/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Я очень люблю готовить, поэтому постоянно закупаюсь ингредиентами для различных блюд. Однако, в последний раз я закупил их слишком много, теперь срок их годности подходит к концу. Но не выкидывать же продукты в мусорную корзину? Конечно, я бы мог использовать их все разом, но вряд ли блюдо в таком случае получится вкусным. Или же, приготовить множество вариаций совершенно разной еды, но я так много не съем и на готовку у меня времени в обрез. Потому было принято решение приготовить минимальное количество блюд, использовав все доступные ингредиенты.
Что рассматриваем?
Долгое время я копил записи рецептов с форумов. Был собран датафрейм: 8102 строк и 60 столбцов, где строки — это блюда и их рецепты, а столбцы – ингредиенты. Строки могут повторяться – это связано с тем, что рецепт какого-либо блюда часто упоминался среди пользователей, значит рецепт проверенный.
С помощью библиотеки pandas посмотрю на собранный датафрейм.
import pandas as pd
df = pd.read_excel('рецепты.xlsx', sheet_name='Sheet1', engine='openpyxl')df = df.set_index(['Блюдо'])
df
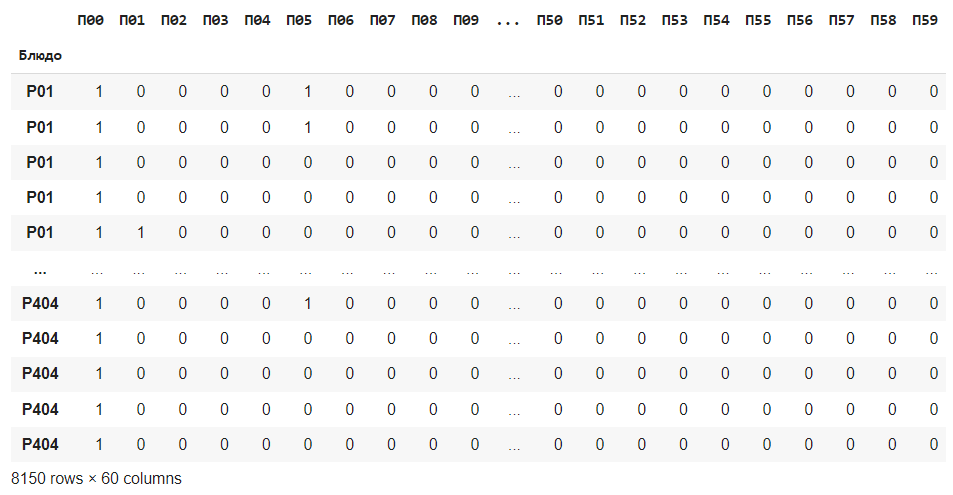
Датафрейм представляет собой бинарную матрицу, где 1 – наличие продукта в рецепте и 0 – его отсутствие.
На второй странице у меня находятся классификации продуктов, где ОП – обязательный продукт, ВП – вспомогательный продукт и ПП – приправы. Запишу их в отдельные датафреймы на будущее, для возможности выбора между ними. Сначала найду самые популярные, проверенные рецепты.
Как это сделать?
На самом деле можно посчитать «в лоб» и сравнить значения, но это слишком долго. Поэтому применю существующий инструмент, который позволяет выполнять поиск наиболее частых комбинаций, используя данные такого же формата – поиск ассоциативных правил или association rule mining.
Поиск ассоциативных правил — это метод выявления отношений между переменными, использующийся в data mining. Существует множество методов анализа. Алгоритм Apriori, который я использовал, является наиболее популярным, простым и понятным инструментом.
Данный алгоритм часто применяется в анализе продуктовой корзины, он же basket analysis. Строки рассматриваются как транзакции, а столбцы – как покупки. Смысл анализа продуктовой корзины заключается в поиске наиболее популярных транзакций, выявление вероятности покупки некоторого набора товаров и использование полученных результатов, например, в разработке рекомендательных алгоритмов.
Существует множество метрик алгоритма Apriori. Но так как мне интересна только частота, была использована только поддержка. Поддержка (Support) – соотношение количества полученных транзакций к общему количеству транзакций. Иными словами – как часто полученный набор товаров встречается во всем датасете.
