/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Тематическое моделирование — методы машинного обучения по обработке естественного языка (NLP). Они позволяют понять состав данных, смысл большой коллекции текстовых документов. Один из самых популярных методов тематического моделирования – Латентное размещение Дирихле (LDA).
Метод LDA позволяет определить скрытые (латентные) тематики в тексте, предполагая, что эти темы сформированы на основании вероятности вхождения слова из заданного текста. LDA можно рассматривать как метод «мягкой» кластеризации – текст может относится к той или иной тематике с определённой вероятностью.
Метод LDA применялся нами для анализа проблем с оборудованием и программным обеспечением из большого объема выборки обращений (порядка 400 тысяч) внутренних и внешних клиентов. Реализация алгоритма LDA через модуль Python Gensim заключалась в следующем:
- Выгрузка обращений из базы данных автоматизированной системы регистрации обращений внешних и внутренних клиентов за период с помощью SQL-запросов, сохранение промежуточных результатов в файлы и последующей загрузкой в dataframe с содержимым вида:
| ID | Время регистр | Описание |
| 456874123 | 01.02.2020 09:37 | Адрес: Подробное описание проблемы: не работает камера, мутное изображение |
| 456874045 | 10.05.2020 11:04 | Адрес: Подробное описание проблемы: нет возможности произвести снимок, не запускается приложение |
- Предобработка текста поля «Описание» – ключевой этап подготовки к обучению модели. Этап состоит из следующих шагов:
— удаление знаков препинаний, цифр, спецзнаков через регулярные выражения:
patterns = r'[0-9!#№$%&'()*+,\./:;<=>?@\[\]^_`{|}~—\"-]+'
doc = re.sub(patterns, ' ', doc.lower())
— лемматизация через pymorphy2– приведение слов к начальной форме (именительный падеж для существительных, неопределённая форма глаголов):
for token in doc.split():
token = token.strip()
token = morph.normal_forms(token)[0]
— удаление стоп-слов – предлоги, слова приветствий, наречия, наименования полей запросов – всё то, что не несет для нас ценности при выделении тематик проблем:
if token and token not in stopwords:
tokens.append(token)
- Двумя основными входными данными для тематической модели LDA являются словарь слов:
dictionary = Dictionary(text_clean)и корпус – id слова и частота его встречаемости:
corpus = [dictionary.doc2bow(doc) for doc in text_clean]- Обучение модели с разными значениями topics количества скрытых тем num_topics для выявления качественной модели, с расчетом основной метрики качества — когерентности (согласованности) — каждой модели. Чем выше значение согласованности, тем более выраженные темы модель выделяет в тексте описаний:
model=LdaMulticore(corpus=corpus, id2word=dictionary, num_topics=topics,
random_state=200, workers=4)
coherence_model = CoherenceModel(model=model, texts=text_clean,
dictionary=dictionary, coherence='c_v')
- По завершении обучения 18 моделей с различным значением гиперпараметра количества тем (от 2 до 19) модель с 5 темами имела самую большую метрику согласованности 0,68. Для интерпретации полученных результатов используется модуль pyLDAvis:
vis = pyLDAvis.gensim.prepare(model, corpus, dictionary)Результатом работы pyLDAvis является интерактивная карта набора тем. На карте в правой части располагается топ слов, входящих в тему, а в левой части расположены темы в виде кругов. Темы могут быть как независимыми друг от друга, так и пересекаться, за счет вхождения слов в несколько тематик.
