/img/star (2).png.webp)






/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 6 мин.
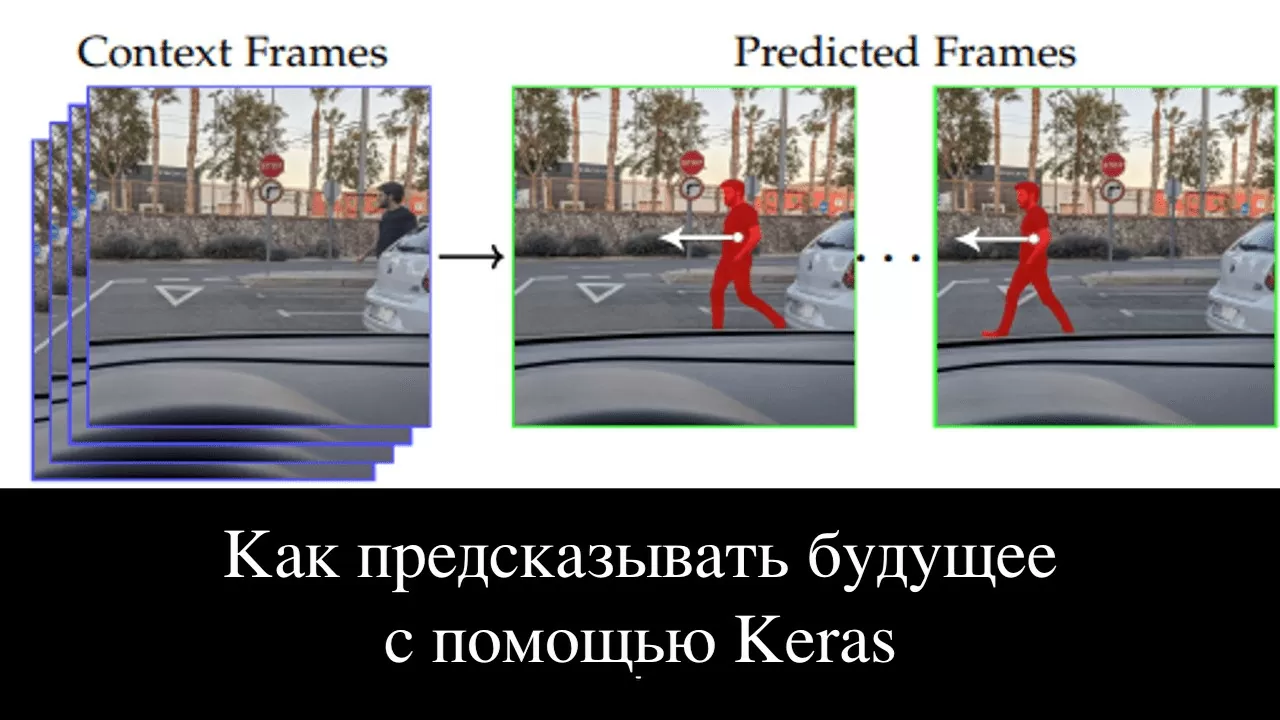
Представьте себе автомобиль с автопилотом, движущийся по дороге, на видеокамеру авто подается видеосигнал, состоящий из последовательности кадров – дорога, прилегающая территория, остальные участники дорожного движения. Предсказывание будущего кадра поможет решить, когда следует притормозить, ехать медленнее или, наоборот, увеличить скорость в режиме реального времени.
Задача предсказания следующего фрагмента видео называется «Предсказание следующего кадра». Суть подобных задач состоит в том, чтобы построить модель, которая изучит неочевидные закономерности в этой последовательности кадров, а затем использует их для предсказания будущего кадра. Стоит также упомянуть, что видео представляет собой пространственно-временную последовательность, что означает наличие пространственных и временных корреляций, которые также необходимо установить, чтобы успешно предсказать кадр.
Сама идея того, что с помощью машинного обучения можно предсказывать видео, по моему мнению, является очень интересной темой для исследования. Это весьма полезное умение как для любых машин на автопилоте, так и для программных роботов.
