/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Существует бесконечное множество статей и материалов о создании классификатора текстов. Сегодня я рассмотрю достаточно простой, но эффективных подход – это задача мультиклассовой классификации. Для данной задачи я буду использовать алгоритм SGDClassifier, так как он хорошо себя зарекомендовал для подобного рода задач.
Важно отметить, что датасет является лишь образцом (в нем не более 80 строк), а в идеале он должен состоять из нескольких тысяч строк, поэтому я буду использовать однотипные вопросы. И тем не менее ничто не мешает вам увеличить его собственноручно или подать на вход свои данные 😊
В силу того, что датасет не является большим, я не буду затрагивать аспекты сохранения модели, с последующей её загрузкой, так как модель обучится очень быстро и нет нужды её сохранять. Не стоит задерживаться на этом этапе, так как загрузка и сохранение моделей заслуживают отдельной истории, скажу лишь то, что если вы планируете использовать её для своих проектов с большим количеством данных, то в этом вам помогут библиотеки pickle или joblib.
Модель будет получать на вход какой-то вопрос, и, в свою очередь, должна его классифицировать. Например, если пользователь спросит: «В каком году отменили крепостное право», модель должна ответить «Дата». Она не будет отвечать на вопрос, а просто классифицирует вопрос в определенную категорию.
Алгоритм выполнения таков:
1. Загружаем датасет
2. Очищаем данные
3. Обучаем модель
4. Делаем выводы 😊
Итак, давайте посмотрим на часть моего импровизированного датасета:
Откуда готовилось нападение на Беларусь @ Местоположение
Где находится полярный круг @ Местоположение
Сколько стоит доллар @ Количество
Когда началась вторая Мировая @ Дата
В каком году была построена Эйфелева башня @ Дата
Сколько стоят помидоры @ Количество
Какой средний рост у баскетболистов @ Количество
Почему светит солнце @ Информация о предмете
Почему желтеют листья @ Информация о предмете
Как накопить на автомобиль @ Инструкция
Как открыть вино без штопора @ Инструкция
Кто создал радио @ Имя
Кто убил Марка @ Имя
Датасет представляет из себя простой текстовый файл, имеющий название 3.txt и с использованием кодировки UTF-8, где вопрос идет до знака @, а классификация указана после этого знака. Вы можете скопировать эти данные и проделать этот путь вместе со мной для лучшего понимания.
Плавно переходим к практике
Для работы я буду использовать среду google colab и по умолчанию в ней не установлена одна из необходимых библиотек – Pystemmer, сделать это можно командой pip install pystemmer или !pip install pystemmer.
Библиотека pystemmer строит морфологическую разметку, упрощая структуру понимания языка, что в свою очередь позволяет ускорить процесс необходимой работы, а также усовершенствовать свой запас словоформ. Пример в действии:

Далее импортирую библиотеки:
import numpy as np
import re
from Stemmer import Stemmer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import SGDClassifier
from sklearn.pipeline import Pipeline
from sklearn.metrics import classification_report
Создаю функцию для обработки текста
def cleaner(txt):
txt = txt.lower() # приведение букв в нижний регистр
stemmer = Stemmer('russian')
txt = ' '.join( stemmer.stemWords( txt.split() ) )
txt = re.sub( r'\b\d+\b', ' digit ', txt ) # заменяем цифры
return txt
Далее загружаю данные из файла 3.txt и разделяю этот датасет.
def load_data():
data = {'txt':[],'tag':[]}
for line in open('3.txt'):
if not('#' in line):
row = line.split("@")
data['txt'] += [row[0]] # вопрос
data['tag'] += [row[1]] # категория(ответ)
data['tag'] = [i.replace(’\n’, ’’) for i in data['tag']] # убираем ’\n’ (переходы между строками) для корректного отображения
return data
Подхожу к завершающей стадии подготовки датасета.
