/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 4 мин.
Вообще, стоит сказать, что в странное время живём. Уже не новость, что длинные щупальца ML пробрались везде, куда-только можно было, от рекомендаций в ритейле, до анализа медицинских данных, всё меньше и меньше неизведанного и чего-то нового, что было бы интересно с исследовательской точки зрения. А если ничего не исследовать, то как так жить вообще?
С другой стороны, смешалось в кучу всё, и пока одни уже ждут пришествия SkyNet, а другие stack more layers, а на выходе все равно предсказывается собака, которая кошка, хочется немного абстрагироваться от всего этого и найти задачу, которая предполагает некую долю исследовательской составляющей и при этом оригинальна и специфична.
Здесь всегда на помощь приходит физика, ну и IDAO (International Data Analysis Olympiad)
Международная олимпиада по анализу данных, которая уже в четвертый раз проводится НИУ ВШЭ и Яндексом.
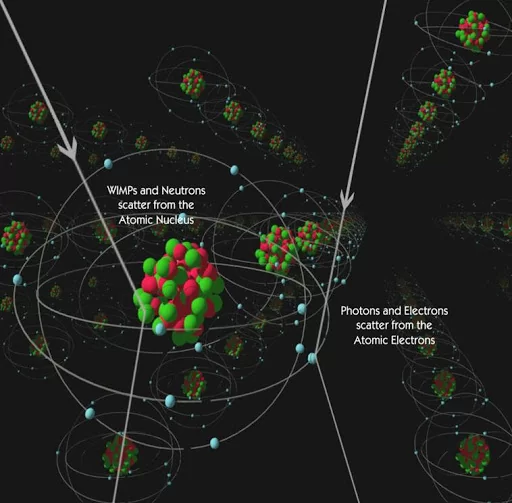
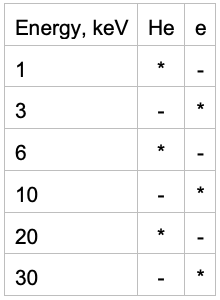
В этот раз задача формировалась следующим образом. Нужно было классифицировать два типа частиц и предсказать их энергию.
Первый тип частиц представлен следующим образом (1, 3, 6,10,20, 30 килоэлектронвольт соответственно).
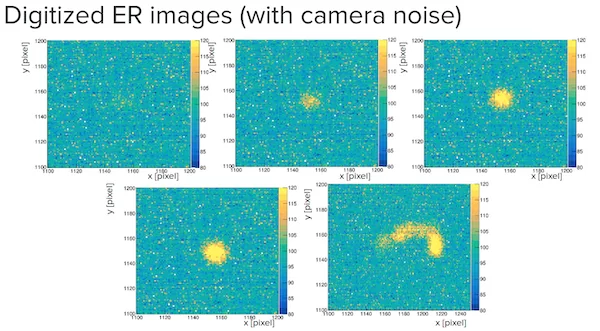
Второй тип частиц представлен следующим образом (1, 3, 6,10,20, 30 килоэлектронвольт соответственно).
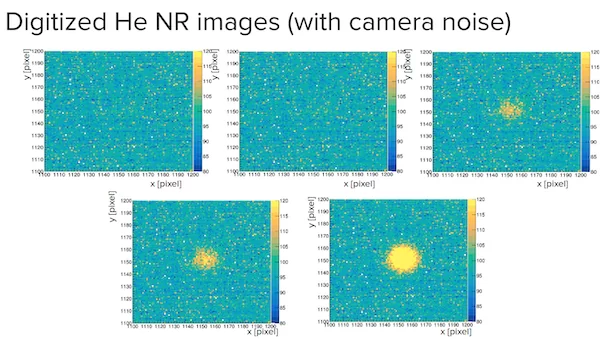
Особенностью данного соревнования является то, что в тренировочном датасете и в тестовом находятся разные классы. А классы из тестового датасета представлены лишь несколькими фотографиями.
Обучающая выборка содержит 2200 примеров каждого обучающего класса и по 2 примера каждого тестового класса. Известны энергии и типы частиц для обучающего набора данных. Публичная тестовая выборка содержит 250 примеров каждого из обучающих классов. Приватная тестовая выборка содержит 2500 примеров из каждого тестового класса. Поэтому нужно осторожно подходить к обучению.
Для начала реализуем скрипт, который увеличит количество изображений наименее представленных классов используя следующие трансформации изображения(инвертирование относительно осей, повороты на 90 градусов). Таким образом из 12 изображений получилось 144, что составляет около 1% тренировочной выборки. Не так много, но уже что-то.


Далее, будет осуществлен препроцессинг и преобразование в тензоры. В качестве оптимального варианта, вырежем центр с картинки и сожмём его до 110 пикселей по длине и ширине.
Далее построим две нейросети для классификации и регрессии. Архитектура нейростетей приведена ниже. При обучении будем использовать scheduler, для понижения learning_rate.
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 108, 108, 32) 320
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 54, 54, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 52, 52, 32) 9248
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 26, 26, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 24, 24, 64) 18496
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 12, 12, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 9216) 0
_________________________________________________________________
dense_1 (Dense) (None, 64) 589888
_________________________________________________________________
activation_1 (Activation) (None, 64) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 64) 0
_________________________________________________________________
dense_2 (Dense) (None, 1) 65
=================================================================
Total params: 618,017
Trainable params: 618,017
Non-trainable params: 0
____________________________
Предсказания регрессии округлим для ближайшего возможного значения энергии. Сам код для обучения расположен в репозитории.
Отборочный этап продолжался примерно месяц и за это время удалось добиться следующих результатов. В первом и втором треке (соответственно). Второй трек отличался от первого наличием жёстких ограничений на инференс.
390.13 - private score [15058 items], score = auc - mae
public: 0.999226950355 0.00732356857523
private: 0.98443193283 0.594302032142
218.89 - private score [14908 items], score = auc - mae
public: 0.999957333333 0.0326666666667
private: 0.970230421163 0.751341561578
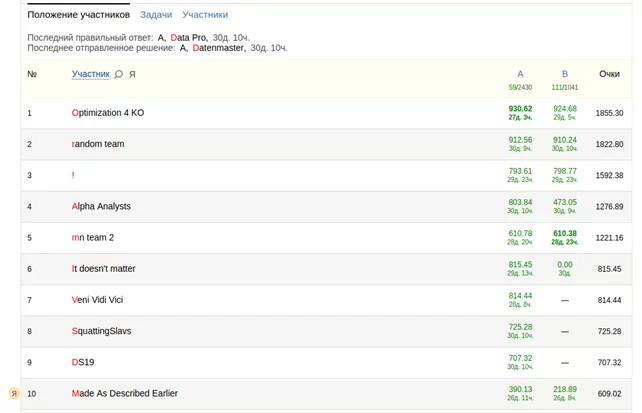
Судя по всему, удалось частично избежать переобучения и на привате подняться на 10 место с 11 по двум трекам суммарно(из 166), занять 6 место во втором треке и попасть в финал.
Увидимся в финале, который пройдёт удаленно 17-18 апреля.
Код доступен в репозитории
Результаты 2021 года доступны по ссылке