/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
В нашей деятельности довольно часто приходится работать с большими объемами документов, к примеру, исполнительными листами, заявлениями, договорами, из текстов которых нам зачастую необходимо извлечь весьма конкретную информацию: ФИО, даты рождения, наименования должности, паспортные данные, адрес, ИНН и наименование компаний, даты подписания документов и так далее. Всё это относится к задаче распознавания именованных сущностей (NER). Так какие инструменты могут помочь нам в решении данной задачи для русского языка?
Пожалуй, первое что приходит в голову Data Scientist’у, когда речь идет о NLP или конкретно NER-задачах — это проекты DeepPavlov. Давайте немного углубимся в данную тему, разберем все по порядку.
DeepPavlov — это фреймворк (open source), который помогает в разработке различных голосовых ботов, соответственно, решая различные NLP задачи.
На вход подается непредобработанный (регистры, знаки и т.д. сохранены) текст, а на выходе мы хотим увидеть, так называемые, спаны — фрагменты текста, с которыми уже можно работать (например, отнести к определенной категории).
Закончим лирическое отступление и перейдем к практике. Всю работу осуществляем в Colab. Установим Natasha (поддерживает Python версии 3.5 и выше):
!pip install natashaЕсли говорить вкратце, то она умеет решать базовые (и не только базовые, но сегодня поговорим только о них) задачи NLP для русского языка, такие как: токенизация, лемматизация/нормализация фраз (или имен), определение частей речи и многое другое.
Импортируем нужные нам модули:
from natasha import Segmenter, MorphVocab, NewsEmbedding, NewsMorphTagger, NewsSyntaxParser, NewsNERTagger,NamesExtractor, DocЕсть мнение, что данного рода фреймворки хорошо работают с новостными статьями (что логично, ведь там очень часто встречаются именованные сущности). Давайте возьмем какую-нибудь хорошую новость из топа новостей Яндекса:
news = '9.12.2021 «Спартак» на выезде сыграл с польской «Легией» в матче заключительного тура группового этапа Лиги Европы.' \
'Красно-белые победили со счетом 1:0 благодаря голу Бакаева. Ранее в Москве спартаковцы уступили со счетом 0:1.' \
'На 98-й минуте матча в ворота спартаковцев был назначен пенальти. Вратарь красно-белых Селихов отразил 11-метровый.' \
'Эта победа гарантировала «Спартаку» попадание в плей-офф Лиги Европы.'
Передадим текст с данной новостью в Doc(). Далее сегментируем наш текст (Natasha использует для этого еще одну свою разработку именуемую «Раздел» (https://github.com/natasha/razdel )), посмотрим на первые и последние 5 токенов:
segmenter = Segmenter()
footballNews.segment(segmenter)
for i in range(5): print(footballNews.tokens[i])
for i in range(5): print(footballNews.tokens[-5+i])
(Пример) out:
DocToken(stop=9, text='9.12.2021')
Первый токен — цельная дата проведения матча, не разбитая на мелкие токены, соответственно, даты, скорее всего, будут распознаваться корректно.
Перейдем к морфологии и разберем последнее предложение:
embedding = NewsEmbedding()
morphTagger = NewsMorphTagger(embedding)
footballNews.tag_morph(morphTagger)
footballNews.sents[0].morph.print()
(Пример) out:
Вратарь NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
красно-белых ADJ|Case=Gen|Degree=Pos|Number=Plur
Селихов PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
С помощью этого метода мы имеем возможность определять часть речи, пол и многое другое в зависимости от текста.
С лемматизацией (процессом приведения слова к нормальной форме) проблем также не обнаружено. Эта задача решается с помощью известной многим разработкой Яндекса Pymorphy (https://pymorphy2.readthedocs.io/en/stable/user/guide.html ):
morphVocab = MorphVocab()
for token in footballNews.tokens:
token.lemmatize(morphVocab)
{_.text: _.lemma for _ in footballNews.tokens}
(Пример) out:
{'Бакаева': 'бакаев',
'Вратарь': 'вратарь',
'Европы': 'европа',
'Красно-белые': 'красно-белый',
'Легией': 'легия'}
Вполне неплохой результат, двигаемся дальше.
Давайте научимся добывать именованные сущности из текста:
footballNews.tag_ner(nerTagger)
footballNews.ner.print()
(Пример) out:
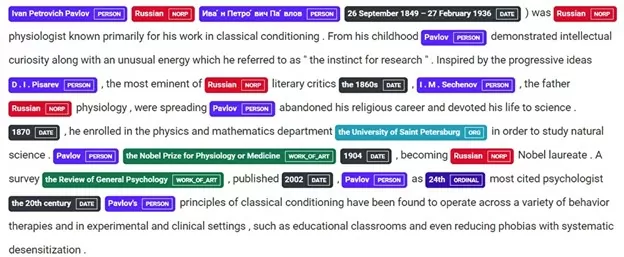
9.12.2021 «Спартак» на выезде сыграл с польской «Легией» в матче
ORG──── ORG───
заключительного тура группового этапа Лиги Европы.
Natasha для удобства подчеркивает именованную сущность для быстрого анализа текста глазами, для любителей работать в Jupyter Notebook есть возможность даже настроить «подсветку» сущностей. Natasha определила футбольные клубы к организациям, фамилии игроков к личностям, а город к локации. Результат положительный.
Вдогонку к лемматизации — можно нормализовать слова, которые не нормализованы в тексте:
for span in footballNews.spans:
span.normalize(morphVocab)
{_.text: _.normal for _ in footballNews.spans if _.text != _.normal}
out:
{'Бакаева': 'Бакаев',
'Легией': 'Легия',
'Москве': 'Москва',
'Спартаку': 'Спартак'}
На самом деле этот небольшой разбор лишь вершина айсберга возможностей, которые предоставляют нам разработчики DeepPavlov. Фреймворк покрывает значительную часть ad-hoc задач Data Scientist’а, многое отлично работает, как говорят, «из коробки». Проблемы могут возникнуть при обработке неструктурированных данных (ПДФ файлы), которые не сохраняют регистр, пунктуацию, пробелы, но это уже совсем другая история…
Еще одним интересным инструментом для решения задачи NER является библиотека SpaCy. SpaCy распознает различные типы именованных сущностей с помощью прогноза предобученных языковых моделей. Итак, импортируем библиотеку и посмотрим на что она способна.
import spacyДля использования языковой модели, необходимо ее подгрузить.
ru_model = spacy.load("ru_core_news_md")Передав наши приятные футбольные новости в созданный объект, на выходе мы получим обработанный документ, который будет содержать всю информацию исходного текста.
Токенизация – это первое, что делает SpaCy с полученным текстом. При этом применяются правила, специфичные для языка текста. Проведем токенизацию первого предложения нашего текста.
vocab = {}
for token in doc:
if token.text not in vocab.keys():
vocab[token.text] = 1
else:
vocab[token.text] += 1
print(vocab)
(Пример) out:

