/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 4 мин.
Довольно часто, при аудите сервисов, работающих с внешними финансовыми потоками, возникает необходимость оценки корректности получения, обработки и хранения внешней информации в СУБД компании. Одним из таких примеров является аудит системы биржевой торговли Quik. Для анализа необходима информация о котировках ценных бумаг за продолжительный период времени с различной детализацией (от минуты до дня). Разумеется, требуется информация не об одной или двух котировках, а о десятках или сотнях. В решении данной проблемы поможет python библиотека apimoex, предоставляемая непосредственно Московской биржей, которая доступна по следующей ссылке.
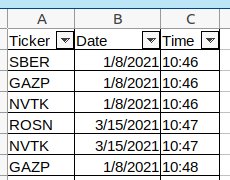
Данные о необходимых котировках и временных интервалах предоставляются в виде excel файла, состоящего из трех колонок: название бумаги, дата, время.
Для начала скачаем необходимые библиотеки, для этого запустим команду:
pip install apimoex requests pandasПосле установки необходимых библиотек, импортируем их внутри нашего проекта:
import requests
import apimoex
import pandas as pd
import sys
Далее задаем режим торгов:
board = 'TQBR'Откроем наш файл с помощью модуля pandas и производим препроцессинг данных:
df_excel = pd.read_excel(“path to excel file”)
column_name = [i for i in df_excel]
df_excel[column_name[1]] = df_excel[column_name[1]].map(str).map(lambda x: x[:10])
df_cotir = df_excel.drop_duplicates(subset=[column_name[0], column_name[1]])
df_cotir[column_name[0]] = df_cotir[column_name[0]].map(str)
ticks = [line.rstrip() for line in df_cotir[column_name[0]]]
dates = [line.rstrip() for line in df_cotir[column_name[1]]]
Стоит отметить, что api биржи позволяют скачать данные только за заданный период времени, а не в определенную минуту. Поэтому мы будем скачивать данные поминутно за весь день, а потом отбирать необходимые минуты.
Скачивать сами данные будем с помощью функции get_board_candles с параметрами:
- session – Сессия интернет соединения
- security – Тикер ценной бумаги
- interval – Размер свечки — целое число 1 (1 минута), 10 (10 минут), 60 (1 час), 24 (1 день), 7 (1 неделя), 31 (1 месяц) или 4 (1 квартал). По умолчанию дневные данные
- start – Дата вида ГГГГ-ММ-ДД. При отсутствии данные будут загружены с начала истории
- end – Дата вида ГГГГ-ММ-ДД. При отсутствии данные будут загружены до конца истории. Для текущего дня будут загружены не окончательные данные, если торги продолжаются
- columns – Кортеж столбцов, которые нужно загрузить — по умолчанию момент начала свечки и HLOCV. Если пустой или None, то загружаются все столбцы
- board – Режим торгов — по умолчанию основной режим торгов T+2
- market – Рынок — по умолчанию акции
- engine – Движок — по умолчанию акции
Далее открываем сессию для экспорта котировок сохраняем полученные результаты в список из pandas DataFrame:
tick_history, process = list(), 0
with requests.Session() as session:
for i in range(len(ticks)):
process = process + 1
print((process / len(ticks)) * 100, '%', process)
data = apimoex.get_board_candles(session, security=ticks[i], interval=1, start=dates[i], end=dates[i], board=board, market=market_type)
if data == []:
continue
df = pd.DataFrame(data)
df['TICKER'] = ticks[i]
cols = df.columns.tolist()
cols = cols[-1:] + cols[:-1]
df = df[cols]
tick_history.append(df)
Далее объединяем список котировок в pandas DataFrame и преобразовываем колонку с временем и датой в две:
df_finale = pd.concat(tick_history)
df_finale['begin'] = pd.DataFrame(df_finale['begin'])
df_finale['date'] = df_finale['begin'].map(lambda x: x[:10])
df_finale['time'] = df_finale['begin'].map(lambda x: x[11:])
Остается выбрать данные с необходимым нам временем:
cols = df_finale.columns.tolist()
cols = cols[:1] + cols[-2:] + cols[1:-2]
df_finale = df_finale[cols]
df_finale.drop('begin', 1)
df_finale['date'] = df_finale['date'].map(str)
df_finale["time"] = df_finale["time"].map(str).map(lambda x: x[:5])
df_excel = df_excel.rename({column_name[2]: "time", column_name[1]: 'date', column_name[0]: 'TICKER'}, axis=1)
df_finale = pd.merge(df_finale, df_excel[['TICKER', 'date', "time"]], on=['TICKER', 'date', "time"], how='inner')
В конце, сохраняем результат в csv файл:
df_finale.drop_duplicates().to_csv("result.csv", index=False, sep='|')Загруженные данные можно агрегировать до нужных таймфреймов:
import datetime
def add_delta(tme, delta=1):
if tme != None:
tme =list(map(int, tme.split(':')))
tme = datetime.time(tme[0],tme[1],0)
return (datetime.datetime.combine(datetime.date.today(), tme) + datetime.timedelta(minutes=delta)).time()
timewindow = datatime.time (hours = 13, minutes = 43)
df_hour_frame = df_finale[(df_finale ['time'] >= timewindow) & (df_finale['time'] <= add_delta(timewindow, datatime.timedelta(minutes = 60))]
df_hour_frame['low in range'] = df_hour_frame['low'].min()
df_hour_frame['high in range'] = df_hour_frame['high'].max()
df_hour_frame['max value in range'] = df_hour_frame['value'].max()
df_hour_frame['min value in range'] = df_hour_frame['value'].min()
Представленный подход позволяет произвести независимую оценку корректности работы автоматизированных систем компании с использованием данных первоисточника и выявить проблемы с некорректным реплицированием данных в СУБД либо задержки в получении данных.