/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Сегодня рассмотрим плагины Kedro, которые позволяют рассмотреть ml-алгоритм в графически-структурированном виде.
В прошлой части статьи мы рассмотрели создание pipeline для анализа данных с помощью ml-алгоритма. В этой части уделим внимание инструментам, которые упростят понимание в использовании и настройке вашего проекта. В рамках статьи будем ссылаться на код, представленный в репозитории.
В первую очередь, посмотрим на работу всего pipeline проекта, который реализовали в прошлой статье. Для этого необходимо установить пакет kedro-viz. После успешной установки, в командной строке запустим команду:
kedro vizПосле запуска, kedro запустит локальный сервер и предложит перейти по следующему адресу:
http://127.0.0.1:4141/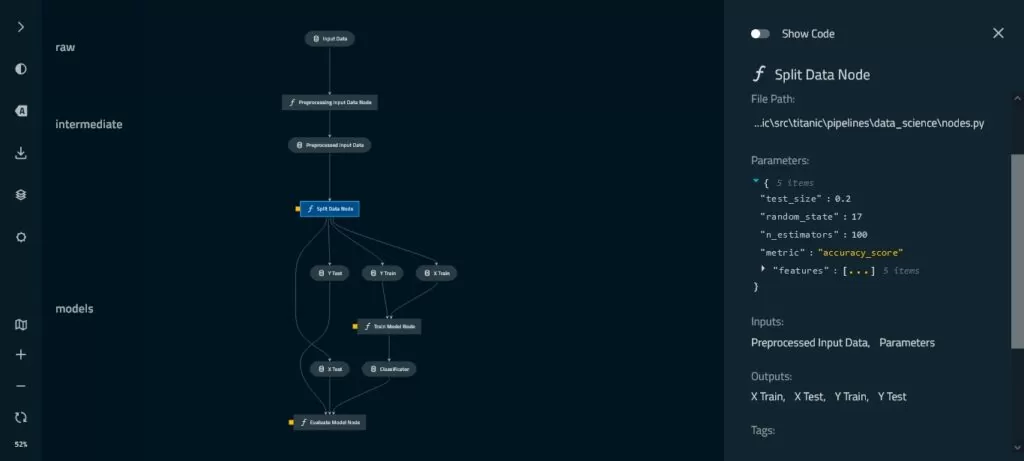
Здесь мы можем увидеть все этапы проекта, где для каждого элемента pipeline представлена описательная информация. Для данных — это тип и физическое расположение. Для функций – это расположение в файле проекта, параметры, входные и выходные данные. Дополнительно можно просмотреть полный код функции, переключив ползунок «Show Code».
Также можно добавить в визуализацию отображение стадий (raw, intermediate, models и т.д) в рамках data engineering соглашения. Для этого необходимо отредактировать файл titanic\conf\base\catalog.yml, где добавим параметр «layer».
Таким образом, если после продолжительного перерыва вы решили вспомнить, что же происходит в данной папке с проектом или решили показать коллеге или Product Owner’у подход по работе с данными, то плагин viz как раз то, что вам нужно.
В kedro реализована надстройка над библиотекой mlflow, благодаря которой можно отслеживать значение метрик модели при различных значениях входных параметров. Для начала нам необходимо установить пакет kedro-mlflow. Далее добавим в исходный код логирование параметров:
\titanic\src\titanic\pipelines\data_science\nodes.py import mlflow
from mlflow import sklearn
в функцию split_data:
mlflow.log_param("test_size", parameters["test_size"])
mlflow.log_param("random_state", parameters["random_state"])
mlflow.log_param("features", parameters["features"])
в функцию train_model:
mlflow.log_param("n_estimators", parameters["n_estimators"])
в функцию evaluate_model:
mlflow.log_metric(parameters["metric"], score)
И инициализируем mlflow в kedro:
kedro mlflow initТаким образом, после каждого запуска pipeline (kedro run) будет осуществляться запись логируемых параметров, подробности можно найти в официальной документации.
