/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 15 мин.
Многие привыкли считать, что компьютерное зрение — это какая-то неимоверно сложная технология и исключительно вещь в себе. Ну, конечно, кроме тех людей, которые занимаются непосредственно компьютерным зрением. Надеюсь.
Сегодня я хочу рассказать про один фокус, можно сказать, забавный эксперимент — довольно известный, возможно, среди опытных обработчиков изображений, но настолько слабо применимый на практике, что не часто о нём заходит речь. Однако, этот маленький эксперимент, как мне кажется, наводит на интересные теоретические выкладки относительно работы свёрточных нейросетей. Эксперимент, о котором я говорю — поиск объекта на изображении при помощи функции взаимной корреляции (без нейронных сетей). Звучит, возможно, пугающе и непонятно, но на деле всё очень просто, чистая математика.
Рассуждение о природе данных
Итак, для начала: что же есть изображение? При достаточном углублении в тему, вопрос сложный. Чтобы описать практическую часть этого понятия, я несколько раз повторю «чаще всего» — ведь практика компьютерной графики насчитывает более полувека опыта, и за это время придумывались самые разные подходы и примочки, полезные в тех или иных приложениях. Однако, хвала небесам, сложились и некоторые классические пути, о которых мы можем говорить «чаще всего».
Если начать рассуждать, то определить изображение не «в компьютере», не «как мы его видим глазами», а как таковое, как абстракцию, то сказать можно только то, что изображение — это некий объект-копия, дающий нам представление о том, как выглядит объект-оригинал. Наскальные рисунки, египетские фрески, картины на холстах, 3d-модели, фотографии — это всё изображения.
На самом деле, чуть более технически изображение можно воспринимать как некий набор пространственно закреплённых яркостей. Бывает такая штука как непрерывное изображение. Это изображение в том виде, как мы его воспринимаем глазами — поток света с различными волновыми характеристиками, отражённого от разных поверхностей и под разными углами попадающего нам на сетчатку. Засунуть такое изображение в компьютер целиком, ну, невозможно — в компьютер вообще крайне плохо помещается бесконечность.
Существуют различные ухищрения, как это можно сделать. Изображение можно аналитически приближать, по крайней мере для несложных случаев, как это делается в векторной графике: картинка представляется в виде аналитически заданных примитивов, и потом растеризуется, чтобы можно было показать на экране. Или как в 3d-графике: объект-оригинал представляется поверхностью, составленной из полигонов, и конкретные яркости-цвета можно считать «лениво» — с нужной стороны, при определённых условиях освещения и пр. Но чаще всего изображение в компьютере предстаёт в виде дискретного или, правильнее сказать, цифрового изображения — не в последнюю очередь из-за технологий работы экранов, которые умеют рисовать только пиксели.
В обработке сигналов есть понятие аналогового, дискретного и цифрового сигналов. Аналоговый сигнал — это непрерывный (чаще всего, звуковой) сигнал, переложенный на некий колебательный аналог (чаще всего, электромагнитные колебания) максимально приближенно по характеристикам к исходной (той самой, звуковой) кривой. Он имеет свои искажения, но зато может обрабатываться и передаваться аналоговой аппаратурой. Дискретный сигнал — это аналоговый сигнал, над которым произвели процедуру дискретизации, то есть из бесконечного числа значений непрерывного аналогового сигнала нащипали конечное число отсчётов с выбранным шагом. Дискретный сигнал не является непрерывным, это просто набор точек. Тем не менее, чтобы стать совсем уж приятным цифровым сигналом, он должен ещё пройти процедуру квантования — аналогичная дискретизации штука, но применяется к области значения, и вообще-то может иметь неравномерную шкалу квантования — логарифмическую, например.
