/img/star (2).png.webp)






/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 9 мин.
Задача состоит в распознавании повреждений дорожного покрытия. Общая дорожная сеть Российской Федерации – 1,5 млн. км, из которых примерно 75% – дороги общего пользования. При этом около 65% таких дорог имеют твердое покрытие, однако, 55% из них не соответствуют нормативным требованиям. Иными словами, большинство национальных дорог содержит различные дефекты, и это становится серьезной опасностью как для владельцев транспортных средств, так и для самого транспорта, а также для пешеходов.
Автоматизация распознавания повреждений дорожного покрытия могла бы помочь инженерам лучше обслуживать дороги, поскольку процессы обнаружения и локализации станут проще, и выявленные проблемные участки будут доступны в виде изображений, хранящихся в базе данных. Таким образом, будет обеспечено надлежащее и своевременное планирование ремонта дорог, что снизит негативные последствия, вызванные плохим состоянием покрытий, таких как аварии, пробки и повреждения автомобилей.
Для решения задачи был использован набор данных от компании Mendeley, состоящий из изображений бетонного покрытия, половина из которых содержит дефекты дорожного полотна. Набор данных состоит из 40000 изображений размером 227 × 227 пикселей и разделен на две части: «отрицательные» (не содержащие дефектов) и «положительные» (с дефектами) изображения бетона, по 20 000 цветных (RGB) изображений для каждого класса. Датасет сгенерирован из 458 изображений с высоким разрешением (4032×3024 пикселя). Аугментация изображений не производилась, так как этого количества данных хватит для обучения модели. Таким образом, для распознавания дефектов необходимо решить задачу бинарной классификации.
Примеры положительного и отрицательного изображения из итогового набора приведены на рисунках 1 и 2 соответственно.
Успешные результаты архитектур сверточных нейронных сетей VGG, ResNet и EfficientNet определили их выбор в качестве основных методов глубокого обучения для сравнительного анализа в контексте решаемой задачи. Поскольку необходимо найти наиболее точное и эффективное с точки зрения времени выполнения и памяти решение, используемые модели должны быть достаточно легковесными. Среди вышеперечисленных архитектур модификации VGG-16 и ResNet-50 используют меньшее количество памяти среди других моделей в своем классе и при этом обеспечивают приемлемую точность в качестве классификаторов дефектов дорожного полотна. Кроме того, также была рассмотрена модель EfficientNet-B5. В качестве входных данных каждая из моделей сверточной нейронной сети принимает тензоры вида «высота изображения, ширина изображения, каналы цвета». Цветовое пространство – RGB. Размерность – (120, 120, 3), где высота изображения – 120, ширина изображения – 120, каналов цвета – 3.
Все модели обучались в течение 5 эпох с размером мини-выборки в 100 экземпляров. Такое малое количество эпох выбрано для недопущения переобучения модели, так как обучение происходит на изображениях бетона, но модели также хотелось бы использовать и на фотографиях асфальта. При переобучении модель слишком сильно будет привязана к изначальному датасету и будет сбоить при использовании на отличающихся данных. В качестве основной метрики для оценки использовалась accuracy (точность, или доля объектов, на которых модель выдает корректные метки классов, то есть показатель правильно классифицированных объектов в наборе данных).


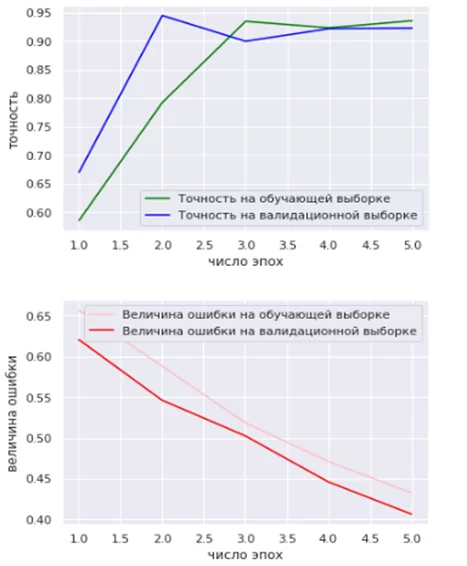
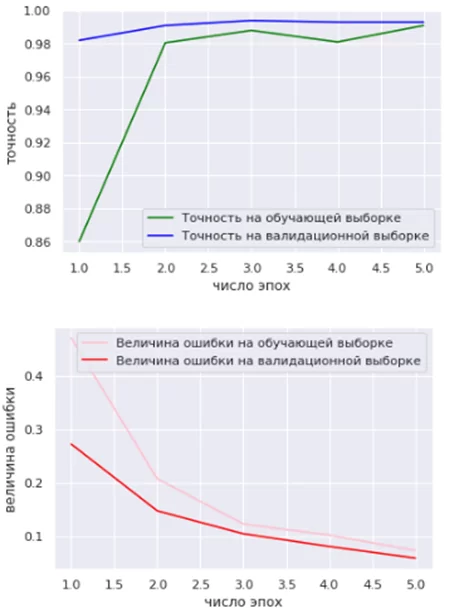
На рисунках 3 – 5 приведены графики изменения точности и потерь для каждой из моделей с ростом числа эпох.
