/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Для использования регулярных выражений в своей работе первым делом необходимо подключить библиотеку Microsoft VBScript Regular Expressions 5.5
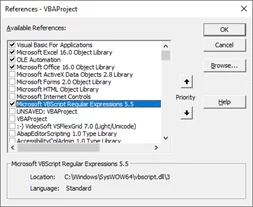
Приведем примеры трех полезных функций, которые необходимо записать себе в личную книгу макросов, для того чтобы их просто вызывать с листа.
Первая функция — это тестирование, т.е. проверка текста на соответствие определённой маске (маска может быть какой угодно, чтобы правильно составить маску нужно знать синтаксис регулярных выражений).
Public Function uf_StrTest(ByVal strBasic As String, ByVal strPattern As String) As Boolean
Dim Rx As New RegExp
With Rx
.Global = True
.IgnoreCase = True
.MultiLine = True
.Pattern = strPattern
End With
uf_StrTest = Rx.test(strBasic)
End Function
Вот как это работает:
Первый аргумент функции, это то, что мы проверяем. Второй аргумент – маска, которой должно соответствовать проверяемое выражение.
Например, uf_StrTest(C1;»[а-я]») проверит, содержит ли ячейка С1 хотя бы одну маленькую букву кириллицы, если содержит, то возвратит истину, иначе — возвратит ложь. Данную функцию можно использовать на запрет при вводе буквы латинского алфавита.
Вторая функция — это замена, т.е. извлечение из текста какой-то его части по определённому правилу.
Public Function uf_Replace(ByVal strBasic As String, ByVal strPattern As String, ByVal strModel As String) As String
Dim Rx As New RegExp
With Rx
.Global = True
.IgnoreCase = True
.MultiLine = True
.Pattern = strPattern
End With
uf_Replace = Rx.Replace(strBasic, strModel)
End Function
Приведем пример как работает эта функция.
Допустим, у нас есть текст в ячейке С3 «Сидоров Петр Петрович». Нам нужно извлечь начальные буквы ФИО. Тогда наша функция будет выглядеть так
uf_Replace(C3;»^([^\s])[^\s]+\s+([^\s])[^\s]+\s+([^\s])[^\s]+»;»$1$2$3«)
Жирным шрифтом выделены выражения в круглых скобках, их ровно три.
Именно они и будут в итоге являться заменой. Например, наша функция примет значение «СПП».
А вот uf_Replace(C3;»^([^\s])[^\s]+\s+([^\s])[^\s]+\s+([^\s])[^\s]+»;»$2$3$1«) вернет «ППС»
Недостаток этой функции в том, что мы должны знать маску всего текста, если мы этого не знаем, мы можем использовать третью функцию
Третья функция — это извлечение. Извлечение из текста его какой-то части по определённой маске.
Это требуется, если необходимо извлечь электронную почту или дату. Особенно, если в текстовой строке указано несколько электронных адресов.
Public Function uf_Execute(ByVal strBasic As String, ByVal strPattern As String) As String
Dim Rx As New RegExp Dim It As Variant Dim objMatch As Object
With Rx
.Global = True
.IgnoreCase = True
.MultiLine = True
.Pattern = strPattern
End With
Set objMatch = Rx.Execute(strBasic)
For Each It In objMatch
If uf_Execute = «» Then
uf_Execute = It
Else
uf_Execute = uf_Execute & «;» & It
End If
Next
End Function
Приведем пример как работает эта функция. Допустим, у нас есть текст в ячейке С3 «штрих-код: 30612-58746-16431-17562-35097-48735-17530-39512, дата регистрации: 23.10.2019, скан.образ:». Нам нужно извлечь дату. Тогда наша функция будет выглядеть так uf_Execute(С3;»\d{2}\.\d{2}\.\d{4}»). Таким образом мы извлекаем из текса в ячейке СЗ, все что соответствует маске второго аргумента функции, если их несколько — функция выдаст их через точку с запятой.