/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Немного теории
TF-IDF — применяется для анализа значимости слова в документе,который является частью большой коллекции документов либо корпуса. Мы сталкиваемся с задачами, где необходимо проанализировать или найти нужной информации в тексте. Для решения практически всегда используем статистическую меру – TF-IDF.
TF (или частота слова) – это отношение количества употреблений какого-либо слова к совокупному количеству слов документа. Следовательно, анализируется значимость слова ti в одном отдельном документе.
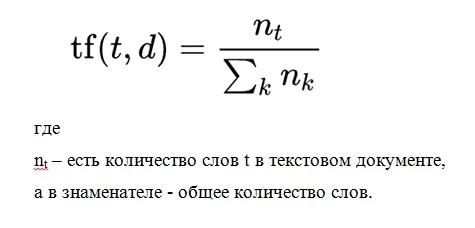
IDF — это обратная частотность документов, с которой какое-либо слово упоминается в документах коллекции. Для любого уникального слова в пределах точной коллекции документов присутствует одно значение IDF.
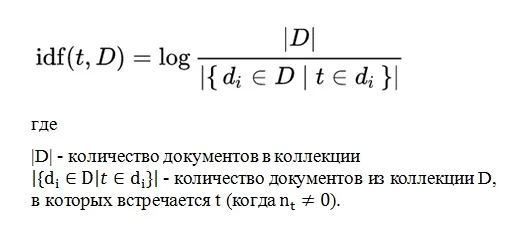
Мы видим, что TF-IDF считается произведением двух выражений:
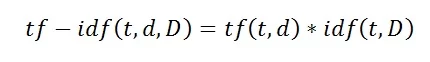
Больший вес в рамках одного документа в TF-IDF имеют слова с высокой частотой и с невысокой частотой использования в иных документах.
Практика
Применим вышеизложенный материал на практике. Задача состояла в сравнении двух текстов между собой. Нам необходимо было осуществить поиск похожих сообщений пользователей.
Для решения задачи потребуются следующие библиотеки:
from sklearn.feature_extraction.text import TfidfVectorizer,CountVectorizer — из этой большой библиотеки sklearn нам необходимо 2 модуля для расчета частоты слов (TfidfVectorizer) и количества слов (CountVectorizer)
from scipy.spatial import distance — предназначенная для выполнения научных и инженерных расчётов, из нее мы будем брать модуль distance для расчета косинусного расстояния.
import pandas as pd – служит для обработки и анализа данных
import regex as re – данная библиотека позволяет использовать регулярные выражения
import docx – библиотека для чтения docx файлов
Далее необходимо создать пару функций:
Из .docx файла получить уже очищенные предложения от мусора (цифры, знаки препинания и так далее)
def convert(doc):
text=[]
for i in doc:
mas=[]
mas=i.split('.')
for j in mas:
if j!='':
j=re.sub(r'[^\pL\p{Space}]', '', j.strip().lower()).replace(' ',' ')
text.append(j)
return text
Для сбора уникальных предложений в двух сравниваемых текстах:
def add_sugg(doc1,doc2):
all_mas=[]
for i in doc1:
if i in all_mas:
continue
else:
all_mas.append(i)
for j in doc2:
if j in all_mas:
continue
else:
all_mas.append(j)
return all_mas
- Расчет косинусного расстояния.
def dist(x,y):
return distance.cosine(x,y)
После описания функций можно их использовать и читать текст с документа. Для дальнейшей работы необходимо собрать все уникальные предложения. Далее разложить их на слова в каждом из них, и каждому дать свой номер, это и будет наш токинайзер. Эти числа и будем применять на исходные файлы docx. и сравнивать вектора между собой.
doc1 = [p.text for p in docx.Document('1.docx').paragraphs]
doc2 = [p.text for p in docx.Document('2.docx').paragraphs]
text1=convert(doc1)
text2=convert(doc2)
all_mas=add_sugg(text1,text2)
Так же я создал docx документ, куда внес собственные стоп слова, это пригодится для дальнейшей обработки текста — удаления ненужной информации.
stop_word = [p.text.lower() for p in docx.Document('стоп слова.docx').paragraphs]Далее отчистим общий набор уникальных предложений для удаления стоп слов.
tfidfvectorizer = TfidfVectorizer(analyzer='word',stop_words=s_word)Следующим шагом будет обучение модели уже по отчищенным словам.
tfidf_wm = tfidfvectorizer.fit(all_mas)И заключающий шаг преобразования — это применение модели на исходные тексты, для это необходимо применить модель к тесту.
text1_idf = tfidf_wm.transform(text1)
text2_idf = tfidf_wm.transform(text2)
Для удобства работы будем использовать pandas. В него запишем все полученные вектора
df_tfidfvect1 = pd.DataFrame(data = text1_idf.toarray(),columns = tfidf_tokens)
df_tfidfvect2 = pd.DataFrame(data = text2_idf.toarray(),columns = tfidf_tokens)
Посмотрим что получилось.
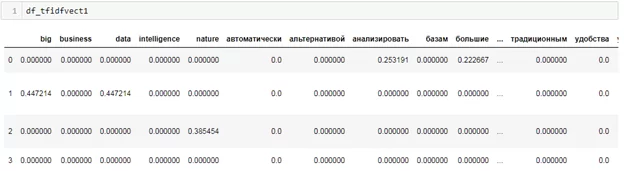
На выходе мы получили вектор их всех уникальных слов. В разбивке на частоту в каждом предложении.
Для удобства сделаем массив всех строк и запишем в новую колонку
df_tfidfvect1['combine'] = df_tfidfvect1.values.tolist()
df_tfidfvect2['combine'] = df_tfidfvect2.values.tolist()
Сделаем cross join что бы сравнить каждый вектор с каждым.
df_tfidfvect1['key'] = 0
df_tfidfvect2['key'] = 0
df_all = pd.merge(df_tfidfvect1, df_tfidfvect2, on='key')
Для наглядности создадим Dataframe, чтобы не плодить множество колонок.
df=pd.DataFrame()
df['x']=df_all['combine_x']
df['y']=df_all['combine_y']
df['dist']=df.apply(lambda x: dist(x['x'],x['y']),axis=1)
И отобразим только те вектора, у которых уникальность предложений менее 50%.
df.where(df['dist']<=0.5).dropna()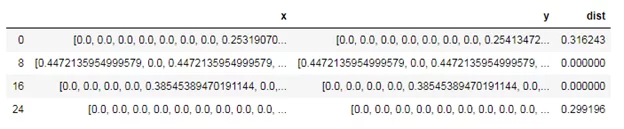
Таким несложным образом можно реализовать простую идею сравнения любых текстов. В дальнейшем использование данного шаблона позволит реализовать различные идеи. Например, привести слова в нормальную форму, кластеризовать комментарии, найти отклонения в теме форума, и так далее.