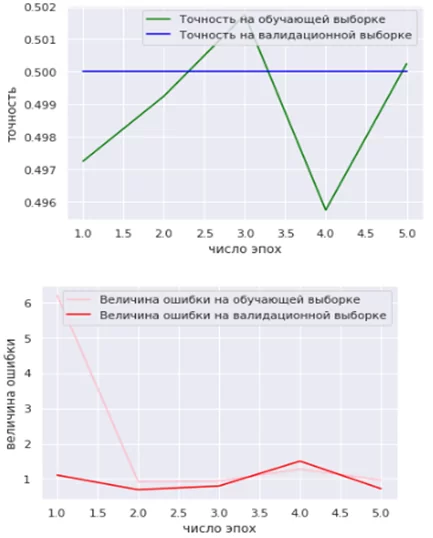
Несмотря на снижение величины ошибки и увеличение точности распознавания на обучающей выборке, на валидационном наборе данных модель EfficientNet-B5 демонстрирует незначительные изменения. Низкие значения accuracy говорят о том, что такая архитектура не подходит для решения данной задачи.
Модели ResNet-50 и VGG16 дают высокие результаты уже после первых итераций обучения (доля правильно классифицируемых объектов в случае с ResNet-50 превышает 90% уже после трех итераций, для VGG16 – после двух). Величина ошибки для обеих моделей снижается с ростом числа эпох.
Рисунок 6 иллюстрирует результат сравнения моделей по критерию точности (метрике accuracy).
Модель VGG16, показавшая лучший результат, была сохранена в отдельный файл для дальнейшего использования в пользовательском приложении (мобильное или веб-приложение может быть реализовано как автономный модуль полноценной системы распознавания дефектов дорожного полотна, позволяя определить наличие повреждений на переданном ему входном изображении). Для этого нейросетевой фреймворк Keras предоставляет средства, позволяющие сохранить архитектуру модели, веса и отслеживаемые подграфы библиотеки Tensorflow, чтобы затем восстановить как встроенные слои, так и пользовательские объекты.
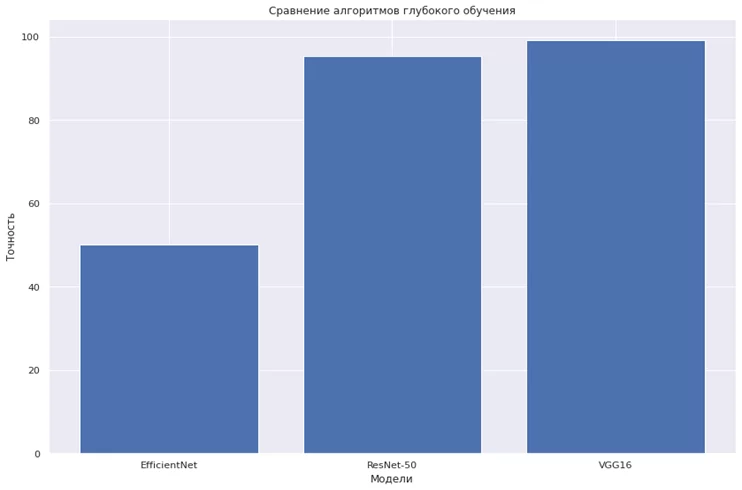
Несмотря на успех моделей глубокого обучения, достигнутый при решении поставленной задачи распознавания дефектов дорожного покрытия на изображениях, полученное решение также имеет недостатки. В частности, размер сохраненной предварительно обученной модели VGG16 на наборе данных превышает 50 МБ, что может быть критичным как с точки зрения памяти (при использовании в мобильном приложении), так и времени отклика (получение результата при помощи модели займет длительное время из-за большого количества слоев и тяжеловесной архитектуры). Кроме того, точность этой модели с округлением до целого составляет 99%, поэтому можно говорить о том, что такой результат еще может быть улучшен. Создание нового метода распознавания дефектов дорожного полотна на основе глубокого обучения позволит превзойти по точности распознавания и затратам памяти существующие модели.
