/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Одна из ключевых задач в анализе данных — сопоставление и визуализация разных наборов информации. Это также актуально для аудита, т.к. в ходе проверок мы собираем колоссальное количество разных данных, которые необходимо структурировать, сравнивать и представлять максимально наглядно. Зачастую нам приходится иметь дело с результатами проведенных опросов, заполненными чек-листами по проверкам и т.д.
В этой статье я расскажу о возможностях языка Python для визуализации пересечений множеств, об основных плюсах и минусах представленных методов.
Рассмотрим в качестве примера опрос для сотрудников по внутренним сервисам, т.к. в нем возможны совершенно разные вопросы, которые могут предполагать множественный выбор ответа, а не только «да» или «нет».

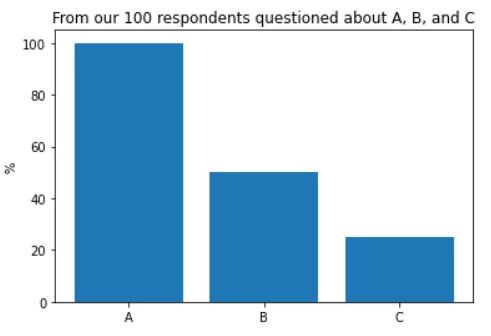
Допустим, что мы опросили 100 респондентов, причем у них было только 3 варианта ответа. На выходе мы получили следующую картину:
50 ответов – А и В;
25 ответов – А и С;
25 ответов – только А.
Гистограмма
На получившейся диаграмме мы видим, что ответ А выбрали 100 респондентов, ответ В – 50 и ответ С – 25, но она не показывает нам информацию о пересечении респондентов, выбравших кроме ответа А, ответы В или С. Кроме того, по этой диаграмме можно сделать ошибочное заключение, что в опросе приняли участие 175 респондентов.
Для решения этой проблемы лучше использовать диаграммы Венна – инструмент Python Matplotlib-Venn.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib_venn import venn3, venn3_circles
from matplotlib_venn import venn2, venn2_circles
Подготавливаем и загружаем данные для анализа. В нашем вопросе 6 вариантов ответа, их мы распределяем по 6 столбцам. При выборе варианта ответа, информация появится в поле, в обратном случае – поле останется пустым. Таким образом, мы получим 6 списков с информацией об индексах, выбравших тот или иной вариант респондентов.
df = pd.read_csv ('Service_opros.csv')
nm = 'Какими сервисами Вы пользовались?'
d1 = df[~df[nm].isnull()].index.tolist() # A
d2 = df[~df[nm+'_1'].isnull()].index.tolist() # B
d3 = df[~df[nm+'_2'].isnull()].index.tolist() # C
d4 = df[~df[nm+'_3'].isnull()].index.tolist() # D
d5 = df[~df[nm+'_4'].isnull()].index.tolist() # E
d6 = df[~df[nm+'_5'].isnull()].index.tolist() # F
Диаграммы Венна очень просты и удобны. Мы передаем наборы с данными для последующего изучения. Venn2 используем при наложении двух наборов, Venn3 – трех. Разберем на примере трех наборов данных:
venn3([set(d1), set(d2), set(d5)],
set_colors=('#3E64AF', '#3EAF5D', '#D74E3B'),
set_labels = ('A', 'B', 'E'),
alpha=0.75)
venn3_circles([set(d1), set(d2), set(d5)], lw=0.7)
plt.show()
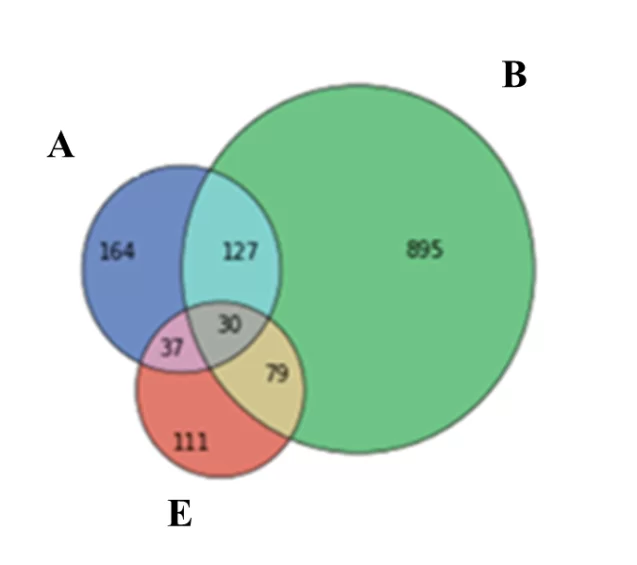
На диаграмме Венна показано, что по результатам опроса 895 респондентов выбрали сервис B, 164 респондента – сервис A и 111 респондентов – E. При этом мы видим, пересечение ответов: 127 респондентов использовали A и B, 79 – B и E, 37 – A и E, а также 30 респондентов, которые выбрали все три сервиса.
