/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Недавно мы с коллегами работали над задачей автоматического распознавания русского рукописного текста. В предыдущей статье была описана работа над созданием нашего датасета для обучения моделей машинного обучения распознаванию рукописных текстов. Теперь хочу рассказать непосредственно про использованную нами модель (нейронную сеть), её архитектуру, тренировку и результаты, которых удалось достичь.
Наша модель, основанная на архитектуре австрийского учёного Гаральда Шайдля Simple HTR, состояла из двух больших блоков: свёрточного и рекуррентного. Свёрточный блок служит для создания feature map (карты признаков, c которой впоследствии будет работать вторая часть модели и предсказывать символы). Он состоял из 5 свёрточных слоёв. Вполне возможно варьировать это количество, но мы остановились на этом числе. Затем результат свёртки передаётся на вход рекуррентному блоку, состоявшему в нашем случае из двухслойной LSTM, которая посимвольно предсказывала результирующий текст. СТС Loss использовался в качестве функции потерь. Он ограничен максимальным размером входящей в него последовательности символов – 32 элемента, поэтому наши примеры содержали не более 32 символов. Финальный выход получался после прогона через раскодировщик, подбор которого стал отдельной задачей. Основными отличиями нашего варианта Simple HTR от оригинального стали изменённый загрузчик данных (data loader) и изменения в блоке decoder_output_to_text, где мы добавили вариант декодера с коррекцией правописания. В целом же архитектура схожа с оригинальной, мы не стали изобретать велосипед. Код инициализации нейросети на TensorFlow слишком длинный, чтобы добавить его сюда целиком, поэтому приведу только основные блоки CNN и RNN (LSTM), так как они иллюстрируют общую структуру модели:
def setup_cnn(self) -> None:
"""Создание свёрточных слоёв"""
cnn_in4d = tf.expand_dims(input=self.input_imgs, axis=3)
# Параметры свёрточного ядра, выходных нейронов, stride для каждого слоя
kernel_vals = [5, 5, 3, 3, 3]
feature_vals = [1, 32, 64, 128, 128, 256]
stride_vals = pool_vals = [(2, 2), (2, 2), (1, 2), (1, 2), (1, 2)]
num_layers = len(stride_vals)
# Cоздание слоёв
pool = cnn_in4d
for i in range(num_layers):
kernel = tf.Variable(
tf.random.truncated_normal([kernel_vals[i], kernel_vals[i], feature_vals[i], feature_vals[i + 1]],
stddev=0.1))
conv = tf.nn.conv2d(input=pool, filters=kernel, padding='SAME', strides=(1, 1, 1, 1))
conv_norm = tf.compat.v1.layers.batch_normalization(conv, training=self.is_train)
relu = tf.nn.relu(conv_norm)
pool = tf.nn.max_pool2d(input=relu, ksize=(1, pool_vals[i][0], pool_vals[i][1], 1),
strides=(1, stride_vals[i][0], stride_vals[i][1], 1), padding='VALID')
self.cnn_out_4d = pool
def setup_rnn(self) -> None:
"""Создание рекуррентных слоёв."""
rnn_in3d = tf.squeeze(self.cnn_out_4d, axis=[2])
num_hidden = 256
cells = [tf.compat.v1.nn.rnn_cell.LSTMCell(num_units=num_hidden, state_is_tuple=True) for _ in
range(2)] # 2 слоя LSTM
# базовые ячейки
stacked = tf.compat.v1.nn.rnn_cell.MultiRNNCell(cells, state_is_tuple=True)
# bidirectional RNN (двунаправленная)
(fw, bw), _ = tf.compat.v1.nn.bidirectional_dynamic_rnn(cell_fw=stacked, cell_bw=stacked, inputs=rnn_in3d,
dtype=rnn_in3d.dtype)
# BxTxH + BxTxH -> BxTx2H -> BxTx1X2H (конкатенация)
concat = tf.expand_dims(tf.concat([fw, bw], 2), 2)
# выход RNN блока
kernel = tf.Variable(tf.random.truncated_normal([1, 1, num_hidden * 2, len(self.char_list) + 1], stddev=0.1))
self.rnn_out_3d = tf.squeeze(tf.nn.atrous_conv2d(value=concat, filters=kernel, rate=1, padding='SAME'),
axis=[2])
В процессе обучения мы разбивали тренировочный датасет на 500 батчей, прогон одного батча занимал различное время в зависимости от использованных вычислительных мощностей и способа загрузки данных. При использовании CPU и загрузки данных через Google диск на один батч уходило 4 минуты. Затем, когда мы поменяли загрузчик на LMDB базу данных, время работы уменьшилось в 4 раза и составляло около 1 минуты на батч. Наконец, когда мы перешли на GPU от Google Colab (Nvidia Tesla p40, Nvidia Tesla v100), на один батч стало уходить порядка 2 секунд. Итоговое среднее время обучения составляло 2-4 астрономических часа, после этого времени улучшения метрик не происходило.
Приведу код создания базы данных LMDB на 1 ГБ:
env = lmdb.open('lmdb', map_size=1024 * 1024 * 1024)
imgs = (drive_path / 'images').walkfiles('*.jpg')
with env.begin(write=True) as conn:
for idx, img in enumerate(imgs):
read_img = cv2.imread(img, cv2.IMREAD_GRAYSCALE)
bd_filename = '/'.join(str(img).split('/')[-3:]).encode("ascii")
conn.put(bd_filename, pickle.dumps(read_img))
env.close()
Пара слов об использованных метриках:
Character accuracy (CER) — метрика, показывающая посимвольное соответствие вывода модели и валидирующей строки (то есть доля верно предсказанных символов в целом).
