/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
В настоящее время крупные компании, в том числе Банки хотят привлечь максимальное количество клиентов к себе, но анализировать вручную каждого клиента, чтобы предложить ему что-то – долго и нудно, поэтому эту задачу выполняют компьютеры.
Существует несколько схем коллаборативной фильтрации:
- Вычисляют тех, кто разделяет оценочные суждения выбранного человека. Используют оценки максимально похоже мыслящих людей, найденных на первом шаге (для построения прогноза).
- Сначала строят матрицу, определяющую отношения между парами предметов, для нахождения похожих. Используя построенную матрицу и информацию о человеке – строят прогноз.
(К сведению, второй способ был изобретен Amazon)
Также существует 3 основных типа коллаборативной фильтрации:
- Основанный на соседстве (подбор группы похожих людей)
- Основанный на модели (использует методы машинного обучения)
- Гибридный (объединяет первый и второй тип)
А теперь попробуем практически реализовать 1 тип на языке Python.
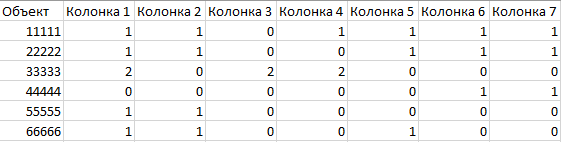
Для начала построения прогнозов нам необходим DataSet, где есть пользователи (объекты) и их параметры (возраст, пол и другие параметры), пример изображен на рисунке 1.
Первым шагом нам необходимо подключить библиотеку pandas, именно с помощью неё и будет реализован весь метод.
import pandas as pdВторым шагом мы загружаем в DataFrame наш DataSet (у меня он с именем test), также мы устанавливаем в качестве индекса нашу колонку с именем «Объект» и создаем новый DataFrame для рекомендаций.
recomendations=pd.DataFrame()
df=pd.read_excel('test.xlsx')
df=df.astype(str)
df=df.set_index('Объект').T
df.to_excel('DataSet.xlsx')
df=pd.read_excel('DataSet.xlsx',index_col=0)
recList=list()Третьим шагом мы перебираем все строки нашего DataFrame и для каждой находим один (можно и больше, если изменить переменную “k”) максимально похожий объект (также удаляем этот объект, чтобы исключить случай, что максимально похожий — будет он сам) и записываем его в рекомендации.
for row in df:
print(row)
k = 0 # Количество похожих объектов
corrMatr=df.corrwith(df[row])
corrMatr=pd.DataFrame(corrMatr)
tempMatr=corrMatr
tempMatr=tempMatr.drop([row],axis=0)
while k != 1:
name = tempMatr.idxmax().item()
value = tempMatr[0][tempMatr.idxmax().item()]
recList.append([row,name,value])
tempMatr=tempMatr.drop([tempMatr.idxmax().item()],axis=0)
k += 1
recomendations=recomendations.append(recList, ignore_index=True)
recomendations.to_excel('result.xlsx')В выходном файле, для примера, я вывел 3 колонки (рисунок 2):
- Выбранный объект
- Похожий объект
- Коэффициент схожести
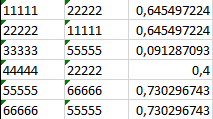
В итоге, мы нашли похожие объекты. Далее полученную информацию можно использовать уже по своему усмотрению. Например, искать пересечения обучающих курсов, книг, оценок, фильмов, музыки и рекомендовать только то, что нет у выбранного объекта, чтобы не советовать, что он уже прослушал или посмотрел и т.д.