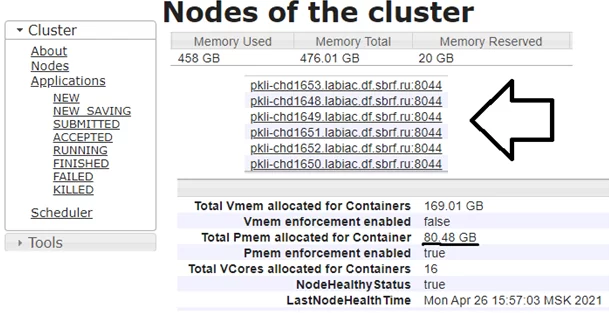
Также необходимо учесть накладные расходы памяти для исполнителя, которые по умолчанию составляют 10% от размера выделяемой памяти исполнителю, либо 384 МВ (по умолчанию), в зависимости от того, что больше. Далее будем предполагать, что накладные расходы составляют 384 МВ.
Executor-memory рассчитывается по следующей формуле:
—executor-memory = доступная память / количество исполнителей на узел – накладные расходы
—executor-memory = 80 GB / 3 – 384 МВ * 6
—executor-memory = 24 g
Количество памяти на драйвер
Исходя из рекомендаций Amazon Web Service (AWS), количество памяти на драйвер установим равным executor-memory
—driver-memory = 24 g
Количество ядер на драйвер
Количество ядер на драйвер будем использовать в соответствии со значением по умолчанию – 1.
—driver-cores = 1
Другие важные конфигурации Spark
—conf spark.sql.shuffle.partitions=500 /* 500 указано в качестве примера */
Количество партиций следует указывать в зависимости от приложения, по умолчанию – 200. Используется при вызове операций shuffling’a, таких как union(), groupBy(), join(). Доступно только в DataFrame API.
—conf spark.default.parallelism=500
По умолчанию равно общему количеству ядер на кластере.
Чтобы было удобно запускать приложение, создадим баш скрипт «run.sh».
Результирующая конфигурация будет выглядеть следующим образом:
#!/bin/bash/
DRIVER_MEMORY=24g
NUM_EXECUTORS=17
EXECUTOR_CORES=5
EXECUTOR_MEMORY=24g
nohup spark2-submit --driver-memory $DRIVER_MEMORY --num-executors $NUM_EXECUTORS --executor-cores $EXECUTOR_CORES --executor-memory $EXECUTOR_MEMORY --conf spark.network.timeout=1000S --class ru.sbrf.test.data.TEST_T /home/kagermanov2-rm_ab-srb-local/./common.jar > spark.log &
Для запуска на узле кластере необходимо использовать команду: «sh run.sh».
Резюмируя отметим, что конфигурирование SparkSession является одной из ключевых возможностей для оптимизации Spark приложения.