Итоговая схема новой предложенной модели приведена на рисунке 7. Модель обучалась в течение 5 эпох, как и предыдущие тестируемые предварительно обученные модели. Точно так же она была скомпилирована с оптимизатором Adam и категориальной кросс-энтропией в качестве функции потерь. Accuracy модели на обучающей выборке – 99,7%, на тестовой – 99,8 с величиной ошибки (loss), равной 0,01.
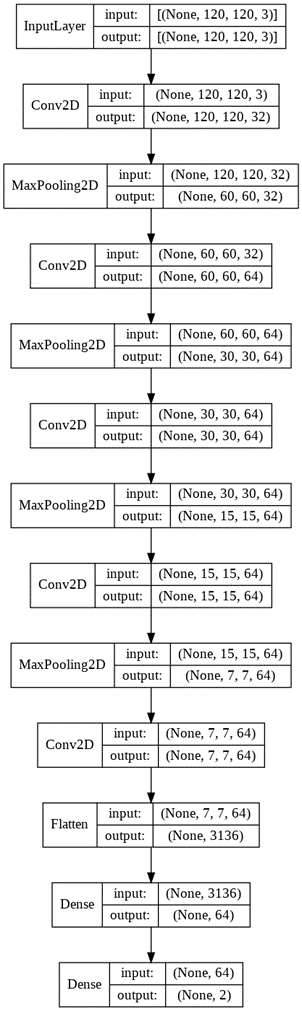
Программный код для создания, обучения и тестирования модели приведен в листинге 1.
Листинг 1. Создание новой модели сверточной нейронной сети
model = models.Sequential()
model.add(layers.Conv2D(32, kernel_size=(3, 3), padding="same", activation='relu', input_shape=(120, 120, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), padding="same", activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), padding="same", activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), padding="same", activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), padding="same", activation='relu'))
# вывод информации о модели
model.summary()
## Добавление полносвязных слоев
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(2, activation='softmax'))
model.summary()
# визуализация построенной модели
from tensorflow.keras.utils import plot_model
plot_model(model, to_file='model_image.png', show_layer_names=False, show_shapes=True)
## Компиляция и обучение модели
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
### Обучение модели
history = model.fit(train_data, validation_data = val_data, batch_size=64, epochs=5)
(ls, acc) = model.evaluate(test_data)
print('Точность модели = {} %'.format(acc * 100), '. Величина ошибки = {} %'.format(ls * 100))
Сравнение предложенной модели по точности правильно классифицированных объектов (accuracy) и величине потерь (loss) с ранее рассмотренными моделями приведено в таблице 1. Жирным шрифтом в таблице отмечены лучшие показатели.
| Название модели глубокого обучения | accuracy, % | loss |
| EfficientNet-B5 | 50 | 0,72 |
| ResNet-50 | 92,3 | 0,4 |
| VGG16 | 99,3 | 0,05 |
| Новая модель | 99,8 | 0,01 |
Таким образом, лучшие результаты достигаются с использованием новой модели глубокого обучения. Это модель на основе сверточной нейронной сети, использующая общий подход, лежащий в основе VGG16 (чередование слоев свертки и пулинга). Точность этой модели с округлением до целого составляет 100%. Размер файла модели не превышает 4 МБ, что позволяет использовать ее в качестве легковесного классификатора дефектов на изображениях и видеокадрах в реальном времени не только в веб-, но и в мобильных приложениях.
Библиотека Streamlit позволяет реализовать интерактивное веб-приложение для тестирования модели сети. Код пользовательского приложения с тестированием новой предложенной модели приведен в листинге 2.
Листинг 2. Код файла app.py (пользовательского приложения)
import numpy as np
import PIL
import tensorflow as tf
from tensorflow import keras
import streamlit as st
import cv2
from keras.layers import Input, Lambda, Dense, Flatten
from keras.models import Model
from keras.applications.vgg16 import VGG16
from keras.applications.vgg16 import preprocess_input
from keras.preprocessing import image
from keras.preprocessing.image import ImageDataGenerator
from glob import glob
class_names = ['дефекты не найдены!', 'дефекты найдены!']