Отлично, дата целостная, как и в результате работы Natasha. Также выводится количество вхождений токена в текст.
Посмотрим, как обстоят дела с лемматизацией и приведем новости в нормальную форму:
def lemmat(text):
doc = rus_model(text)
tokens = [token.lemma_ for token in doc]
return " ".join(tokens)
(Пример) out:
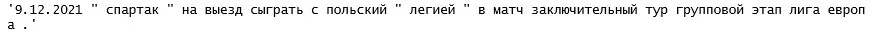
Выведем из приятных новостей только те слова, которые изменились:

Получилось довольно неплохо, за исключением футбольного клуба Легии.
Именованные сущности извлекаются очень просто. Так же есть возможность подсветить их прямо в тексте с указанием типа, для этого воспользуемся модулем displacy, который входит в пакет spaCy.
from spacy import displacy
for ent in doc.ents:
print(ent.text,ent.start_char, ent.end_char, ent.label_)
displacy.render(doc, style = 'ent')
(Пример) out:

Отлично, результат совпадает с Natasha. Проведем морфологический анализ текста.
for ent in doc:
print(ent.text,ent.tag_,ent.morph)
(Пример) out:

В теги выводятся характеристики слова в зависимости от части речи.
Мы рассмотрели базовые возможности библиотек, которые быстро и просто помогут решить NLP задачи. Их можно использовать и в процессе предобработки данных, и для простого извлечения именованных сущностей.