/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
На сайте Newtechaudit.ru описывались различные способы извлечения таблиц с данными из pdf-файлов в excel. В частности, с помощью python-библиотеки camelot (как здесь).
Рассмотрим расширенные возможности camelot, позволяющие распознать большую таблицу со сложной структурой. А также покажем, как использовать библиотеку PyMuPDF в качестве бэкэнда для конвертации pdf в png.
Следует учесть, что сamelot может распознавать только так называемые text-based pdf файлы. То есть те, внутри которых можно выделять текст. Если pdf является сканом, то camelot не сработает.
Установка библиотек на примере pip:
pip install PyMuPDF
pip install "camelot-py[base]"
Файл-пример, который будем использовать, содержит одну таблицу, умещенную на двух страницах. Она содержит данные с kaggle о продажах в кофейне:
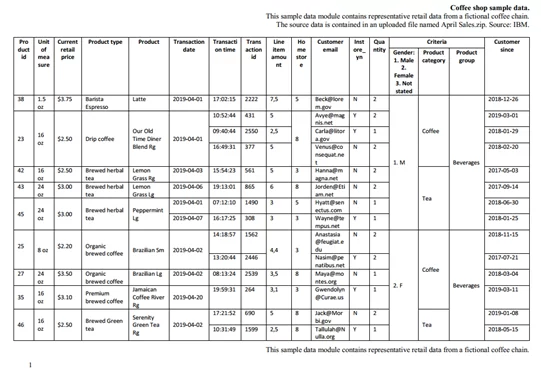
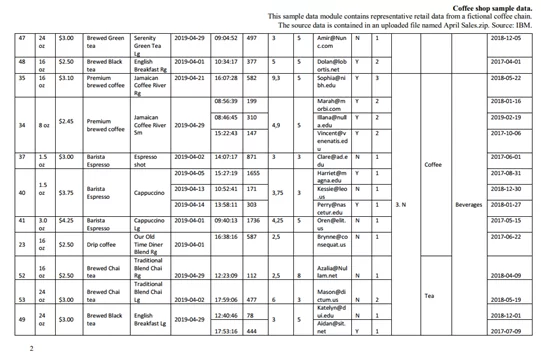
Не стоит искать какой-то смысл в содержании данной таблицы, это просто пример. Важно лишь то, что в ней много объединенных ячеек, и она занимает почти всю площадь страницы. Приступим к ее извлечению.
Импорт библиотек
import pandas as pd
import camelot
# Так импортируется PyMuPDF
import sys, fitz
Конвертация pdf в картинку
Camelot определяет границы и структуру таблицы с помощью распознавания линий. Для этого используется бэкенд, конвертирующий pdf в картинку. В качестве бэкенда можно использовать ghostscript или poppler. Но они требуют установки дополнительных зависимостей и ПО, что не очень удобно. Можно обойтись еще одним вариантом бэкенда – написать свой собственный, используя PyMuPDF. Для этого напишем специальный класс:
class ConversionBackend(object):
def convert(self, pdf_path, png_path):
# Открываем документ
doc = fitz.open(pdf_path)
for page in doc.pages():
# Переводим страницу в картинку
pix = page.get_pixmap()
# Сохраняем
pix.save(png_path)
Извлечение таблицы из файла
Вся основная работа производится в функции read_pdf(). В ней присутствует множество параметров, которые указываются в зависимости от исходных данных и требуемого результата. В нашем случае установим следующие параметры (далее будет описано, почему именно такие):
file = 'TableExampleCoffeshop.pdf'
tables = camelot.read_pdf(file,
backend=ConversionBackend(),
strip_text='\n',
line_scale=40,
pages='all',
copy_text=['h'],)
Распознанные таблицы получили в виде списка объектов camelot.core.Table. В списке две таблицы по количеству страниц.
