/img/star (2).png.webp)






/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
В любой работе рано или поздно наступает момент, когда на компьютере нужно выполнять монотонные задачи, повторяя одни и те же действия из раза в раз. Кажется, что это можно было бы легко автоматизировать, ведь алгоритм прост и понятен, но на практике оказывается, что подходящий инструмент для такой автоматизации найти трудно. Но это не значит, что такой инструмент нельзя создать.
В первой части были разобраны основные компоненты программы, которая позволяет воспроизводить действия клавиатуры и кликать по выбранным элементам, ориентируясь на их координаты на экране. Однако поиск элемента по координатам иногда может дать сбой – внезапное появление рекламы на сайте может сместить нужный элемент и тогда нажатие мыши может «отправить» пользователя в долгое путешествие по сайтам с «выгодными предложениями» или изменение размера окна заставит перезаписывать всю последовательность действий.
Возникла идея выделять нужные для нажатия элементы как изображения, а затем, во время выполнения программы, находить их на скриншоте экрана для клика.
Из готовых решений есть pyautogui, которое позволяет по заранее заготовленным скриншотам элементов найти их на экране. Однако при любом малейшем изменении размера элемента, при смене браузера или при запуске на другом ПК, он перестает находить элементы.
Также для имитации действий пользователя на сайтах есть Selenium, но он не выходит за границы браузера, да и для каждого сайта нужно писать свой собственный парсер, а если сайт еще борется с автоматизированными запросами, то задача перестает быть тривиальной.
Поэтому было решено использовать методы библиотеки OpenCV для решения этой задачи.
Перед тем как искать элемент на экране, необходимо указать программе что именно нужно найти. Для этого было реализовано небольшое окошко для выбора и обрезки нужного фрагмента на экране с использованием уже знакомой библиотеки PySimpleGUI.
Суть работы этого окна такова – при нажатии правого Ctrl программа делает скриншот экрана и открывается окно, в котором можно выбрать и обрезать нужный фрагмент изображения.
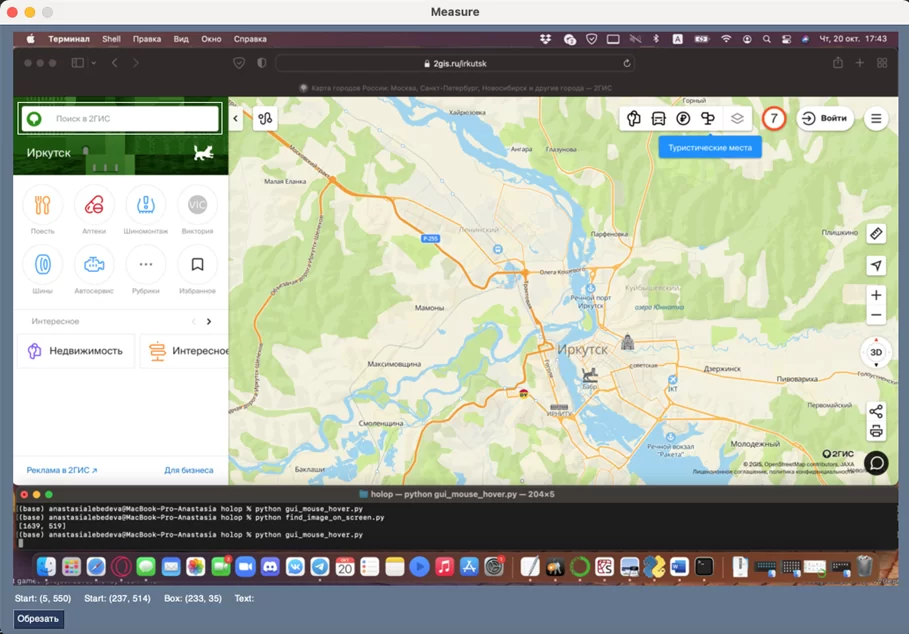
При зажатии правой кнопки мыши появляется прямоугольник, которым можно выделить нужную область. Отпустив кнопку мыши выделенную область, можно обрезать, нажав кнопку «Обрезать». После этого выбранная область покажется в окне, где можно вернуться к полному изображению экрана или сохранить ее.
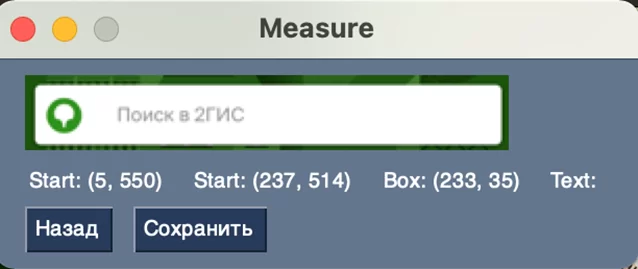
Для этого в интерфейсе существует два набора координат выбранной области – один набор динамически изменяется вместе с выделенной областью и фиксированный, который записывается в момент, когда отпускается кнопка мыши. Единица координат курсора – все также пиксель, отсчет системы координат ведётся от левого нижнего угла изображения, что нетипично и требует некоторых перечетов.