@st.cache(allow_output_mutation=True)
def load_model():
model=tf.keras.models.load_model('model.h5')
return model
with st.spinner('Модель загружается..'):
model=load_model()
html_temp = '''
<div style='background-color:#1DB4AC ;padding:10px'>
<h2 style='color:yellow;text-align:center;'>Распознавание дефектов дорожного полотна</h2>
</div>
'''
st.markdown(html_temp, unsafe_allow_html=True)
file = st.file_uploader('Пожалуйста, загрузите изображение в формате *.jpg/*.jpeg/*.pdf/*.png',
type=['jpg','jpeg','pdf','png'])
import cv2
from PIL import Image, ImageOps
st.set_option('deprecation.showfileUploaderEncoding', False)
def import_and_predict(image_data, model):
size = (120,120)
image = ImageOps.fit(image_data, size, Image.ANTIALIAS)
image = np.asarray(image)
img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
img_reshape = img[np.newaxis,...]
prediction = model.predict(img_reshape)
return prediction
if file is None:
st.text('Пожалуйста, загрузите изображение в формате *.jpg/*.jpeg/*.pdf/*.png')
else:
image = Image.open(file)
st.image(image, use_column_width=True)
if st.button('Распознавание'):
predictions = import_and_predict(image, model)
score=np.array(predictions[0])
st.write(score)
st.title(
'Результат: {}'
.format(class_names[np.argmax(score)])
)
Рисунки 8 и 9 иллюстрируют результаты распознавания дефектов дорожного полотна для загруженного пользователем изображения с использованием веб-приложения. Распознавание выполняется корректно.
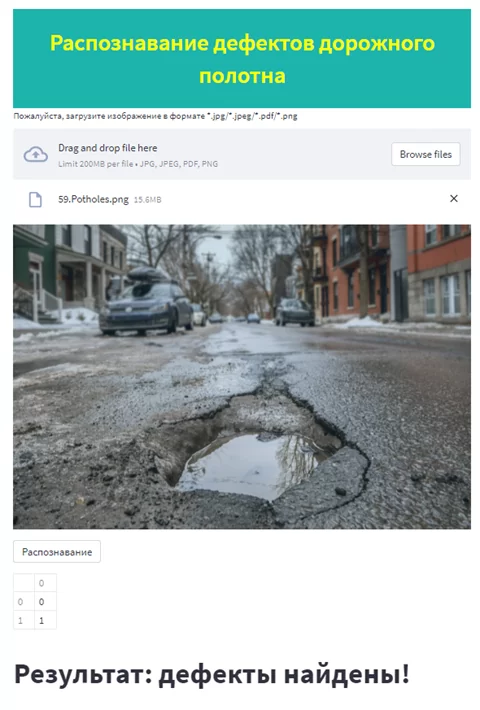
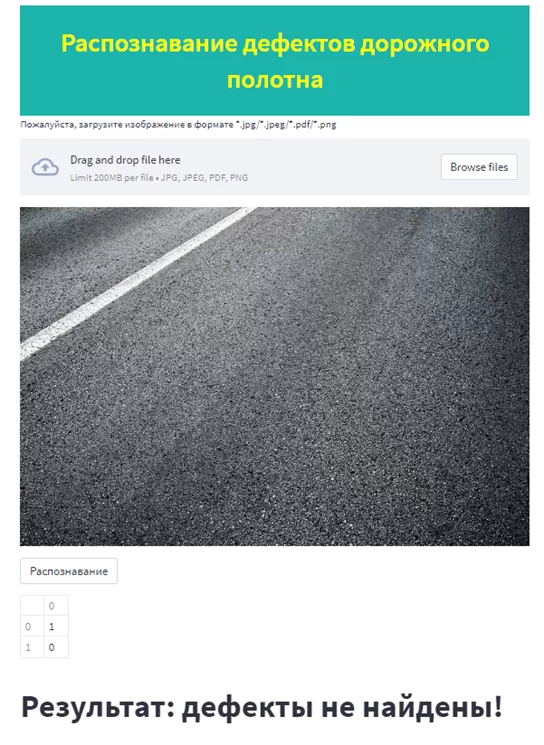
Для более качественных результатов распознавания входное изображение должно содержать поверхность дорожного покрытия без сторонних предметов и разметки, подобно изображениям из исходного набора данных. Таким образом, модель может быть использована в качестве автономного модуля системы распознавания дефектов, например, при обследовании полосы дорожного полотна.
Буду рад комментариям и ровных дорог вам!