В этой статье мы сделаем первые шаги в предсказании кадров, используя реализацию ConvLSTM в модуле Keras, который является частью библиотеки Tensorflow.
Если очень коротко, то convLSTM выделяет самые важные признаки в кадре, а все прочие «забывает», использует несколько фильтров для отбора информации, которая потребуется нам в дельнейшем.
Если данную тему разбирать подробнее, то стоит начать с блока LSTM. LSTM является подвидом рекуррентной нейронной сети или RNN. Все RNN имеют цепную форму повторяющихся модулей нейронной сети. В стандартной RNN этот повторяющийся структурный модуль имеет очень простую структуру — слой tanh. Каждый элемент выходных данных (который является вектором) представляет собой действительное число от 0 до 1, называемый весом (или пропорцией), позволяющий передавать соответствующую информацию. Например, 0 означает «не пропускать никакой информации», а 1 означает «пропускать всю информацию».
LSTM реализует защиту и контроль информации с помощью трех базовых структур: входных ворот, ворот забывания и выходных ворот.
Видео — это пространственно-временная последовательность, и, хотя приведенная выше архитектура LSTM очень эффективно обрабатывает временные корреляции, она не может хорошо передавать пространственную информацию, поскольку вход, скрытые состояния, ячейки и ворота — это одномерные векторы.
В таком случае предлагается блок ConvLSTM, который добавляет свертку на каждые из трех ворот, и тогда вместо прямого умножения используется матричное. Таким образом, это позволяет работать с многомерными векторами данных, к примеру, с изображениями.
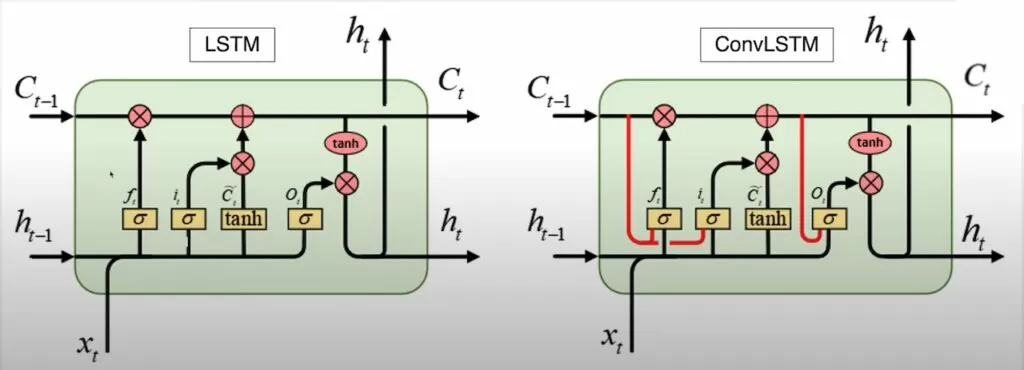
На изображении можно увидеть, как добавляются слои свертки к обычной LSTM ячейке.
В этой статье мы будем использовать набор данных Moving MNIST: популярный датасет с двигающимися цифрами. Примечательно, что цифры двигаются не случайно, а следуя физике, например, отталкиваются от краев.
Если упоминать требования к видео, то не стоит брать для обучения те, в которых очень мало движения между кадрами, иначе сеть обучится некорректно и предсказания будут далеки от реальности.
Мы загрузим набор данных, а затем создадим и предварительно обработаем обучающую и тестовую выборки.
indexes = np.arange(dataset.shape[0])
train_index = indexes[: 900]
val_index = indexes[900 :]
train_dataset = dataset[train_index]
val_dataset = dataset[val_index]
train_dataset = train_dataset / 255
val_dataset = val_dataset / 255
Для предсказания следующего кадра модель будет использовать предыдущий кадр, который мы назовем f_n, для предсказания нового кадра, называемого f_(n + 1). Чтобы модель могла создавать эти предсказания, выборку нужно сдвинуть на один кадр назад для предсказания кадра y_(n + 1).
def create_shifted_frames(data):
x = data[:, 0 : data.shape[1] - 1, :, :]
y = data[:, 1 : data.shape[1], :, :]
return x, y
x_train, y_train = create_shifted_frames(train_dataset)
x_val, y_val = create_shifted_frames(val_dataset)
Таким образом, мы имеем 1000 изображений с 20 кадрами на видео размерности 64х64, что, на первый взгляд, весьма немного, но, как это отразится на параметрах модели — мы узнаем позже.