О работе алгоритма, кратко:
- Вычисляется поддержка для каждого элемента. Сразу исключаются те элементы, у которых поддержка меньше заданного минимума.
- Итеративно вычисляется поддержка для наборов, постепенно увеличивая их размер.
- С ростом размера набора метрика поддержки либо уменьшается, либо остается неизменной. Иными словами, набор будет популярным только тогда, когда его элементы (или подмножества) также будут популярны. Этот принцип позволяет сократить пространство поиска, не тратя время на перебор абсолютно всех возможных комбинаций. Например, если поддержка для комбинации МОЛОКО+СЕЛЕДКА ниже заданного минимума, из дальнейшего перебора исключаются абсолютно все рецепты, которые содержат эту комбинацию.
Вызову библиотеку с реализованным алгоритмом и применю его для всего датасета.
#Установка библиотек
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
#Вызов алгоритма Априори для всего датасета
fr = apriori(df, min_support=0.0075, use_colnames=True)
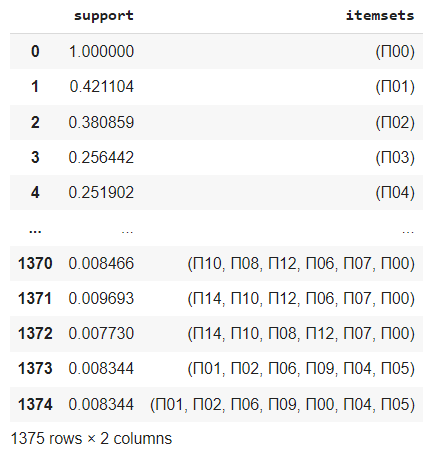
Понятно, что так как единичные продукты встречаются во многих рецептах, они будут появляться чаще всего и с большим показателем поддержки. 1375 блюд я не смогу приготовить, и контекст данных потерян в виду того, что рассматривался весь датасет, в том числе вспомогательные продукты и специи. Низкие показатели поддержки в наборах, где больше чем один продукт, обусловлены высокой дисперсией данных, поэтому явно группы выявить сложно.
Но от продуктов избавляться надо, поэтому попробую доработать алгоритм:
- Алгоритм Apriori достаточно требовательный и его отработка может занять много времени. Поэтому есть смысл искать вариации продуктов по группам, для каждого блюда отдельно.
- Разделю основные продукты, вспомогательные и приправы.
- Сделаю возможность выбора уровня поддержки, минимального и максимального количества продуктов в рецепте.
Прочитаю на второй странице своего кулинарного сборника свои классификации продуктов, и запишу их в разные датафреймы для возможности их выбора.
#Записываем в датафрейм лист с классификацией продуктов
dff = pd.read_excel('рецепты.xlsx', sheet_name='po', engine='openpyxl')
op = []
vp = []
pp = []
#iterrows для лучшей читаемости, таблица небольшая. Соотносим значение столбца type в выделенные одноименные массивы
for i, row in dff.iterrows():
if row['type'] == 'ОП':
op.append(row['po'])
elif row['type'] == 'ВП':
vp.append(row['po'])
else:
sp.append(row['po'])
#Превращаем собранные массивы в датасеты, для удобного вызова
df_op = df[op]
df_sp = df[vp]
df_pp = df[pp]
Указываю группировку (возможно будут другие атрибуты, например, страна происхождения блюда) и выбор используемых продуктов.
#В х попадает атрибут по которому будет группировка, в у – подготовленные выше датасеты
x = input("Группировать: ")
y = input("Вид продуктов:")
if y=='ОП':
gr = df_op.groupby(level=[x])
elif y=='ВП':
gr = df_sp.groupby(level=[x])
elif y=='ПП':
gr = df_pp.groupby(level=[x])
else:
gr = df.groupby(level=[x])
#Предварительный вывод полученной группировки
gr.head()
Дальше напишу основной алгоритм. Разобью по группам относительно блюд и уже внутри каждой группы будет отработан алгоритм. Также вытащу имя этой группы, чтобы было удобно ориентироваться в результатах.