В этом блоке компьютер проходит по циклам и кладет списки в переменные X и Y. Validation_split – процент тренировочный данных, используемый для валидации. Как правило за стандарт берут от 20% (0.2) до 30%(0.3) при достаточном объеме данных, но в случае с малым количеством данных, достаточно будет и 10%(0.1). Используя интервалы, данные возвращаются в виде train и test
def train_test_split(data, validation_split = 0.1):
sz = len(data['txt'])
indices = np.arange(sz)
np.random.shuffle(indices)
X = [data['txt'][i] for i in indices]
Y = [data['tag'][i] for i in indices]
nb_validation_samples = int( validation_split * sz )
return {
'train': {'x': X[:-nb_validation_samples], 'y': Y[:-nb_validation_samples]},
'test': {'x': X[-nb_validation_samples:], 'y': Y[-nb_validation_samples:]}}
Теперь пора обучить модель и посмотреть результат. Я не буду вдаваться в глубокие математические вычисления и теоретическую базу, а обучу модель из “коробки”. В этом помогут библиотеки sklearn:TfidVectorizer(ссылка на документацию) для векторизации (так как машина понимает лишь цифры, нам необходимо перевести текст в векторные числа) и SGDClassifier(ссылка на документацию) – непосредственно сам алгоритм обучения. Обернём это в пайплайн (Pipeline выполняет, своего рода, роль класса, принимает настройки/преобразования) для большего удобства
def ai():
data = load_data()
D = train_test_split(data)
text_clf = Pipeline([
('tfidf', TfidfVectorizer(preprocessor = cleaner)),
('clf', SGDClassifier()),
])
text_clf.fit(D['train']['x'], D['train']['y'])
y_pred = text_clf.predict(D['test']['x'])
stats = classification_report(D['test']['y'],y_pred)
a = input("Введите интересующий вас вопрос: ")
aa = []
aa.append(a)
y_pred = text_clf.predict(aa)
print(y_pred[0])
print(stats)
ai()
Запущу ячейку с функцией, на что компьютер предлагает ввести вопрос, параллельно выведя метрику данной модели
Вопросом будет — ‘Сколько вешать в граммах’, параллельно выведя показатели метрик, стоит отметить, что не важно будет ли вопрос в конце предложения или нет.
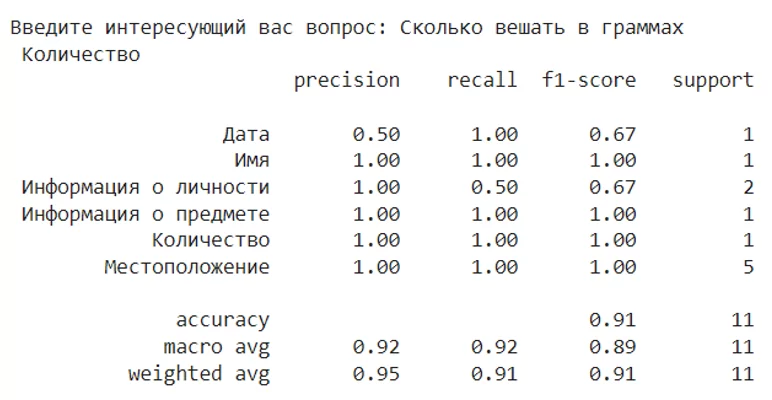
Как можно заметить, модель безошибочно классифицировала данный вопрос, которого не было в датасете, и это при том, что использовался лишь малый набор данных для обучения модели. Модель достаточно хорошо себя показывает на базовом уровне, и нет необходимости углубляться в градиентный спуск, оптимизацию гиперпараметров и другие тонкости машинного обучения, однако принято считать, что на фоне других классификаторов из ‘коробки’, может работать чуть хуже своих конкурентов. Классификатор SGDClassifier имеет преимущество на больших наборах данных в силу быстрой обучаемости. Данную модель можно применять для дальнейшей разметки в автоматическом режиме, что экономит сотни человеко-часов.