Если мы решим показать пересечение более трех наборов данных с помощью этого инструмента, то столкнемся со сложностями в восприятии итоговых диаграмм:
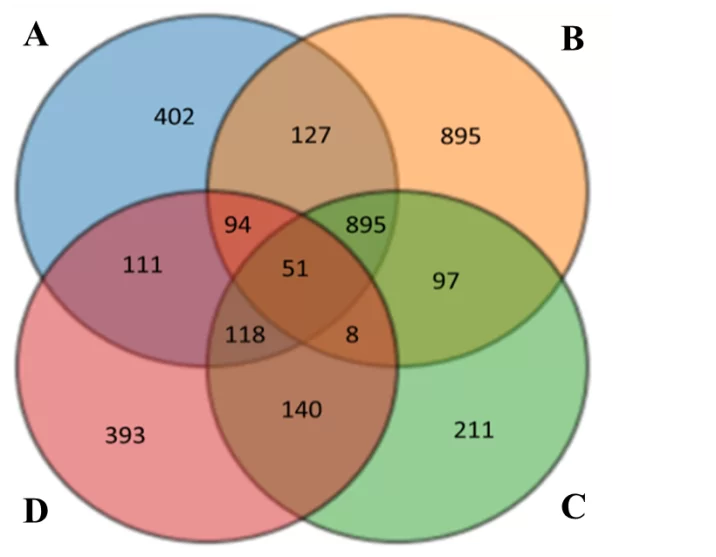
По рисунку сложно определить, сколько респондентов при опросе выбрали только 2 варианта A и C, на их пересечении также изображены варианты B и D. Обратите внимание, что размер пересечений на изображении не соответствует действительности. Например, респондентов, выбравших вариант B (895) и их должно быть больше, чем выбравших вариант С (211), но на диаграмме они равны.
Для решения данной проблемы воспользуемся Графиками UpSet, они не так просты для восприятия как диаграммы Венна, но решают вопрос визуализации пересечения нескольких наборов данных.
upset_df = pd.DataFrame()
col_names = ['A', 'B', 'C', 'D', 'E', 'F']
nm = 'Какими сервисами Вы пользовались?'
for idx, col in enumerate(df[[nm, nm+'_1', nm+'_2', nm+'_3', nm+'_4', nm+'_5']]):
temp = []
for i in df[col]:
if str(i) != 'nan':
temp.append(True)
else:
temp.append(False)
upset_df[col_names[idx]] = temp
upset_df['c'] = 1
example = upset_df.groupby(col_names).count().sort_values('c')
example
Построим диаграмму:
upsetplot.plot(example['c'], sort_by="cardinality")
plt.title('Какими сервисами Вы пользовались?', loc='left')
plt.show()
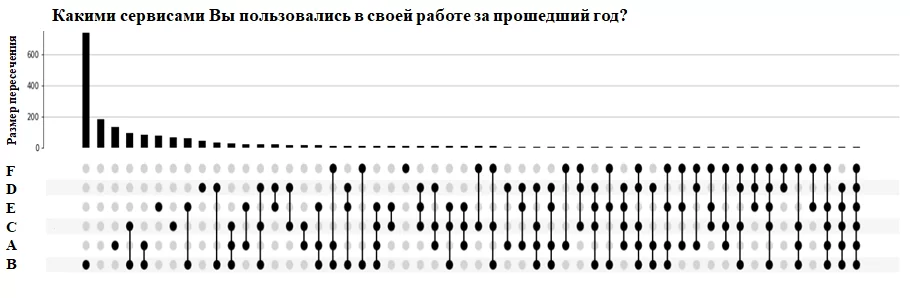
График UpSet
Столбцы вверху диаграммы показывают количество повторений комбинации вариантов. Матрица внизу – какую комбинацию описывает каждый столбец, а горизонтальная гистограмма – размер каждого отдельного набора.
Мы видим, что наиболее часто (800 респондентов) выбирали только ответ В, при этом ответ встречался более, чем 1000 раз. Следующий по популярности набор ответов среди респондентов – не выбран ни один ответ (примерно 200 человек так поступили), а реже всех встречался ответ F.
Стоит отметить, что один из вариантов вообще не отображался на диаграммах Венна: не выбран ни один ответ, а сейчас эта информация достаточно наглядно представлена.
На мой взгляд, диаграммы Венна удобны при работе с небольшим набором множеств, а графики Upset более наглядны, когда множеств три и более.