/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
При работе с большими данными каждый аналитик хочет, чтобы запросы в базы данных выполнялись мгновенно, ну или хотя бы просто быстро. Именно для такой скоростной обработки массивных запросов я познакомился с Apache Hive (Система управления базами данных на основе платформы Hadoop. Позволяет выполнять запросы, агрегировать и анализировать данные, хранящиеся в Hadoop).
Расскажу вам о своем опыте использования Hive и нескольких лайфхаках, позволяющих упростить работу с данным инструментом.
В самом начале работы с Hive, я столкнулся с проблемой выгрузки данных в MS Excel или CSV, т.к. в Hive было установлено ограничение по выгрузке таблиц не более 100 тыс. строк.
Так как же выгрузить таблицу более 100 тыс. строк быстро?
Я расскажу, как это можно сделать через Apache Beeline и File Browser.
Apache Beeline.
Для выгрузки данных через Apache Beeline необходимо подключиться к серверу по SSH, к примеру, через WinSCP или Python.
Алгоритм выгрузки через WinSCP.
- Подключаемся к серверу через WinSCP
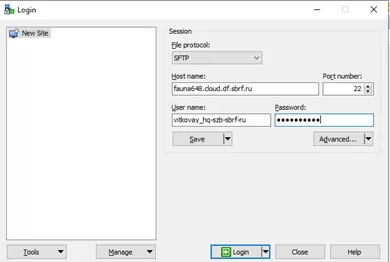
- Через терминал запускаем команду (для запуска из команды необходимо убрать все «\n»):
«—delimiterForDSV=’;’» — разделитель для CSV;
«—outputformat=dsv» — формат выгружаемых данных;
«-e “ваш запрос”» — запрос в базу данных.
beeline -u 'jdbc:hive2://fauna647.cloud.df.sbrf.ru:10000/default;
principal=hive/_HOST@DF.SBRF.RU'
--incremental=true --incrementalBufferRows=1000 --showHeader=true
--outputformat=dsv --delimiterForDSV=';'
-e "
SELECT *
FROM internal_friendface_smadmin.incidentsm1
LIMIT 100;
" > /home/vitkovay_hq-szb-sbrf-ru/Query.csv
3. После выполнения команды, результат выгрузки будет сохранен на сервере в файл «Query.csv»
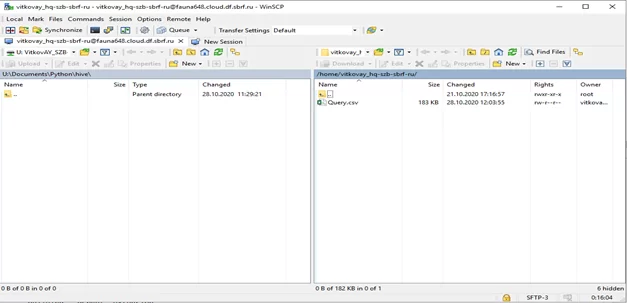
Алгоритм выгрузки через Python.
- Подключаемся к серверу через модуль paramiko в Python
import paramiko
client = paramiko.SSHClient()
client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
client.connect('fauna648.cloud.df.sbrf.ru',
username='username',
password='password')
2. Подготавливаем наш запрос и команду для paramiko
bash = '''
beeline -u 'jdbc:hive2://fauna647.cloud.df.sbrf.ru:10000/default;
principal=hive/_HOST@DF.SBRF.RU'
--incremental=true --incrementalBufferRows=1000 --showHeader=true --outputformat=dsv --delimiterForDSV=';'
-e "
SELECT *
FROM internal_friendface_smadmin.incidentsm1
LIMIT 100;
" > /home/vitkovay_hq-szb-sbrf-ru/Query.csv
'''
bash = bash.replace('\n', ' ')
3. Запускаем команду с помощью «open_sftp()» сохраняем результаты запроса на локальном компьютере.
stdin, stdout, stderr = client.exec_command(bash)
sftp = client.open_sftp()
sftp.get('/home/vitkovay_hq-szb-sbrf-ru/Query.csv', 'Query.csv')
sftp.close()
Результат выполнения запроса будет сохранен в файл «Query.csv»
File Browser.
Для выгрузки через File Browser нам понадобятся права на создание таблиц.
- Устанавливаем параметры создания таблицы, которые помогут нам объединить все партиции исходных таблиц в один файл для выгрузки
SET hive.merge.mapfiles=true;
SET hive.merge.mapredfiles=true;
SET hive.merge.smallfiles.avgsize=16000000;
SET hive.merge.size.per.task=2256000000;
SET hive.merge.tezfiles=true;
2. Подготавливаем запрос и создаем таблицу, которую надо выгрузить в файл
CREATE TABLE team_sva_audit.table_with_data
STORED AS TEXTFILE
AS
SELECT *
FROM internal_friendface_smadmin.incidentsm1
LIMIT 100;
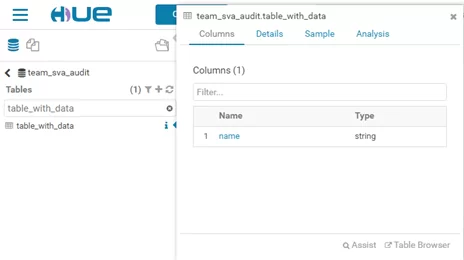
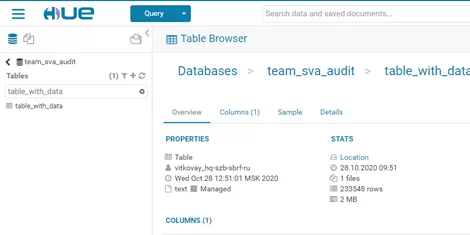
3. После отработки запроса заходим в раздел информации по таблице и «проваливаемся» в «Location». Отсюда можно скачать файл с данными
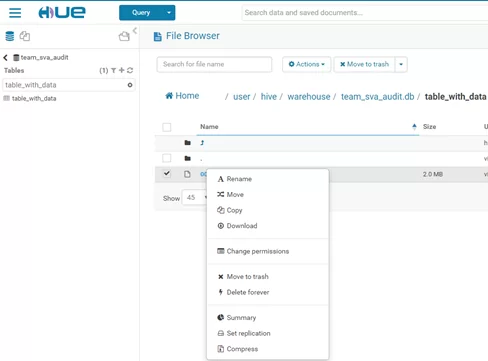
Итак, я вам показал несколько способов выгрузки таблиц размером более 100 тыс. срок из Apache Hive с использованием нескольких инструментов, а именно с помощью WinSCP и Python. Дальше уже эти данные можно использовать для построения моделей машинного обучения и проведения Process Mining.