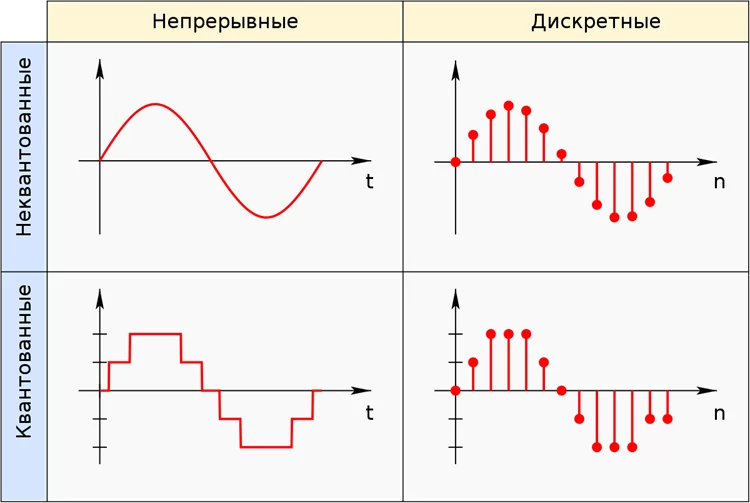
Так вот, дискретизация для изображения — это разделение его на пиксели, а квантование — «обрезание» цветов пикселей под машиноинтерпретируемые цвета. Чем мельче шаг, тем выше качество, но и выше затраты памяти.
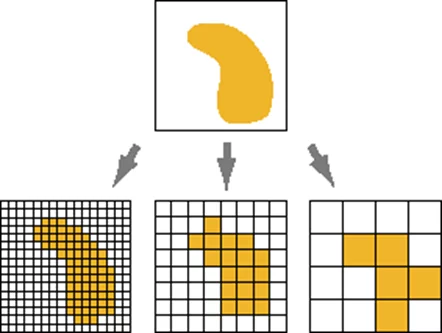
Если говорить о самом обычном изображении, то (чаще всего) это матрица из N на M пикселей, каждый из которых (чаще всего) описывается тремя числами от 0 до 255, смысл которых (чаще всего) — яркость красного, зелёного и синего цветов в каждом дискрете изображения.
Немного теории о конволюции и о корреляции
Чтобы обрабатывать такие вот цифровые изображения, часто используют так называемую процедуру свёртки или, иначе говоря, конволюции. Математически это преобразование записывается так:
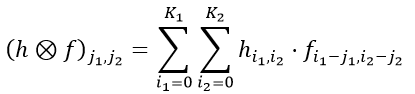
Есть ещё всякие Фурье-приколы о том, как сделать её быстрее, но их пока опустим. При свёртке предполагается, что у нас есть f — основное изображение, а также h — некий фильтр, ядро свёртки, матрица размером K1 на K2, в которой лежат какие-то числа. Чаще всего h при свёртке сильно меньше f, и крайне распространены, например, фильтры размером 3 на 3.
После свёртки мы получаем матрицу того же размера, что изначальное изображение. Механически, в формуле написано, как считается каждый пиксель получаемой матрицы:
- К изображению f прикладывается фильтр h;
- Все пиксели h и f, для которых есть наложение, перемножаются;
- Потом результат умножений суммируется и записывается в пиксель.
По-хорошему, надо ещё нормировать всю эту красоту, но здесь предполагается, что фильтры подобраны особым образом, из-за чего нормировка не нужна.
Помимо свёртки, есть ещё такая штука как корреляция — или, более официально, корреляционная функция. Она записывается так:
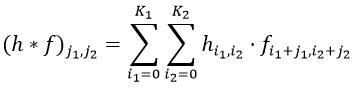
Изрядно знакомый вид — от свёртки её отличает только знак в индексе, и он выливается в угол поворота кусочка h. Корреляцию можно считать при h = f, тогда она будет автокорреляционной функцией (АКФ). Если считать от разных изображений, то она называется взаимной корреляционной функцией (ВКФ).
ВКФ вообще применяется для анализа похожести сигналов — она выдаёт большое значение там, где сигналы сходятся, и небольшое значение там, где они различны. И если мы возьмём небольшой кусочек сигнала (например, звуковую запись какого-нибудь слова) и вычислим его ВКФ с некоторым сигналом (например, со звуковой записью человеческой речи), то в общем случае получим максимальные значения там, где было что-то, существенно похожее на этот кусочек (в нашем примере, место записи речи, в котором есть выбранное слово).