#В appended_data запишем результаты работы алгоритма
appended_data = []
for name, group in gr:
#В каждой группе выполняем алгоритм априори. Рассматриваем частоту внутри каждой группы обособленно от всего датасета. Параметры min_support (минимальная поддержка)и max_len (максимальная длинна комбинации)задаются пользователем, сохраняются в переменные
fr = apriori(group, min_support=float(z), use_colnames=True, max_len=int(a))
#Добавляем столбец в котором будет длинна комбинации
fr['length'] = fr['itemsets'].apply(lambda x: len(x))
#Делаем сортировку поддержки по убыванию. От самых частых до самых редких комбинаций
idx = fr.groupby(['length'])['support'].transform(max) == fr['support']
#leng отвечает за минимальную длину, задается пользователем. Внутри apriori нет возможности задать минимальную длину комбинации, поэтому просто фильтруем
fr = fr[idx][(fr[idx]['length'] >= int(leng))]
#Добавляем столбец в котором будет указана группа, к которой принадлежит комбинация
fr['name'] = name
fr['itemsets'] = fr['itemsets'].apply(lambda x: ', '.join(list(x))).astype("unicode")
#Собираем результат
appended_data.append(fr)
appended_data = pd.concat(appended_data)
appended_data = appended_data.reset_index()
appended_data.head()
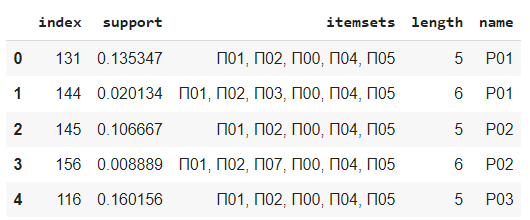
Получил уже намного меньше сочетаний, 91 комбинация. Однако в этом случае метрика поддержки показывает частоту внутри группы, а не всего датасета. Теперь проверю встречаемость этим комбинаций внутри всего датасета.
Напишу небольшой скрипт для перезаписи существующего датасета. Это нужно для того, чтобы проверить комбинации как подмассивы.
test = pd.DataFrame()
test['index'] = ''
test['itemsets'] = ''
i = 0
#Пересобираем исходный датасет. Так как нужно проверить комбинации как подмассивы, делаем из строки массив, куда заносим названия столбцов со значением 1
for row in df.itertuples():
test.loc[i, 'index'] = ', '.join((str(x) for x in getattr(row, 'Index')))
x = []
for name, value in row._asdict().items():
if value == 1:
x.append(name)
test.loc[i, 'itemsets'] = ', '.join(x)
i += 1
Затем важно преобразовать полученные наборы выше, так как Itemsets содержит в себе frozenset.
i = 0
for row in appended_data.itertuples():
a = sorted(getattr(row, 'itemsets').split(', '))
appended_data.loc[i, 'itemsets'] = ', '.join(a)
i += 1
Соединяю список рецептов и процент попадания элементов в другие рецепты.
i = 0
appended_data['where'] = ''
appended_data['percent'] = ''
for row in appended_data.itertuples():
#Получаем значения из itemsets
a = getattr(row, 'itemsets')
y = []
count = 0
for roww in test.itertuples():
#Если у нас полное совпадение по продуктам, записываем рецепт
if all(x in (getattr(roww, 'itemsets')) for x in a):
y.append((getattr(roww, 'index')))
count +=1
appended_data.loc[i, 'where'] = ' | '.join(y)
#Процент вхождения ингредиентов во всех рецептах
appended_data.loc[i, 'percent'] = count/df.shape[0]*100
i += 1

Я получил отличную таблицу с отобранными рецептами в количестве 90 штук и мои продукты спасены.
Алгоритм Apriori достаточно удобный инструмент, несмотря на то что он в действительности далеко не новый. Существует много других алгоритмов, в том числе и модификации Apriori для полного анализа продуктовой корзины. Но для типовых задач комбинаторики этот инструмент подходит отлично. Пример с продуктами лишь более просто и наглядно демонстрирует возможности применения этого инструмента. В действительности задачи на поиски комбинаций с полным покрытием встречаются и в повседневной работе любого IT специалиста. Конечно, можно было бы разработать тяжеловесный скрипт с использованием технологий искусственного интеллекта, но займемся этим в будущем. Ведь важно не забивать гвозди микроскопом, и уметь использовать подобные «допотопные» инструменты. Это поможет сэкономить ваше время и ресурсы.