Line accuracy — метрика, показывающая соответствие вывода модели и валидирующей строки по словам (то есть доля верно предсказанных предложений).
Важным элементом исследования являлся подбор декодера (раскодировщика символов). Мы применяли CTC Best Path и CTC Beam Search. Алгоритм Beam Search нам очень помог, с ним результаты стали существенно лучше. Приведу графики изменения наших метрик (точности предсказания по символам и точности предсказания по словосочетаниям, которые мы подавали на обучение) в зависимости от эпохи обучения:
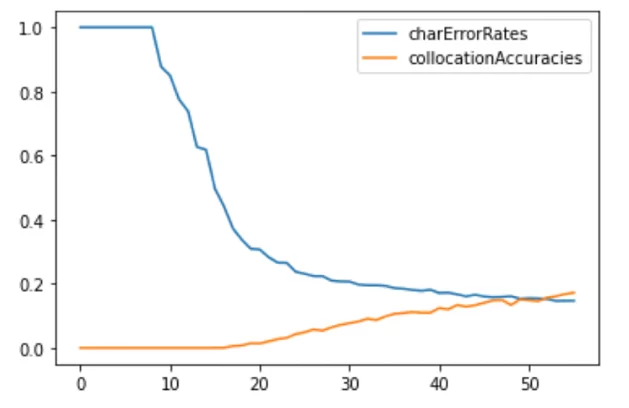
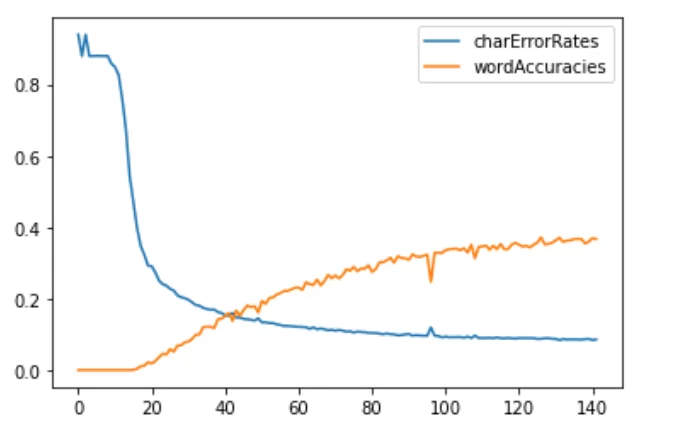
В итоге мы получили следующие результаты: 91,4 % Character Accuracy Rate, 36,7 % Line Accuracy Rate.
Затем мы решили применить в качестве декодера технологию Word Beam Search, основанную на коррекции слов с использованием фиксированного корпуса слов русского языка. Это дало очень серьёзный «буст», выведя Line Accuracy Rate на значение около 75%, а Character Accuracy Rate вообще на точность, близкую к 100%. Но эту технологию не стоит применять, она очень чувствительна к наличию слова в своём словаре. Если слова она не знает, то вместо того, чтобы написать предсказание, она напишет совершенно другое слово, просто выбрав похожее из своего словаря. Соответственно, она либо угадывает 100% слово, либо не угадывает его вовсе. В связи с этим мы решили, что для применения в индустрии использование данного метода не подходит, какими бы хорошими ни казались результаты. Прикрепляю ссылку на хорошую статью, объясняющую, как работает Word Beam Search.
Краткая сводка по нашим экспериментам:
| Элемент 1 | Элемент 2 | Элемент 3 | Элемент 4 |
| Модель: 5CNN+2LSTM | Модель: 5СNN+2LSTM | Модель: 5CNN+2LSTM | Модель: 5CNN+2LSTM |
| Время обучения: 2 ч 15 мин | Время обучения: 3 ч 35 мин | Время обучения: 3 ч 45 мин | Время обучения: 3 ч 30 мин |
| Эпох: 36 | Эпох: 166 (последние 25 без улучшений) | Эпох: 142 (последние 10 без улучшений) | Эпох: 88 |
| Холодный старт | Холодный старт | Холодный старт | Холодный старт |
| Без перемешивания выборки | Без перемешивания выборки | Перемешанная выборка с фиксированной псевдослучайностью | Перемешанная выборка с фиксированной псевдослучайностью |
| Оптимизатор: Adam | Оптимизатор: Adam | Оптимизатор: Adam | Оптимизатор: Adam |
| Декодер: CTC Bestpath | Декодер: CTC Bestpath | Декодер: CTC Beamsearch | Декодер: CTC WordBeamsearch |
| Размещение данных: Google Drive | Размещение данных: LMDB | Размещение данных: LMDB | Размещение данных: LMDB |
| Значения метрик: CER: 21% Line accuracy: 15% | Значения метрик: CER: 11.0% Line accuracy: 26.73% | Значения метрик: CER: 8.61% Line accuracy: 36.7% | Значения метрик: CER: 4.17% Line accuracy: 75.52% |
Мы также завернули нашу лучшую на данный момент модель в Docker-контейнер, чтобы каждому желающему можно было самостоятельно убедиться в качестве её работы. Ссылка (рекомендуется открывать в браузере Google Chrome).
Мы планируем в дальнейшем продолжать работу над улучшением нашей модели и провести ещё серию экспериментов.