Однако если так считать ВКФ по предыдущей формуле, картинка получится специфическая. Здесь h — не какой-то специально подобранный фильтр, а такая же картинка. Она по размеру обычно более сравнима с основной картинкой f, и сумма пикселей у нее не обязательно будет нормальна. Поэтому, для наших целей, такую ВКФ надо нормировать, чтобы не получить засвеченную картинку:
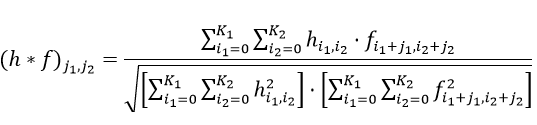
Реализация в коде
Ну вот в общем-то и всё с теорией, перейдём же теперь к практике. Реализуем ВКФ для картинок в коде, как и обещали, при помощи операторов + и * (правда, имея ввиду нормализацию, всё-таки +, *, / и ** — возведение в степень 2 и 1/2). Это не сложно, так как у нас есть формула и нет цели сделать функцию оптимальной — для нашего эксперимента, как мне кажется, «тупой» расчёт формулы даже лучше в своей наглядности. Таким образом, в коде ВКФ будет выглядеть следующим образом:
import numpy as np
from numba import njit
@njit
def count_correlation(main, part):
res = np.zeros(main.shape)
h_f, w_f = main.shape # высота и ширина основного изображения
h_h, w_h = part.shape # высота и ширина искомого кусочка
s_h = np.sum(np.square(part)) # двойная сумма по h, считается один раз
for j1 in range(w_f):
for j2 in range(h_f):
k = 0 # двойная сумма ВКФ
s_f = 0 # двойная сумма по f, эту нужно накапливать
