/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 3 мин.
Что же такое Knowledge Graph? Это современная форма хранения и представления знаний определенной области, которая состоит из объектов и связей между ними, или другими словами данных и онтологии. Онтология – это подробная схема данных, схема некоторой предметной области, согласованная с экспертами в этой области. Под объектами мы понимаем множество взаимосвязанных объектов, которыми могут быть люди, места, организации или даже события. Мы можем представить эту схему в виде набора ребер и вершин. Давайте посмотрим на рисунок ниже.
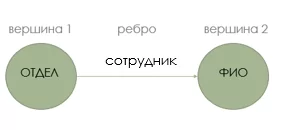
Вершина 1 и вершина 2 — это две разные сущности области организации. Эти узлы соединены ребром, которое представляет отношения между ними. Этот рисунок представляет собой наименьший граф знаний, который мы можем построить — он также известен как триплет. Графы знаний могут быть разных форм и размеров, а узлы могут быть связаны множеством ребер отношений. Новые ребра связности могут возникать не только из первого узла, но и из любой вершины в графе знаний, как показано на следующем рисунке:
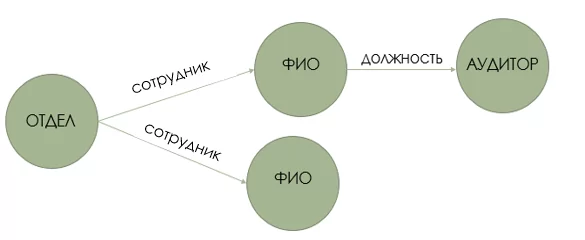
Здесь к графам даже не нужно давать пояснений ведь такое представление данных выгодно отличается от реляционного из-за наличия описания связей между объектами, так как в реальном мире связи порой имеют большее значение.
Как же нам сделать подобный граф знаний из неструктурированных данных? У нас имеется множество презентаций power point, которые хранят информацию о интересующей нас области знаний и перед нами стоит задача — как можно более подробно описать нашу область. Идентификация сущностей и отношения между ними — не сложная задача для человека. Однако создание графа знаний вручную не самая приятная работа. Никто не собирается просматривать множество документов и извлекать все сущности и связи между ними. Вот почему язык программирования python больше подходит для выполнения этой задачи, поскольку просмотр даже сотен или тысяч документов для него не проблема!
Открыть и извлечь текстовое содержимое из всех презентаций нам поможет библиотека python pptx.
from pptx import Presentation
pesentations = Presentation(path_to_presentation)
texts = []
for slide in pesentations.slides:
for shape in slide.shapes:
if not shape.has_text_frame:
continue
for paragraph in shape.text_frame.paragraphs:
for run in paragraph.runs:
texts.append(run.text)
После извлечения массива неструктурированных текстовых данных, нам следует разделить его в соответствии с составленной нами схемой данных. Тут нам поможет библиотека для поиска регулярных выражений re. C помощью написания нескольких функций, мы сможем разобрать данные и представить их в виде датафрейма, где сущностями будет содержимое ячеек, а связями наименование полей. Пример функции для извлечения текста с использованием регулярных выражений.
finded=[]
def find_text(data):
try:
finded=re.search("'ваше регулярное выражение",str(data)).group()
except:
finded=0
return finded
После извлечения всех необходимых для построения сущностей, вы можете создать триплеты данных и визуализировать их с помощью любого инструмента для построения графов, например NetworkX или Gephi.