def update_picture(x_0, y_0, x_1, y_1, image):
"""
Обрезка изображения
"""
if x_0 < x_1 and y_0 < y_1:
im = image.crop((x_0, y_0, x_1, y_1))
elif x_0 < x_1 and y_0 > y_1:
im = image.crop((x_0, y_1, x_1, y_0))
elif x_0 > x_1 and y_0 > y_1:
im = image.crop((x_1, y_1, x_0, y_0))
elif x_0 > x_1 and y_0 < y_1:
im = image.crop((x_1, y_0, x_0, y_1))
else:
im = image
return im
while True:
winevent, values_cut = window.read(timeout=100)
if winevent == sg.WINDOW_CLOSED:
break
elif winevent in ('SELECT', 'SELECT+UP'):
# событие при зажатой мышке
if winevent == 'SELECT':
graph.delete_figure(figure_fix)
if (x_0, y_0) == (None, None):
x_0, y_0 = values_cut['SELECT']
x_1, y_1 = values_cut['SELECT']
update(x_0, y_0, x_1, y_1, window)
# событие при отпускании кнопки мыши
if winevent == 'SELECT+UP':
graph.delete_figure(figure_fix)
x_f_0, y_f_0, x_f_1, y_f_1 = x_0, height-y_0, x_1, height-y_1
figure_fix = graph.draw_rectangle((x_0, y_0), (x_1, y_1),
line_color=colors[index])
x_0, y_0 = None, None
if figure:
graph.delete_figure(figure)
if None not in (x_0, y_0, x_1, y_1):
figure = graph.draw_rectangle((x_0, y_0), (x_1, y_1),
line_color=colors[index])
index = not index
Далее, при непосредственном выполнении программы, необходимо найти вырезанный фрагмент и для этого были применены два варианта реализации: OpenCV SIFT (scale-invariant feature transform) и OpenCV Template Matching.
Метод OpenCV SIFT извлекает ключевые точки объектов из двух изображений и сравнивает их друг с другом, выбирая из них те, которые хорошо согласуются по местоположению, масштабу и ориентации.
import numpy as np
import cv2 as cv
from PIL import ImageGrab
from sklearn.cluster import KMeans
from collections import Counter
# скриншот экрана
screenshot = ImageGrab.grab().convert('L')
screenshot = np.array(screenshot)
# изображение, которое ищем на экране
image_for_search = cv.imread(image_path, cv.IMREAD_GRAYSCALE)
(hA, wA) = screenshot.shape[:2]
# создание SIFT
sift_detector = cv.SIFT_create()
# поиск ключевых точек на изображениях
_, descriptor_1 = sift_detector.detectAndCompute(image_for_search, None)
key_points_2, descriptor_2 = sift_detector.detectAndCompute(screenshot, None)
# FLANN параметры
flann = cv.FlannBasedMatcher(dict(algorithm=1, trees=5),
dict(checks=50))
matches = flann.knnMatch(descriptor_1, descriptor_2, k=2)
# выбираем самые соответствующие точки
points = []
for match in matches:
if match[0].distance < 0.6*match[1].distance:
p2 = key_points_2[match[0].trainIdx].pt
points.append((int(p2[0]), int(p2[1])))
Результат подобного сопоставления визуально выглядит вот так.
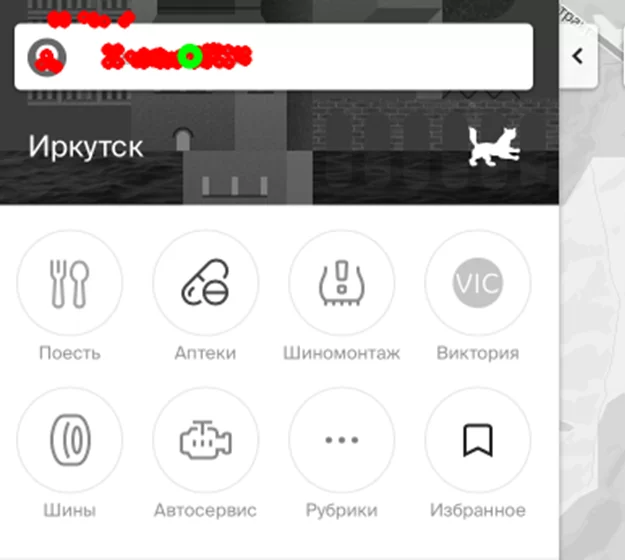
Как можно заметить, не все найденные точки корректны, однако большинство из них находятся именно в той области, которую нужно найти, поэтому набор точек разделяется на два кластера методом k-ближайших соседей и выбирается середина самого многочисленного из них.
kmeans = KMeans(n_clusters=2).fit(points)
counter = Counter(kmeans.labels_)
largest_cluster_idx = np.argmax(counter.values())
largest_cluster_center = kmeans.cluster_centers_[largest_cluster_idx]
largest_cluster_center = [int(x) for x in largest_cluster_center]
В случае, когда элемент слишком мал и ключевые точки подобрать сложно, было решено использовать OpenCV Template Matching. Суть этого метода в том, что он проводит искомое изображение по всему изображению экрана слева направо и сверху вниз и выбирает наиболее схожие участки.
Для определения схожести используется три из всех шести предлагаемых OpenCV методов оценки схожести изображения, которые показали себя лучше всего, и выбирается та область, которую нашли большинство из них.
methods = ['cv.TM_CCOEFF', 'cv.TM_CCOEFF_NORMED',
'cv.TM_CCORR_NORMED']
centers = []
for eval(method) in methods:
img = screenshot.copy()
search_result = cv.matchTemplate(img, image_for_search, method)
_, _, _, max_loc = cv.minMaxLoc(search_result)
height, width = image_for_search.shape[:2]
top_left = max_loc
bottom_right = (top_left[0] + width, top_left[1] + height)
centre = ((top_left[0]+bottom_right[0])//2,
(top_left[1]+bottom_right[1])//2)
centers.append(centre)
counter = Counter(centers).most_common()
largest_cluster_idx = max([i[1] for i in counter])
largest_cluster_center = centers[largest_cluster_idx]
В итоге получаем дополнение к исходной программе, которое позволяет, независимо от экрана, масштаба и прочих факторов, находить нужные элементы на экране. Теперь, если окно будет немного сдвинуто или откроется не в том месте, курсор мышки будет наведён в любом случае правильно.
Ссылка на репозиторий: https://github.com/Tortole/holop