for i1 in range(w_h):
for i2 in range(h_h):
if j1 + i1 >= w_f or j2 + i2 >= h_f:
continue
k += part[i2, i1] * main[j2 + i2, j1 + i1]
s_f += main[j2 + i2, j1 + i1] ** 2
res[j2, j1] = k / ((s_f * s_h) ** 0.5) # запись значения пикселя
return res
Ну да, цели сделать функцию оптимальной нет, но всё же, чтобы не ждать по три часа, я подключила к этой функции возможности ускорения numba, что и вам советую. Правда, у меня не получилось прикрутить к циклу прогресс-бар — numba не работает с tqdm напрямую, и есть что-то вроде обёртки над tqdm: объект ProgressBar в модуле numba_progress. Вернее, прикрутить-то я его прикрутила, но у меня он капает целым куском, то есть вот был 0, и вот резко стал 1280. Убрала из листинга, потому что он бесполезен.
Применение на данных
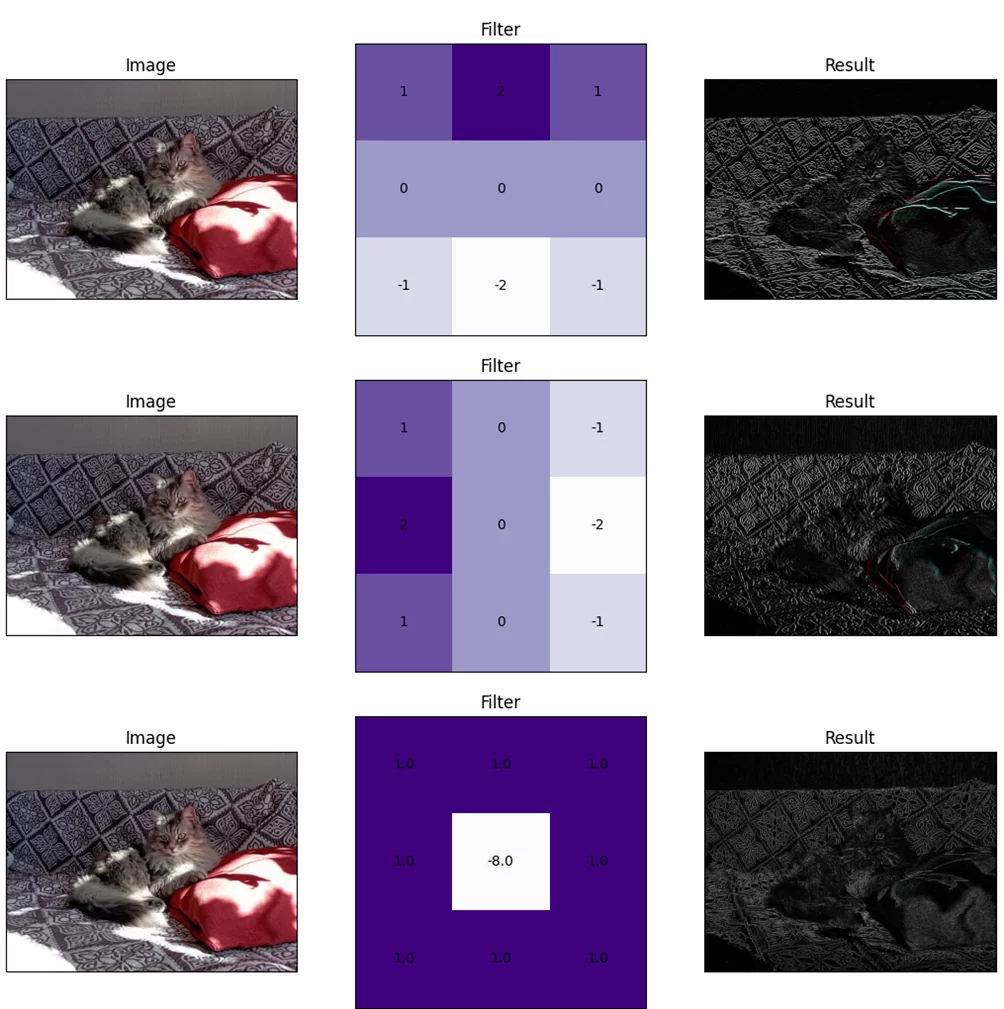
Давайте же применим это к каким-нибудь картинкам. Вот, например, мне очень нравятся результаты, которые получаются от подобных изображений:
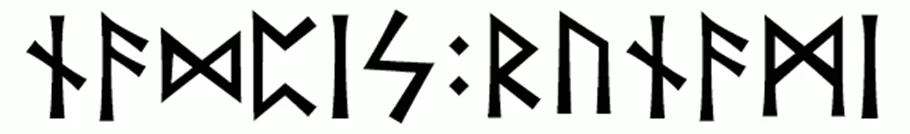
Возьмём разные фрагменты этого изображения и посмотрим, что выдаст ВКФ.
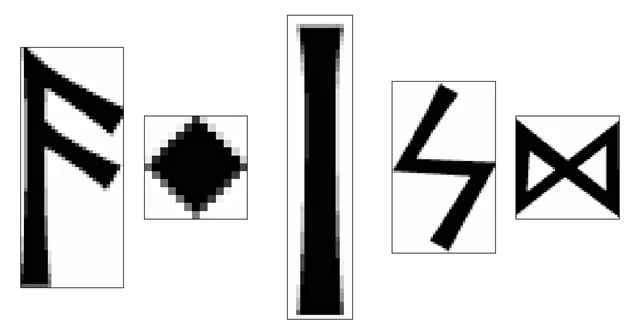
Условно я буду называть эти фрагменты «буква F», «точка», «буква I», «четвёрка» и «восьмёрка» соответственно. Предлагаю посмотреть, что получается для них, и подумать, почему так.
