/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Классификация текстов является довольно распространенной задачей, которую решают аналитики данных в любой сфере деятельности. Для того чтобы построить качественный классификатор текста необходимо не только правильно подобрать классификатор, но и обеспечить качественный и объемный датасет, на котором будет обучаться выбранный классификатор. В реальном мире сложно при решении бизнес-задач найти такой датасет, в котором были бы относительно сбалансированные классы, а самих текстов было бы достаточное количество для того чтобы обучить качественную модель. Чтобы решить такую часто возникающую на практике проблему, зачастую применяются синтетические методы обогащения исходного датасета но основе имеющихся данных. В данной статье будет продемонстрирован пример использования цепей Маркова для генерации новых текстов.
Для демонстрации работы возьмем отзывы для некоторого сайта (https://docs.google.com/spreadsheets/d/12KBzzsXkze-yNebnlC2—sOcdMTbxcn_X5DhBbb8sVo/edit?usp=sharing). Всего в датасете присутствует 741 текст, который принадлежит 13 классам.
import pandas as pd
import numpy as np
from google.colab import drive
drive.mount('/content/drive')
source_texts = pd.read_csv('/content/drive/MyDrive/сlassifier/All_classes.csv', sep='\t')
source_texts['Classes'].value_counts()
Распределение по классам представлено на рисунке:
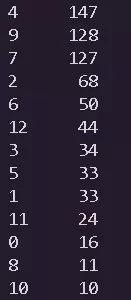
Датасет является несбалансированным, а количество классов, которые он в себе содержит, заставляет предполагать, что классификатор, построенный на таком скудном наборе будет работать не очень хорошо. Чтобы убедиться в этом, обучим на представленном датасете логистическую регрессию.
import pandas as pd
import matplotlib.pyplot as plt
import random
random.seed(1228)
from sklearn.metrics import *
from sklearn.pipeline import Pipeline
%matplotlib inline
from sklearn.model_selection import train_test_split
from nltk.stem.snowball import RussianStemmer
Результат обучения представлен на рисунке:
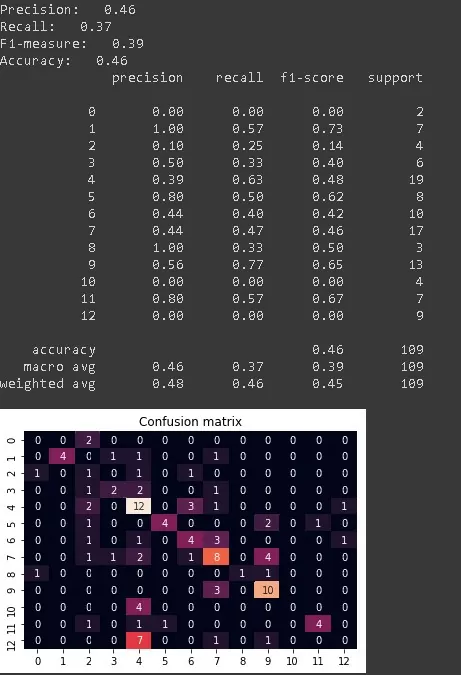
Одной из главных проблем, которые могут помешать классификатору качественно выполнять свою работу может быть то, что в представленном датасете классы не сбалансированы, а текстов по любому из представленных классов довольно мало. Для решения данной проблемы обратимся к цепям Маркова.
Цепь Маркова — инструмент из теории случайных процессов, состоящий из последовательности n количества состояний. Связи между узлами (значениями) цепочки при этом создаются, только если состояния стоят строго рядом друг с другом.
В данном примере рассмотрим готовую реализацию цепи Маркова на языке python.
from pymarkovchain import MarkovChainДля того чтобы обогатить наш датасет и сбалансировать классы пройдем циклом по нашим классам и сгенерируем новые тексты на основе имеющихся.
for cl in np.unique(source_texts['Classes']):
check_df = source_texts[source_texts['Classes']==cl]
needs = len(check_df['texts'])
if needs<147:
print(cl)
mc = MarkovChain("./markov")
texts = ".".join(list(check_df['texts']))
mc.generateDatabase(texts)
for i in range(147-needs):
source_texts = source_texts.append({'texts': mc.generateString(), 'Classes': cl, 'Key_words': check_df.iloc[2,0]}, ignore_index=True
Таким образом, мы дополнили наши тексты так, чтобы каждый класс содержал в себе столько же экземпляров, сколько содержит в себе мажоритарный класс. Для того чтобы оценить, как работает цепь, выведем пример генерации.
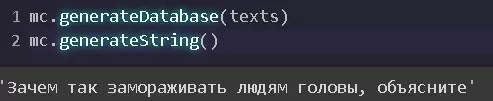
Чтобы оценить, насколько лучше стал работать классификатор, переобучим его заново.
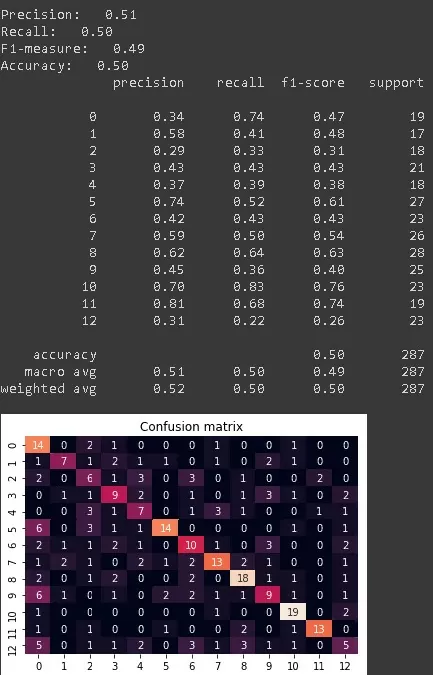
Как видно на рисунке, качество значительно повысилось, что подтверждает предположение о том, что инструмент, рассмотренный в данной статье, позволяет улучшить качество модели. Таким образом, мы рассмотрели инструмент, позволяющий увеличить объемы данных, которые мы используем для обучения модели.
Еще больше информации о Process Mining можно найти и обсудить в канале #process_mining сообщества ODS.AI в slack