/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Многие сталкивались с проблемами в работе инструментов для управления базами данных. То графический интерфейс долго загружается, то зависает в самый ненужный момент, или просто нет нормальной возможности выгрузить результат в файл. Основные проблемы связаны с нагромождением дополнительного функционала, который в большинстве случаев не нужен.
При работе с СУБД GreenPlum или PostgreSQL, как правило, в качестве инструментов управления базами данных используют pgAdmin или Dbeaver. Это хорошие и универсальные инструменты, однако, за универсальность приходится платить скоростью запроса к БД и работой приложения в целом.
Я расскажу, как зная SQL и десяток консольных команд, можно значительно ускорить выполнение запросов в GreenPlum с помощью PSQL.
PSQL — это терминальный клиент для работы с PostgreSQL. Он позволяет вводить запросы в интерактивном режиме, отправлять их в PostgreSQL и просматривать результаты запроса. Так как GreenPlum основан на PostgreSQL, то PSQL работает и с ним.
Устанавливается PSQL при установке PostgreSQL — называется Command Line Tools, в случае Greenplum PSQL устанавливается с pgAdmin. Для его запуска надо открыть командную строку в папке с psql.exe (например, при установке PostgreSQL путь PostgreSQL\14\bin\psql.exe). C PSQL можно работать в двух режимах:
- интерактивный
- из командной строки (не интерактивный)
Оба режима доступны из командной строки. Отличие в том, что в интерактивном режиме подключиться к БД надо один раз в начале, а дальше уже писать SQL-запросы. Не интерактивный режим больше подходит для одиночного запроса, который удобно записать в одну строку, указав в ней и подключение, и сам запрос.
Пример команды по созданию таблицы в неинтерактивном режиме (в командной строке) выглядит так:
psql –h имя_хоста -U имя_пользователя -d имя_бд -c «CREATE TABLE my(some_id int, some_text text)
Далее приведу примеры в интерактивном режиме. Для его открытия надо выполнить команду PSQL и ввести запрашиваемые параметры, такие как: имя хоста (сервера), логин и пароль пользователя, название БД. После этого командная строка перейдет в интерактивный режим.
Пример: psql –h имя_хоста -U имя_пользователя -d имя_бд
Теперь можно вводить команды SQL:
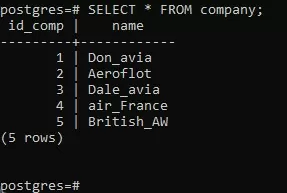
Для выхода из интерактивного режима использую команду: \q
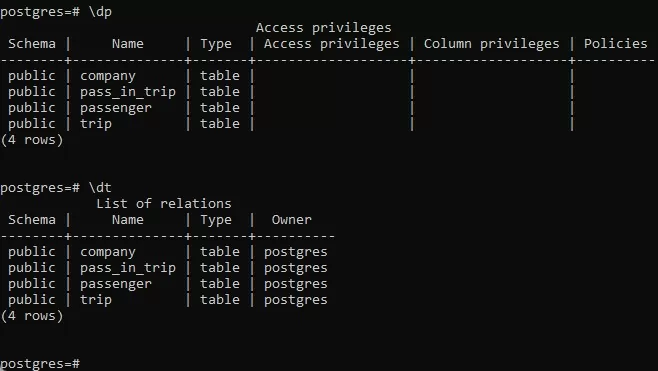
Помимо отправки SQL-запросов нужно ознакомиться со структурой базы и ее таблиц, для этого подойдет ряд команд:
- \dt – список таблиц
- \dt+ — список таблиц с описанием
- \dp (или \z) – список таблиц, представлений, последовательностей, прав доступа к ним
- \dv – представления
- \l – список баз данных
- \d “table_name” – описание таблицы
- \help – справочник SQL
Данные команды выводят информацию о структуре в виде таблицы:
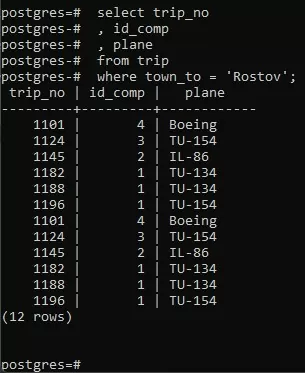
Каждый SQL-запрос должен заканчиваться точкой с запятой, если ее нет, то запрос не выполнится, а просто переведет строку:
Вводить запросы и получать результаты в командной строке, конечно, неудобно, поэтому есть команды, позволяющие работать с файлами:
- \o – пересылка результатов запроса в файл
- \i – читать входящие данные из файла
- \copy — копирует данные
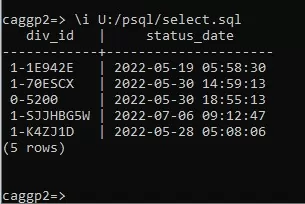
Для применения команды \i надо после нее указать ссылку на файл с запросом. В файле select.sql указана команда “select div_id, status_date from table limit 5;”. Без кавычек, также с указанием точки с запятой в конце.
Отдельного внимания заслуживает команда \copy, она позволяет решать такие важные задачи, как экспорт и импорт данных между БД и csv файлом.
Экспорт данных в файл.
Команда \copy имеет ограничение в том, что должна выполняться в одну строку, из-за этого не получится вставить в нее многострочный запрос. Для решения этой проблемы можно создать временное представление и записать запрос в него, а в команде copy вывести все из представления.