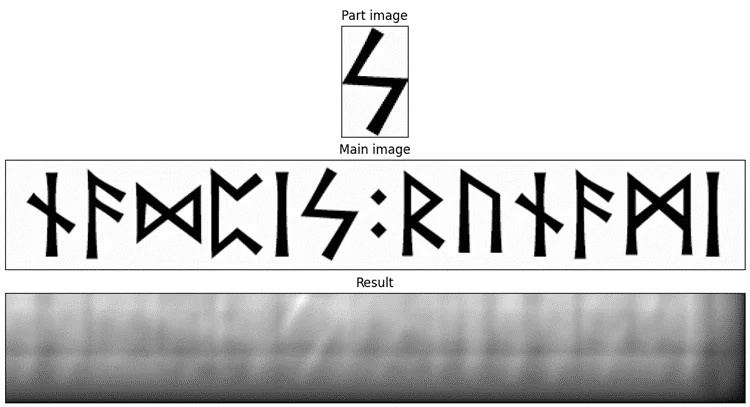
На «четвёрке» хорошо можно увидеть, как вообще работает поиск через ВКФ. В том самом месте, где будет левый верхний угол маски, когда маска будет лежать ровно на символе «четвёрки», появляется отчётливый засвет. Кроме того, на ВКФ можно увидеть чуть менее светлые, но всё же видимые участки, параллельные «ногам». Потому что если маска сдвинется в направлении, параллельном направлению этих «ног», ВКФ, хоть и не будет совсем уж большой, то всё-таки останется существенной.
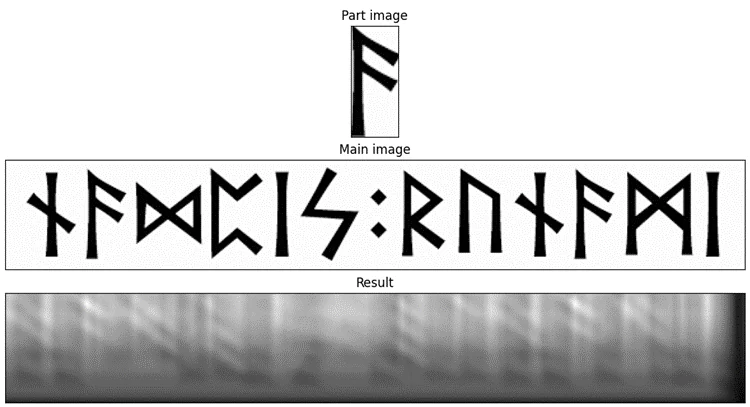
Аналогичную ситуацию можно увидеть для «буквы F»: во всех местах, где маска ложится на что-то более или менее похожее, есть засвет — в том числе отдельно подсвечивается узел нижней перекладины «буквы F». Фактически, она неплохо находит все вертикальные «столбы».
На результате «восьмёрки» мы можем увидеть два ярких засвета — там, где как раз «восьмёрка» и «буква М». И ещё два-три существенных засвета в середине отмечают похожие паттерны — на «букве R» с верхней и с нижней частью, плюс между «четвёркой» и «буквой R».
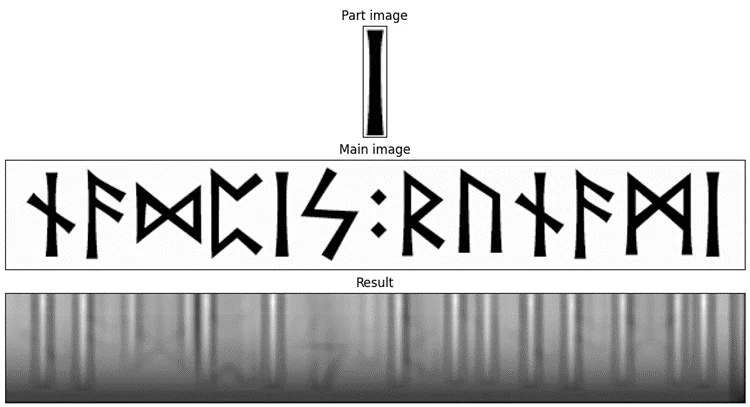
Результат «буквы I» ещё лучше демонстрирует работу ВКФ. Обратите внимание: подсвечены все вертикальные «столбы», но по краям от этих засветов есть затемнения. Они образуются там, где белый край маски ещё лежит на чёрной букве изображения, а чёрная буква маски уже лежит на белом фоне изображения — поэтому корреляции ещё меньше, чем просто на белом фоне.