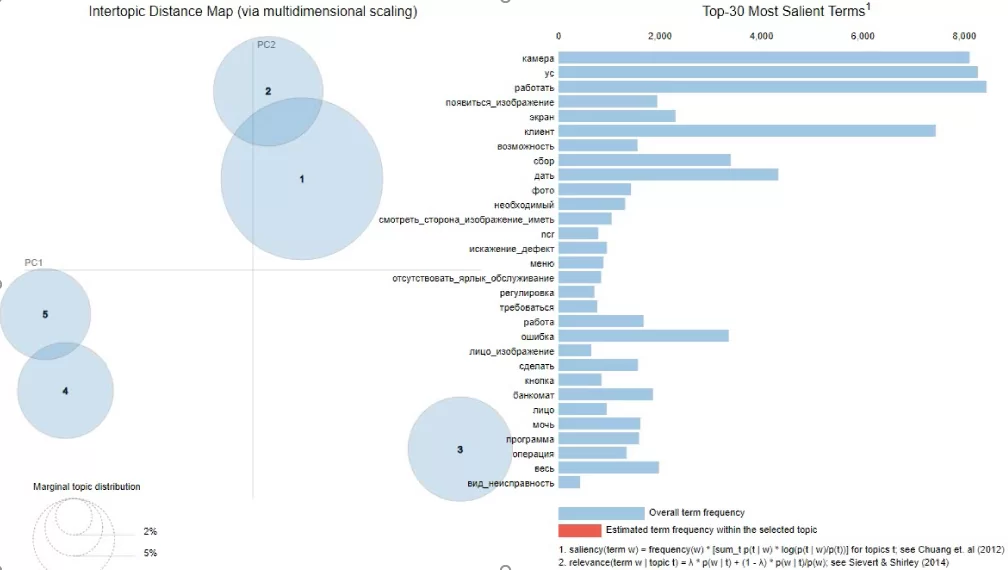
Выделяя один из кругов тем слева, справа видим слова, входящие в эту тему, по которым можем определить, о чем данная тематика. Пример ниже указывает на тему 5, связанную с проблемами в оборудовании – нет изображения с камеры.
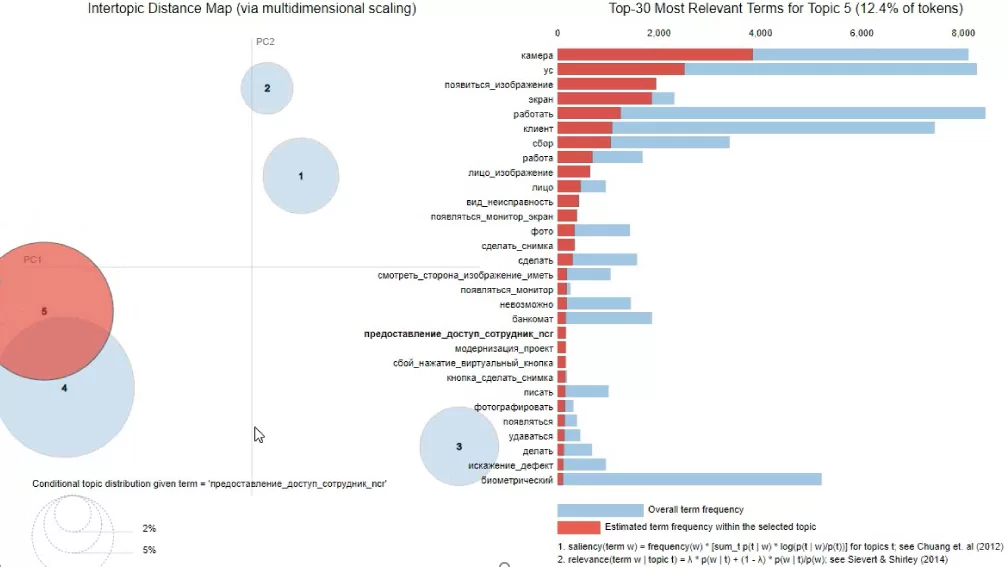
Чтобы определить к какой теме относится то или иное обращение из dataframe для последующего анализа, загружаем обученную модель и корпус, подаем на вход текст поля «Описание»:
model=LdaMulticore.load("model_IM_atm.lda")
corp = corpora.BleiCorpus("corpus_IM_atm.lda-c")
df_topic_sents_keywords = format_topics_sentences(ldamodel=model,
corpus=corp, texts= df['clean_txt'].tolist())
В итоге, методом тематического моделирования LDA выявлены 5 глобальных тематик жалоб по текстам обращений внутренних и внешних клиентов.