/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Идентификация объектов на изображении как раз такой вид деятельности. Активное наблюдение за картинкой с камер — работа достаточно утомительная, с огромным потенциалом ошибок, связанных с человеческим фактором. Если объект может быть достаточно однозначно идентифицирован на изображении, то выявление такого рода объектов может быть реализовано с помощью нейронных сетей, что и было в итоге осуществлено.
Однако статья о другом. Статья о подготовке данных к обучению модели. Как правило, это самый трудоемкий и, нередко, самый важный процесс. Не секрет, что от качества входных данных зависит качество самой модели. Да, на общедоступных ресурсах находится достаточное значимое количество датасетов для желающих поломать копья. Если же стоит вполне конкретная задача, то эти данные столь же бессмысленны, сколь и многочисленны.
Итак, задача — в видеофайле найти сотрудников банка без маски. Другого способа получить набор изображений с контурами сотрудников в масках и без, кроме как руками сделать его, не существует. Основным инструментом, который был использован в работе, является – «VGG Image Annotator (VIA)».* Это опенсорсный продукт, который запускается в браузере в оффлайн-режиме и не требует каких — либо дополнительных зависимостей. Этот инструмент к слову позволяет не только размечать изображения, но и аудиофайлы, а также видео и определенную последовательность событий на нем. Разметка предлагает помечать объекты прямоугольниками, овалами и прочими геометрическими фигурами, что нам не подходит. Чтобы качественно обозначить сотрудника и маску, необходимо пользоваться ломанными замкнутыми линиями.
Домашний сайт продукта содержит мануалы, как им пользоваться. Конкретное руководство выходит за рамки статьи, да и к тому же было бы довольно утомительным. Нам более интересен сам результат. Реальные фотографии по понятным причинам выкладывать здесь не буду. Мы же воспользуемся плодами трудов Буонаротти Микеланджело и оденем в маску его творение.
Здесь 1 — это маска, а 2 — это сотрудник банка. Если приглядеться, то два контура состоят исключительно из прямых линий. Чем их больше, тем более качественный получается контур.
Сама утилита запускается в браузере. Выглядит следующим образом:
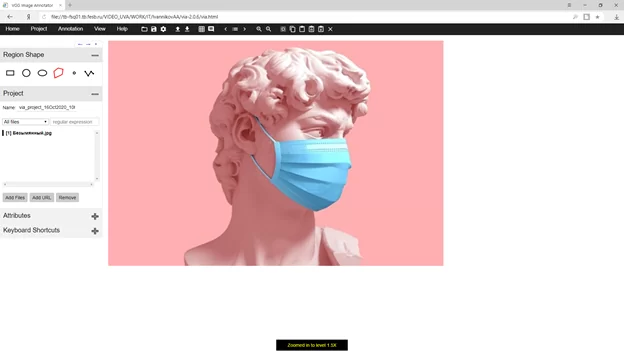
В ней можно выделять объекты разными геометрическими фигурами, вроде овала или прямоугольника. Если стоит задача просто идентифицировать область на изображении, где есть интересующий нас объект, то этого достаточно. В нашем случае, объект состоит из сложной фигуры, поэтому лучший выбор – ломанная кривая, выделенная красным.
Крайние точки на изображении помечаются как углы фигуры.
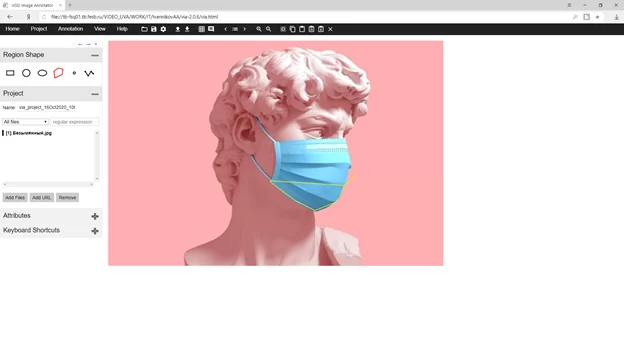
В конечном итоге вся область помещается в контур фигуры и нажимается “Enter”. На контуре отображаются все проставленные точки. Чем их больше, тем контур плавнее. Здесь самое главное соблюсти баланс между вырисовыванием каждого пикселя и, с другой стороны, не уподобится солдату — срочнику, чистящему картошку исключительно прямоугольниками.