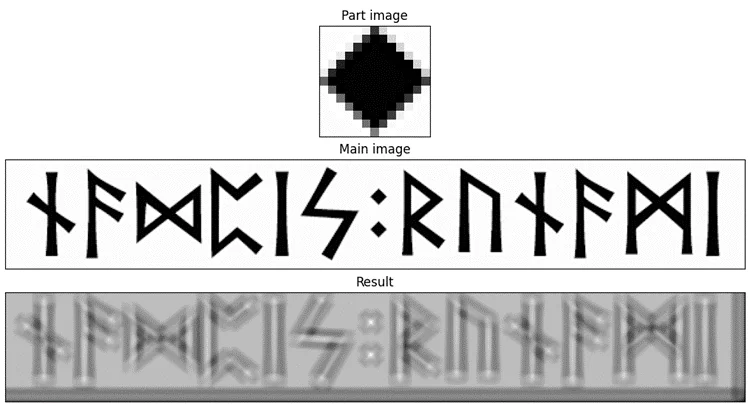
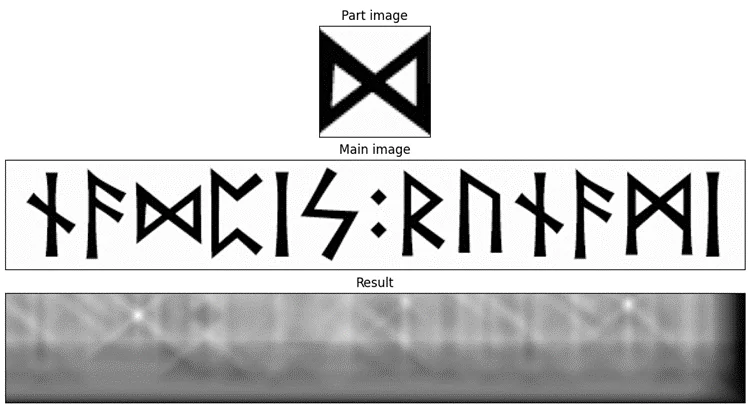
Ну, и аналогичная картина с «точкой»: сильнее всего подсвечены, собственно, точки в середине; так же, как на «букве I», подсвечены все части букв, и так же имеются затемнения по контурам. Засветы на точках имеют X-образную форму, потому что наша «точка» при сдвигах маски по диагоналям остаётся всё ещё похожей сама на себя.
Используя эту штуку, можно реализовать алгоритм детектирования, например, символов на сканах документов, книг. Для этого нужно набрать соответствующее количество изображений детектируемых объектов и сравнивать их все с анализируемым изображением (сканированной страницей), а потом соединять светлые пятна на разных корреляциях по локации и находить для каждого пятна символ по максимальному сходству.
Но на практике такой алгоритм довольно специфичен, неустойчив к смене, например, начертания и кегля шрифта, цвета бумаги, слабо применим к рукописному вводу, чрезвычайно уязвим к повороту и так далее. К тому же он довольно громоздкий и плохо расширяемый: с увеличением пула картинок вычислительная сложность будет расти довольно существенно. Опять-таки, для обычных фотографий эта штука таких выразительных результатов не даёт.

Так как же нейронная сеть управляется без нейронной сети?
А теперь давайте немного вспомним то, о чём я говорила в начале. О свёрточных нейронных сетях — тех самых, которыми в большинстве и решается задача распознавания графических образов. Почему они так называются и как подходят к проблеме распознавания графических объектов?
На английском название этой технологии звучит как Convolusion Neural Network (CNN) , на русском слово «свёрточная» распространено, пожалуй, больше. По сути, как работает нейронная сеть, если вкратце:
- на вход сети подаются какие-то фиксированные признаки (допустим, первый вход — это всегда длина помидора, второй вход — всегда усреднённый коэффициент упругости, третий — степень видимости прожилок и т.д);
- каждый нейрон первого слоя умножает эти признаки на веса (у каждого нейрона веса свои, и они настраиваются в процессе обучения — когда сеть смотрит на разные помидоры);
- каждый нейрон первого слоя складывает результаты взвешенных признаков;
- каждый нейрон первого слоя прикладывает полученную сумму к функции активации и получает свой итоговый выход;
- нейроны первого слоя передают свой выход следующему слою (и всё, что было с нейронами первого слоя, повторяется для второго и так далее, пока слои не закончатся);
- наконец, нейроны последнего слоя, а вернее один нейрон (допустим, ответ нейронной сети — это одно число: «0» — если помидор нельзя кушать, «1» — если можно) свой выход выдают как ответ сети.