Давайте посмотрим на наши наборы.

Следующим шагом создаем новые слои.
Слой convLSTM2D похож на слой LSTM, но входные и рекуррентные преобразования проходят через свертку.
Слой convLSTM3D применяет свертку для сжатия данных, в нашем случае мы используем это для свертки временной последовательности количества кадров, а также ширины и высоты.
inp = layers.Input(shape=(None, *x_train.shape[2:]))
x = layers.ConvLSTM2D(
filters=64,
kernel_size=(5, 5),
padding="same",
return_sequences=True,
activation="relu",
)(inp)
x = layers.BatchNormalization()(x)
x = layers.ConvLSTM2D(
filters=64,
kernel_size=(3, 3),
padding="same",
return_sequences=True,
activation="relu",
)(x)
x = layers.BatchNormalization()(x)
x = layers.ConvLSTM2D(
filters=64,
kernel_size=(1, 1),
padding="same",
return_sequences=True,
activation="relu",
)(x)
x = layers.Conv3D(
filters=1, kernel_size=(3, 3, 3), activation="sigmoid", padding="same"
)(x)
model = keras.models.Model(inp, x)
model.compile(
loss=keras.losses.binary_crossentropy, optimizer=keras.optimizers.Adam(),
)
После прохождения всех слоев в результате создается один кадр 64х64. Стоит отметить, что модель содержит более 746 000 параметров, и это только для черно-белых изображений с низким разрешением (64х64), так что не сложно представить сколько вычислительной мощности может потребоваться для предсказания кадров более высокого разрешения.

Обучаем модель
epochs = 20
batch_size = 5
model.fit(
x_train,
y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_val, y_val),
callbacks=[early_stopping, reduce_lr],
)
Теперь, когда наша модель построена и обучена, мы можем сгенерировать несколько примеров предсказания кадров на основе видео из тестовой выборки.
Выбираем случайный пример, а затем, берем из него 10 первых кадров. После этого мы даем модели предсказать 10 новых кадров, которые сравниваем с реальными данными.
# Предсказываем 10 кадров на основе первых 10
for _ in range(10):
new_prediction = model.predict(np.expand_dims(frames, axis=0))
new_prediction = np.squeeze(new_prediction, axis=0)
predicted_frame = np.expand_dims(new_prediction[-1, ...], axis=0)

И, наконец, выбираем несколько примеров из тестового набора и создаем с их помощью несколько GIF, чтобы увидеть предсказанные моделью видеоролики.
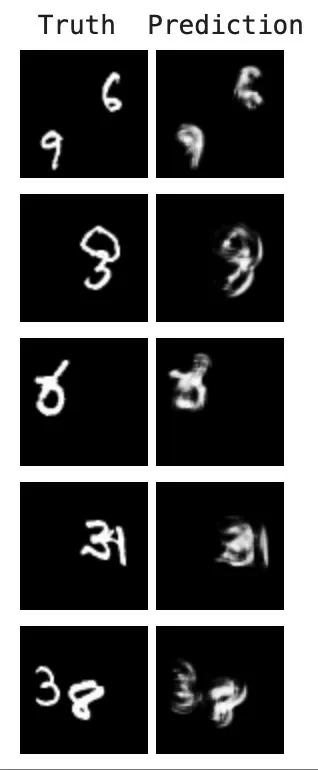
Итак, в результате мы получили модель, которая может предсказывать кадры видео с достаточной точностью, учитывая объем обрабатываемых данных. В дальнейшем точность модели можно улучшить, увеличив объем обучающей выборки и количество эпох обучения. Но для этого потребуется и дополнительные вычислительные мощности или время!
Полный код представлен здесь.