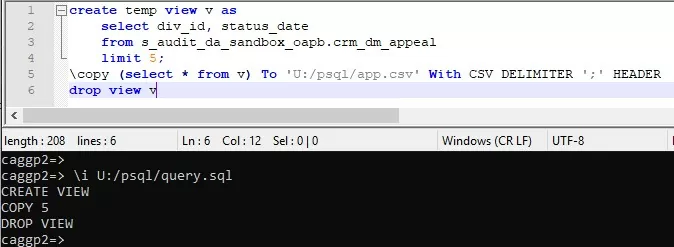
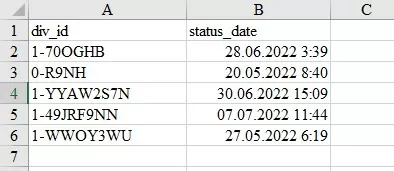
Импорт данных из файла.
Перед тем как записать данные из файла в таблицу надо сначала ее создать. Команда DISTRIBUTED by входит в синтаксис создания таблиц в GreenPlum.
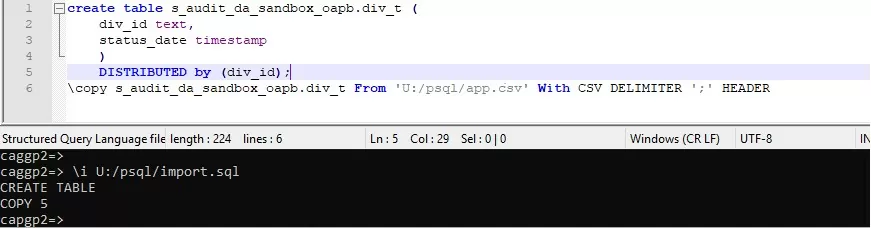
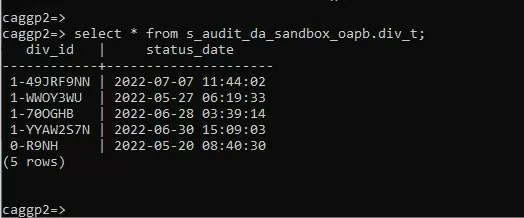
Разберу практический кейс по переносу данных с Hadoop на GreenPlum через pxf сервер. Это можно сделать через внешнюю таблицу (external table) в GreenPlum, которая запрашивает данные хранящиеся в Hadoop. После чего данные можно записать в обычную таблицу.
Для начала надо создать внешнюю таблицу:
CREATE EXTERNAL TABLE caggp2.s_audit_da_sandbox_oapb.ext_st_crm_appeal (
row_id text
, app_num text
, created_date timestamp
, party_id text
, party_lname text
, party_fname text
, party_mname text
, birth_dt timestamp
, status text
, created_by text
)
LOCATION (
'pxf:///user/team/team_audit_oapb/hive/s_crm_appeal?PROFILE=hdfs:parquet&SERVER=audit_da_sandbox'
) ON ALL
FORMAT 'CUSTOM' ( FORMATTER='pxfwritable_import' )
ENCODING 'UTF8';
Структуру исходной таблицы можно взять с помощью команды describe в hive. Так как некоторые названия типов данных в Hadoop и GreenPlum не совпадают, надо их переименовать, в моем случае сменить string на text.
В разделе LOCATION (вывода команды describe в hive) указывается ссылка на таблицу в Hadoop, а также сам pxf сервер. Точный синтаксис ссылки зависит от настроек конкретного кластера.
Теперь создаю таблицу для материализации данных с той же структурой и нужными параметрами сжатия и распределения (особенности создания таблиц в GreenPlum):
CREATE TABLE s_audit_da_sandbox_oapb.st_crm_appeal (
row_id text
, app_num text
, created_date timestamp
, party_id text
, party_lname text
, party_fname text
, party_mname text
, birth_dt timestamp
, status text
, created_by text
)
WITH (
appendonly=true,
compresstype=zstd
)
DISTRIBUTED BY (row_id);
Теперь остается выполнить только запись данных из внешней таблицы в обычную:
insert into s_audit_da_sandbox_oapb.st_crm_appeal
select * from s_audit_da_sandbox_oapb.ext_st_crm_appeal;
Время выполнения этой команды в Dbeaver составило 5 минут:
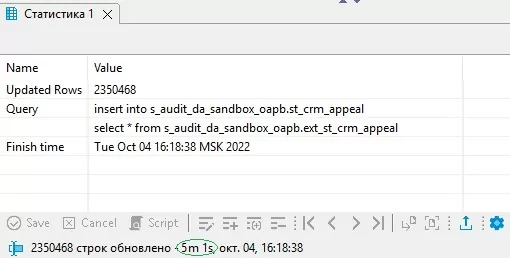
А в PSQL 15 секунд:


При сравнении скорости выполнения одинаковых запросов в Dbeaver и PSQL, скорость выполнения второго значительно быстрее.
Так же в PSQL является полезным то, что он работает из командной строки, которая легко интегрируется с другими системами и языками программирования.
Инструмент PSQL с первого взгляда кажется неудобным из-за отсутствия графического интерфейса, однако выигрывает в другом. К сильным качествам PSQL можно отнести:
- Скорость выполнения запроса
- Экспорт и импорт одной командой
- Возможность автоматизировать выполнение скриптов.