Основная революционная прелесть технологии CNN заключается в том, что она позволила обрабатывать нейросетью не какие-то «руками» выделенные признаки картинки, а загружать изображение как есть, в виде пиксельных матриц. Выделение же признаков изображения, по сути, было перенесено на веса изображений, которые в CNN представляют собой (чаще всего) квадратные матрицы и настраиваются в процессе обучения. Если раньше исследователь при создании архитектуры сети подбирал набор признаков изображения, обучал на них сети, искал новые признаки, потому что первые (чаще всего) не работают так хорошо, как хотелось бы — с CNN стало можно показывать сети как можно больше картинок, чтобы она их запоминала через «фильтры». Правда, это происходит за счёт монструозного увеличения вычислительной сложности, требований к объёму датасетов, сложностей с обучением глубоких слоёв сети… но это работает.
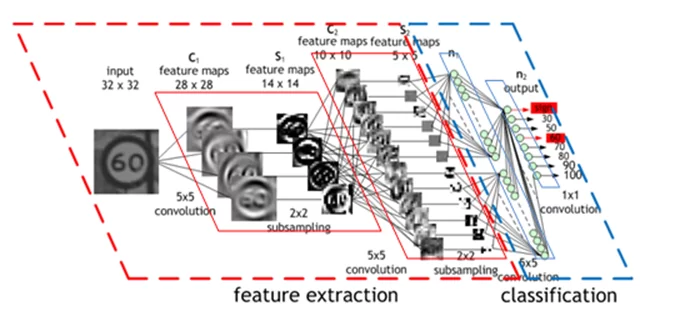
И это, по сути, очень похоже на то, что мы с вами воспроизводили выше (с поправкой на количество слоёв, на малую размерность матриц, на множество технических деталей и тот самый знак, который отделяет конволюцию от корреляции). CNN используют тот же самый принцип, только матрицы h в них зашиты в веса сети — они изменяются в процессе обучения, и в них лежит обычно что-то категорически неисповедимое. Ну, кроме того, можно вспомнить, что процесс в CNN на самом деле разделён по слоям, и не происходит за одну свёртку-корреляцию, и что базовое применение CNN в задаче классификации, а не детектирования, так что она фактически — одно приложение фильтра к картинке, причём ко всей (но при этом у неё внутри много раз происходит свёртка). Так что, конечно, эта технология сложнее и интереснее, чем можно рассказать за один раз.
Наверное, ещё можно упомянуть специфику обучения CNN и вообще глубоких сетей. Долгое время было очень сложно с тем, чтобы обучать сети с большим количеством слоёв. Вообще для малых нейронных сетей вполне возможно рассчитать оптимальные веса по уравнению. Но с ростом числа слоёв (так как слои идут один за другим, и их веса друг от друга зависят), вычислительная сложность растёт. И, кроме того, в описании вклада нейронов последующих слоёв есть нормировочный член, который меньше единицы, с увеличением глубины слоя уменьшается с квадратичной скоростью. Из-за этого на определённой глубине веса «пробьют дно» машинной точности, и из-за этого применение численных методов вычисления ограничено. Поэтому глубокие сети обучают по-другому.
Я раньше думал —
книги делаются так:
пришёл поэт,
легко разжал уста,
и сразу запел, вдохновенный простак —
пожалуйста!
А оказывается —
прежде чем начнёт петься,
долго ходят, разомлев от брожения,
и тихо барахтается в тине сердца
глупая вобла воображения.
