/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 3 мин.
Не будем утомлять себя теорией, но постараемся выделить общие принципы построения таких моделей:
- Порядок документов в коллекции не играет роли
- Расстановка слов в документе не играет роли, документ является мешком слов
- Слова, наиболее часто употребляемые в большинстве документов, не имеют значения для определения тематики
- Коллекцию документов можно обозначить как связку пар документ-слово
Для реализации потребуется библиотека spacy.
Импортируем нужные нам библиотеки:
import numpy as np
import pandas as pd
import gensim
import gensim.corpora as corpora
from gensim.utils import simple_preprocess
from gensim.models import CoherenceModel
import spacy
from spacy.lang.ru import Russian
from spacy.lang.ru.stop_words import STOP_WORDS
import ru_core_news_sm
from tqdm import tqdm_notebook as tqdm
from pprint import pprint
Импортируем файл с данными, не забывая об удалении пустых строк и выделяем данные с текстом, который будем исследовать в отдельный фрейм:
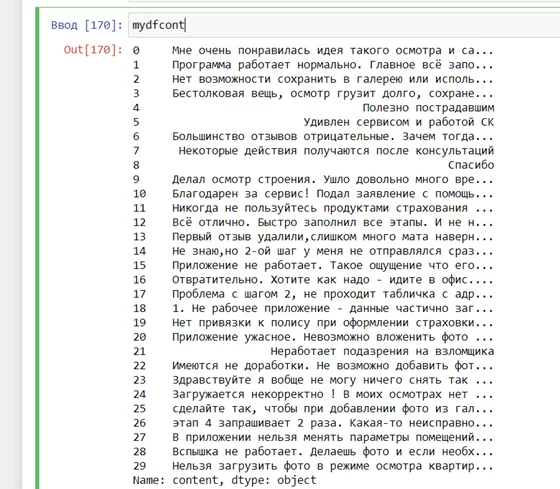
mydf = pd.read_csv('reviews.csv',sep='|')
mydf = mydf.dropna(subset=['content'])
mydfcont=mydf['content']
Далее импортируем русскоязычную модель для spacy и дополняем список стоп-слов, если это требуется:
nlp= spacy.load('ru_core_news_sm')
# Мой список стоп-слов
stop_list = ["что","когда","где","почему"]
# добавляем список стоп-слов к стандартному
nlp.Defaults.stop_words.update(stop_list)
# проставляем "is_stop" флаг
for word in STOP_WORDS:
lexeme = nlp.vocab[word]
lexeme.is_stop = True
Затем нужно лемматизировать текст и удалить стоп-слова, которые мы определили. Стоит обратить внимание на определение @language.component, это важно для любого кастомного pipeline, который вы определяете.
from spacy.language import Language
@Language.component("mylemmatizer")
def lemmatizer(doc):
#doc = nlp(doc)
doc = [token.lemma_ for token in doc]
doc = u' '.join(doc)
return nlp.make_doc(doc)
@Language.component("mystopwords")
def remove_stopwords(doc):
# удаляем слова и пунктуацию
# для генсим
doc = [token.text for token in doc if token.is_stop != True and token.is_punct != True]
return doc
nlp.add_pipe("mylemmatizer",name='mylemmatizer')
nlp.add_pipe("mystopwords", name="mystopwords", last=True)
Можно также удалить все местоимения. Для этого в лемматизаторе нужно изменить одну строку на:
doc = [token.lemma_ for token in doc if token.lemma_ != '-PRON-']Список всех pipeline, стандартных и определенных вами можно посмотреть, выполнив следующее:
print(nlp.pipe_names)На выходе в нашем случае будет подобное:
['tok2vec', 'morphologizer', 'parser', 'ner', 'attribute_ruler', 'lemmatizer', 'mylemmatizer', 'mystopwords']Осталось совсем немного, выполняем следующее:
doc_list = []
# пробегаем все отзывы по списку
for doc in tqdm(mydfcont):
# применяем pipe и добавляем к списку
pr = nlp(doc)
doc_list.append(pr)
«Обращаем» каждый отзыв в «bag of words»:
words = corpora.Dictionary(doc_list)
corpus = [words.doc2bow(doc) for doc in doc_list]
Определяем модель:
lda_model = gensim.models.ldamodel.LdaModel(corpus=corpus,
id2word=words,
num_topics=10,
random_state=2,
update_every=1,
passes=10,
alpha='auto',
per_word_topics=True)
И получаем результат, который «объясняет» как формируется каждая их тем:
pprint(lda_model.print_topics(num_words=10))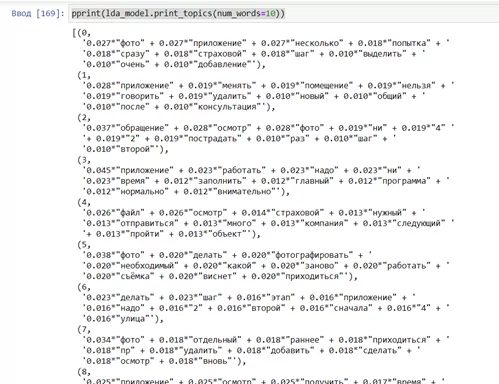
В итоге мы смогли «организовать» наши разрозненные обращения клиентов в то, с чем в дальнейшем можно качественно работать. Более того, у нас есть понимание, какие слова в этих обращениях наибольшим образом влияют на распределение по темам.