Для просмотра результатов, при различных параметрах, запустим команду:
kedro mlflow uiИ перейдем по адресу:
http://127.0.0.1:5000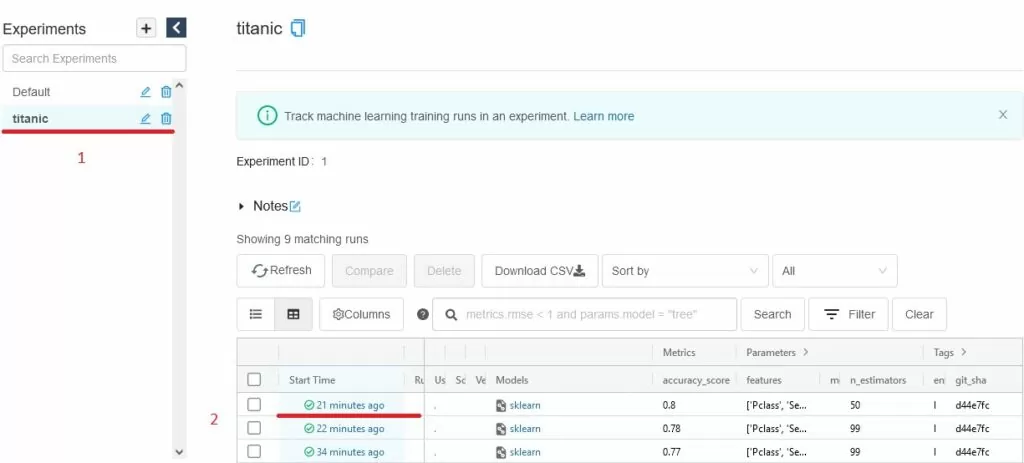
В появившемся окне, в левом верхнем углу перейдем во вкладку с именем проекта, где будет отображена вся информация по каждому запуску pipeline. Для более детального просмотра можно перейти по ссылке в столбце «Start Time».
Таким образом, мы можем отслеживать результат работы алгоритма на различных этапах взаимодействия с данными, в том числе различное состояние параметров, модели ml-алгоритма, версию git и т.д.
Следующий важный этап проектирования алгоритма – создание документации. Документация в Kedro формируется при помощи Sphinx. Для документирования методов и классов используются двойные кавычки, которые трижды дублируются в начале и конце описания метода. Для описания аргументов функций будем использовать следующие атрибуты:
:param [ParamName]: [ParamDescription] – для описания входных аргументов
:type [ParamName]: [ParamType] – указание типа входных аргументов
:return: [ReturnDescription] - для описания выходных данных
:rtype: [ReturnType] - указание типа выходных данных
:raises [ErrorType]: [ErrorDescription] – для описания исключений в методе
Для примера составим простое описание для пары методов из этапа предобработки данных
titanic\src\titanic\pipelines\data_processing\nodes.py:Для метода cat_to_num:
"""
Convert categorical value to numeric
:param arr: array of string values
:type arr: numpy array
:return: dict of {srt: int} values
:rtype: dict
"""
Для метода preprocess_dataset:
"""
Label encoding for two columns "Sex" and "Embarked"
:param df: dataframe with ["Sex", "Embarked"] columns
:type df: pandas DataFrame
:return: dataframe with prepared columns
:rtype: pandas DataFrame
"""
Стоит отметить, что Sphinx чувствителен к пробелам после двоеточий, и пропуску строки к основному описанию метода.
Остается запустить команду:
kedro build-docsЧто создаст полный стек документации к вашему проекту в следующем виде:
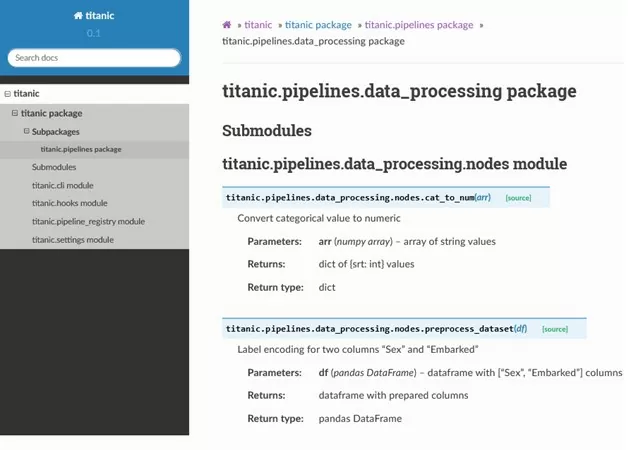
Таким образом, для создания документации нужно лишь добавить «docstring» в методы проекта и вызвать команду «kedro build-docs», после чего сформируется файл index.html в директории titanic\docs\build\html с полной структурой проекта.
Как видим, с помощью простых манипуляций и вызова пары команд возможно представить сложную структуру проекта в подробном и наглядном виде. В статье затронули лишь малую часть функционала Kedro, в официальной документации вы найдете различные «трюки», которые помогут в разработке и поддержке Вашего проекта.