Посмотрим первую таблицу в формате датафрейма:
tables[0].df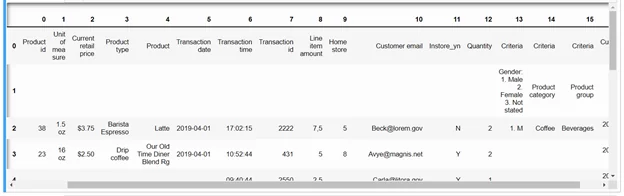
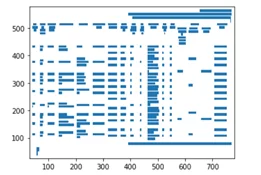
У camelot также есть полезная функция визуализации распознанных элементов на разных уровнях. Это позволяет понять, какие параметры лучше подкорректировать в случае ошибок. Убедимся, что линии таблицы и области с текстом были определены верно:
camelot.plot(tables[0], kind=’grid’).show()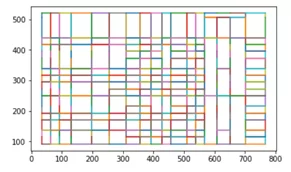
camelot.plot(tables[0], kind=’text’).show()
Получим итоговую таблицу и сохраним ее в excel файл:
whole_table = pd.concat([tables[0].df, tables[1].df])
whole_table.to_excel('ResultTableCoffee.xlsx', index=False, header=False)
Взглянем на результат:
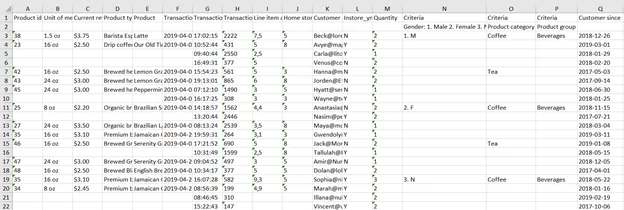
Все данные успешно перенесены в excel.
Параметры функции read_pdf
Итак, что же там с параметрами? С файлом и бэкендом понятно, но что означают все остальные?
• strip_text
Удаляет лишние символы из распознанного текста. Если бы мы не указали ‘\n’, то текст бы выглядел так:

• line_scale
Позволяет определять более короткие линии таблицы. Чем больше данный коэффициент, тем меньше размер наименьшей обнаруживаемой линии. Если бы оставили значение по умолчанию, то в третьем столбце с конца Coffee слилось бы с Tea:
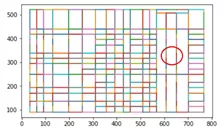
• pages
Страницы, с которых нужно считать информацию. Если нужно извлечь конкретные страницы, пишем их через запятую. Например, ‘1, 3’.
• copy_text=['h']
Позволяет копировать текст в объединенных ячейках. Символы h и v обозначают копирование в горизонтальном и вертикальном направлениях соответственно. В нашем случае заголовок Criteria скопировался на все три объединенные ячейки благодаря этому параметру. Остальные пустые клетки заполнять не стали, чтобы наглядно видеть соответствие полученного excel файла исходному pdf.
• shift_text
Указывает, где расположить текст в объединенных ячейках. Значение по умолчанию — [‘l’, ‘t’], то есть в левой верхней части. Если бы поставили значение [»], то есть оставили текст там, где он был в оригинале, то заголовки определились бы как отдельные строки. К тому же, было бы сложно определить, к каким строчкам относятся значения столбцов Criteria, так как они бы «висели в воздухе», как на примере ниже:
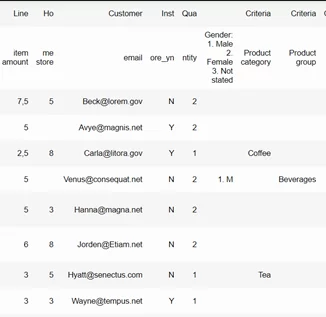
Итоги
Нам удалось корректно извлечь таблицу из pdf в excel с помощью camelot и PyMuPDF. Мы использовали собственный легкий бэкенд для функции read_pdf(), рассмотрели основные настраиваемые параметры, а также функцию для визуализации результата распознавания таблицы.
В данном материале рассмотрен только один из способов использования библиотеки camelot. Другие ее возможности можно посмотреть по ссылке. Спасибо за внимание!