В.В. Маяковский,
поэма «Облако в штанах»,
фрагмент из начала 2 главы
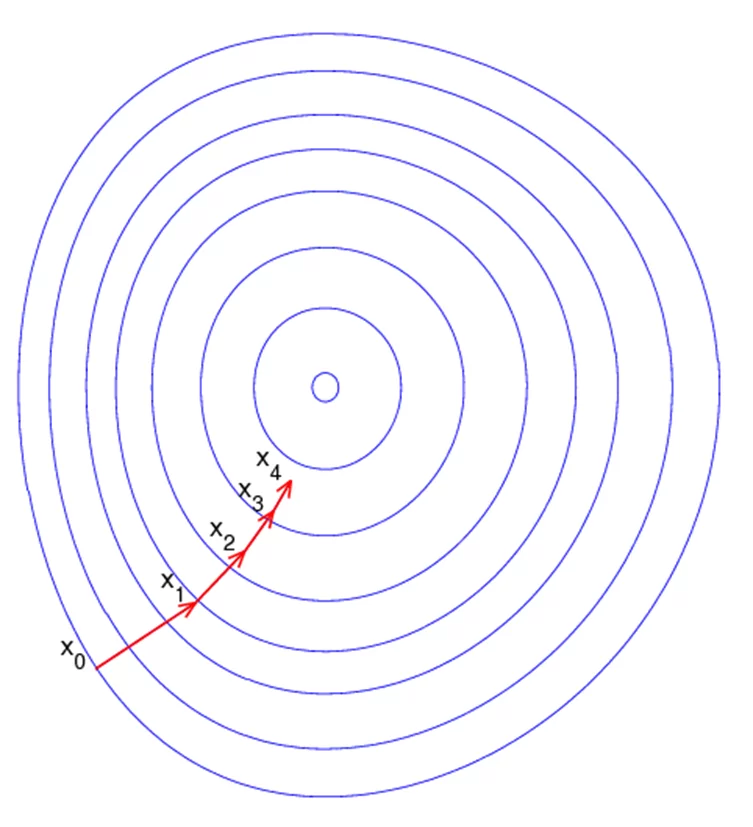
В случае нейронной сети вместо воблы барахтается градиентный спуск, и барахтается он не просто в тине, но по ужасающей, многомерной, очень-очень кривой поверхности. Поверхность эта — оценка ошибочности предсказания нейронки с разными настройками весов (фильтров). Поверхность имеет много холмов (повышений ошибки) и много ям (повышений точности). Нашей «вобле» нужно найти самую глубокую яму — эта яма будет в точке, координаты которой наиболее оптимальны для решения задачи. И двигаться по поверхности «вобла» будет небольшими шажками, чтобы повернее забуриться в какой-нибудь минимум функции ошибки. Но есть нюанс: минимум, который найдёт «вобла», может быть локальным — то есть не самым лучшим на всей поверхности, а просто ямкой. Обычный алгоритм градиентного спуска предполагает идти вниз и вниз, и с его помощью «вобле» не удастся вылезти из локального минимума обратно, чтобы найти минимум реальный. Это приводит порой к забавным артефактам, и есть разные методы, как сделать так, чтобы «вобла» не застревала где не нужно. Если любопытна эта тема, вот в этой статье на Википедии (https://ru.wikipedia.org/wiki/%D0%93%D1%80%D0%B0%D0%B4%D0%B8%D0%B5%D0%BD%D1%82%D0%BD%D1%8B%D0%B5 _%D0%BC%D0%B5%D1%82%D0%BE%D0%B4%D1%8B) есть немного слов, по которым можно поискать информацию.
И вот, когда она найдёт-таки настройки фильтров, которые устроят исследователя, получается результат — обученная нейронная сеть, которой можно просто дать картинку и получить ответ, котик это или стул. Обучать нейронную сеть долго, но работает она потом достаточно быстро и (чаще всего) хорошо.
Надеюсь, мои рассуждения помогли вам структурировать знания, а может, приобрести новые или хотя бы получить вдохновение их искать. Приятно иногда думать и говорить о внутренней математике чего-то сложного. Математика — это очень красиво и увлекательно!