Таким несложным способом обрабатываются все картинки в датасете, на котором будет обучение. Если объекта нет, то, разумеется, картинка пропускается.
В конце размеченные объекты выгружаеются в “csv”, либо в “json” форматах.
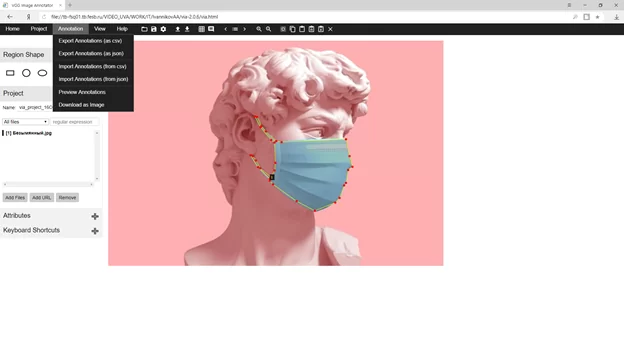
Например, изображение выше генерирует JSON следующего вида.
{"Безымянный.jpg34805":
{"filename":"Безымянный.jpg",
"size":34805,
"regions":[{"shape_attributes":
{"name":"polygon",
"all_points_x":[301,307,351,385,423,431,440,443,447,455,450,443,323,313,294, 286,277,273,284,304,310,312,310,304,283,275,269,265,279,301],
"all_points_y":[261,268,299,317,302,293,270,265,241,235,215,184,189,187,169,159,142,141,161,185,190,228,242,255,238,223,215,214,236,257]}
,"region_attributes":{}
}],"file_attributes":{}
}}
На нем четко прописаны x и y координаты всех точек, что мы отметили.
В конечном итоге вот это

Можно превратить в это

В данном случае у нас получаются два региона. Один с контуром самой маски, второй — с контуром сотрудника.
Для того, чтобы располагать достаточным датасетом для тренировки модели, необходимо порядка 1000 размеченных изображений. Разумеется, без распределенного сотрудничества получить необходимый объем информации просто невозможно.
JSON файлы прекрасно парсятся силами Python. В итоге само изображение в виде массива пикселей подаются как данные для тренировки, а полученные точки как метки для каждого сэмпла. После процесса обучения мы ожидаем для новых изображений массив из точек, который помечает на изображении сотрудника или сотрудников банка и контуры масок. Разумеется, контуры сотрудников и масок должны пересекаться, иначе маска одета на клиенте. Собственно, изображения с камер с такими случаями мы и ожидаем получить.
Что касается конкретных технологий, то в нашем случае была использована остаточная сеть resnet 50 на PyTorch.
Выводы:
- Это работает
- Это долго
- Это нудно
- Целесообразность задачи должна быть точно сопоставима со стоимостью вложенных усилий.
Таким образом, VIA позволяет не зависеть от уже размеченных и общедоступных датасетов, если они не совсем подходят нам и решать узкоспециализированные задачи, при условии, повторюсь, если затраты на разметку целесообразны по сравнению с пользой от решаемых задач.
*Abhishek Dutta and Andrew Zisserman. 2019. The VIA Annotation Software for Images, Audio and Video. In Proceedings of the 27th ACM International Conference on Multimedia (MM ’19), October 21–25, 2019, Nice, France. ACM, New York, NY, USA, 4 pages. https://doi.org/10.1145/3343031.3350535.