/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Анализ данных, как правило, состоит из нескольких этапов: очистка данных, вычисление признаков и реализация алгоритма машинного обучения с этими признаками. Эти этапы похожи на конвейер и выполняются в основном последовательно. Но случается так, что после отработки нескольких этапов возникает необходимость что-нибудь немного изменить в признаках или функциях. Это может потребовать повторного пересчёта промежуточных результатов, на которые внесённые изменения никак не влияют, что влечёт за собой дополнительные временные затраты. Чтобы избежать излишних вычислений и реализовать параллельное выполнение процессов (там, где это возможно) в Python существует пакет jug, основными преимуществами которого являются возможность запоминания результатов вычислений на диске и выполнение задач на разных ядрах или компьютерах.
Например, мы ещё не знаем точно, какую модель использовать и предстоит отработка нескольких алгоритмов машинного обучения. При этом, объём данных достаточно большой для того, чтобы датасет с очищенными данными хранить в памяти. Рассмотрим код ниже:
import pandas as pd
import numpy as np
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import GradientBoostingClassifier
import datetime
start = datetime.datetime.now()
print(start)
dataset = pd.read_csv('train.csv')
X = dataset.iloc[ : , 2 : ]
y = dataset.iloc[ : , 1 : 2 ]
toDel = ['Name', 'Ticket', 'Cabin', 'Embarked']
X.drop(toDel, inplace=True, axis=1)
X = np.array(X)
y = np.array(y)
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [1])],
remainder='passthrough')
X = np.array(ct.fit_transform(X))
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer.fit(X)
X = imputer.transform(X)
sc = StandardScaler()
X[:, 2:] = sc.fit_transform(X[:, 2:])
gbc = GradientBoostingClassifier(learning_rate=0.5, max_depth=5, n_estimators=150)
gbc.fit(X, y)
X_test = pd.read_csv('test.csv', index_col=0)
count = ['Name', 'Ticket', 'Cabin', 'Embarked']
X_test.drop(count, inplace=True, axis=1)
X_test = np.array(X_test)
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [1])],
remainder='passthrough')
X_test = np.array(ct.fit_transform(X_test))
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer.fit(X_test)
X_test = imputer.transform(X_test)
sc = StandardScaler()
X_test[:, 2:] = sc.fit_transform(X_test[:, 2:])
gbc_predict = gbc.predict(X_test)
np.savetxt('my_gbc_predict.csv', gbc_predict, delimiter=",", header = 'Survived')
endd = datetime.datetime.now()
print('Start: ', start, '\n\rEnd: ', endd)
print(endd-start)
Результат выполнения кода:
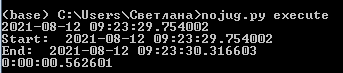
Для примера был взят известный датасет для задачи о пассажирах Титаника. Как видно, здесь проводится чтение файла с исходными тренировочными данными, затем преобразование некоторых столбцов, удаление ненужных данных и дубликатов. После этого выбирается и обучается модель, а затем загружается тестовый набор данных, который также подготавливается к применению модели. В таком виде даже поблочный запуск кода будет заново выполнять все указанные инструкции, использовать память и другие ресурсы. Даже если переписать всё в виде функций. Хотя результат выполнения из-за малого размера данных (891 строка), на первый взгляд, не вызывает никаких вопросов, можно написать такой вариант:
from jug import TaskGenerator
from sklearn.externals import joblib
import datetime
import numpy as np
start = datetime.datetime.now()
print(start)
@TaskGenerator
def prepare_data(file, train = True):
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
toDel = ['Name', 'Ticket', 'Cabin', 'Embarked']
if train:
df = pd.read_csv(file)
df.drop(toDel, inplace=True, axis=1)
X = df.iloc[ : , 2 : ]
y = df.iloc[ : , 1 : 2 ]
X = np.array(X)
y = np.array(y)
joblib.dump(y, 'y.pkl')
pklname = 'X_train.pkl'
else:
X = pd.read_csv('test.csv', index_col=0)
X.drop(toDel, inplace=True, axis=1)
X = np.array(X)
pklname = 'X_test.pkl'
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [1])],
remainder='passthrough')
X = np.array(ct.fit_transform(X))
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer.fit(X)
X = imputer.transform(X)
sc = StandardScaler()
X[:, 2:] = sc.fit_transform(X[:, 2:])
joblib.dump(X, pklname)
@TaskGenerator
def model_fit():
from sklearn.ensemble import GradientBoostingClassifier
X = joblib.numpy_pickle.load('X_train.pkl')
y = joblib.numpy_pickle.load('y.pkl')
gbc = GradientBoostingClassifier(learning_rate=0.5, max_depth=5, n_estimators=150)
gbc.fit(X, y)
joblib.dump(gbc, 'model.pkl')
@TaskGenerator
def predict():
X = joblib.numpy_pickle.load('X_test.pkl')
model = joblib.numpy_pickle.load('model.pkl')
gbc_predict = model.predict(X)
np.savetxt('my_gbc_predict.csv', gbc_predict, delimiter=",", header = 'Survived')
prepare_data('train.csv')
model_fit()
prepare_data('test.csv', False)
predict()
endd = datetime.datetime.now()
print('Start: ', start, '\n\rEnd: ', endd)
print(endd-start)
#сохраняем файл с именем jugfile.py
#запускаем из командной строки командой jug execute
Результат использования jug:
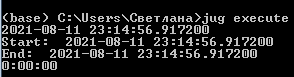
Приведённый выше код отличается от первоначального тем, что все необходимые вычисления производятся один раз и записываются на диск, освобождая память для дальнейших операций. Инструкция @TaskGenerator указывает на то, что функция используется как задача в конвейере. Если его потребуется запустить ещё раз, то будут использоваться уже сохранённые данные и выполнение займёт значительно меньшее время. Как видно из рис. 2, результат был получен быстрее, чем в предыдущем варианте.
Мы рассмотрели простейший пример использования пакета jug для анализа данных, но его можно использовать и для других задач, где требуется проведение похожих операций, требующих проведения длительных вычислений, которые можно производить параллельно. При этом совершенно не важно, какую библиотеку нужно использовать, даже если задача не подразумевает использования никаких импортируемых библиотек, можно каждую операцию оформить в виде конвейера задач, например, так:
def to_cube(x):
return x**3
from jug import Task
t1 = Task(to_cube, 3)
t2 = Task(to_cube, 5.7)