/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 6 мин.
Данные не только не всегда очевидно указывают на определенную группу, порой непонятно даже сколько таких групп. Для решения подобного рода проблем существует целый класс задач машинного обучения — кластеризация. Данный класс задач относится к категории unsupervised learning, то есть обучение без размеченных данных, поэтому является очень ценным в условиях, когда исследование только начинается. Эта статья посвящена решению проблемы группировки пользователей по собранной статистике методами кластеризации.
Возьмем для примера данные пользователей, которые заходили на сайт компании и кликали на ссылки. При помощи подходящего link tracker посчитаем количество кликов по тем или иным элементам сайта за определенное время от каждого зарегистрированного пользователя, просуммируем, например, по неделям и пронормируем на среднее. Для примера рассмотрим сгенерированный датасет.
Начнем с генерации сета, имитирующего поведение трех групп пользователей, кликающих по 5 ссылкам с 1000 разных аккаунтов. Для этого воспользуемся методом make_blobs из пакета sklearn.
from sklearn.datasets import make_blobs
import numpy as np
data, pregenerated= make_blobs(1000,n_features=5,cluster_std=4)В массив data будут записаны пять фич, каждая из которых является суммой трех гауссиан с центрами в трех разных точках, которые и являются кластерами. Имена этих заранее известных кластеров записаны в переменной pregenerated. Построим фичи друг относительно друга:
from pandas.plotting import scatter_matrix
import pandas as pd
scatter_matrix(pd.DataFrame(data), alpha=0.2, figsize=(6, 6), )
pd.Series(pregenerated).value_counts()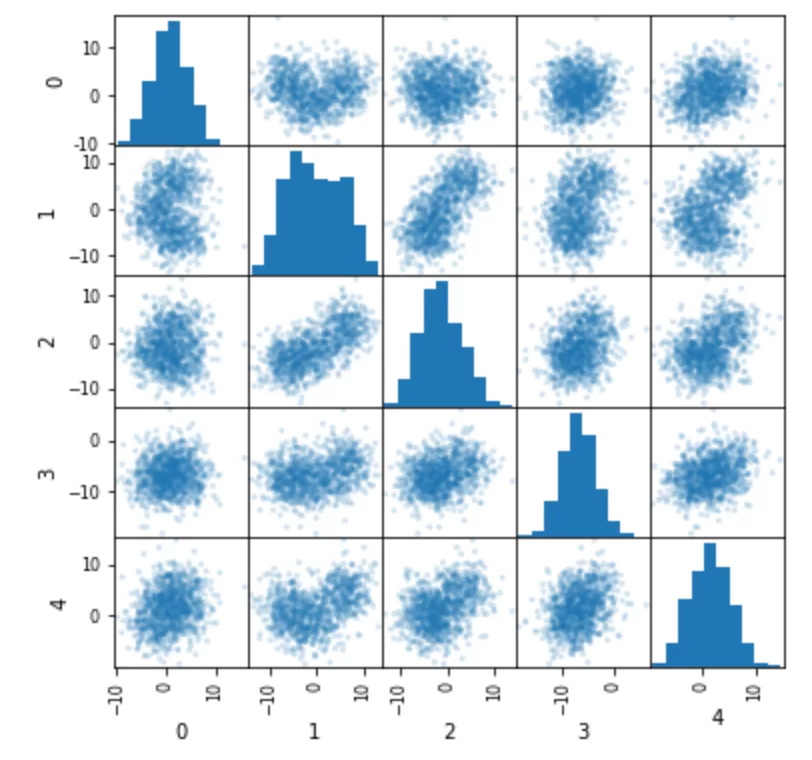
Видно, что по фичам ничего невозможно понять — даже сколько там кластеров. Это весьма похоже на реальные данные. Преобразуем массив данных в датасет и назовем фичи так, как будто это и есть реальные данные.
result_df = pd.DataFrame(data)
result_df.columns = ["каталог","доставка","о нас","реклама","адреса"]
result_df["группа"] = pregenerated
result_df.head() 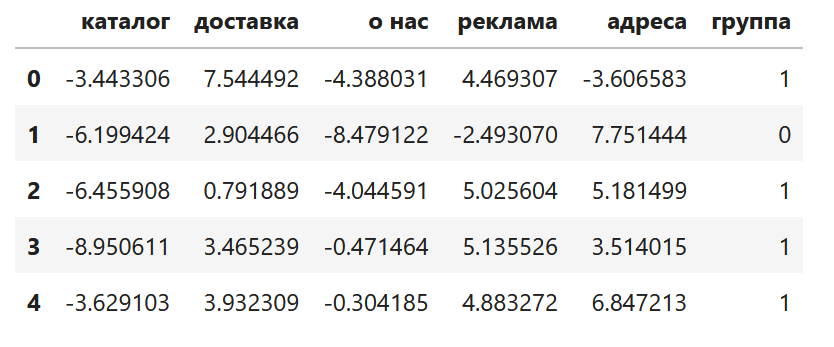
Далее понаблюдаем, как даже самый базовый метод кластеризации легко справляется с задачей группировки данных. Прогоним полученный датасет через популярную модель для кластеризации — k-means. Ее главный минус в том, что нужно знать заранее количество кластеров. Обычно это решается либо эмпирически, либо моделями способными на поиск количества кластеров, таких как DBSCAN. У нас же количество кластеров известно заранее.
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3).fit(data)Для валидации построим распределение как изначальных, так и предсказанных кластеров.
result_df["предсказанные"] = kmeans.labels_
print(result_df["группа"].value_counts())
print(result_df["предсказанные"].value_counts())
result_df.head()0 334
2 333
1 333
Name: группа, dtype: int64
0 341
1 333
2 326
Name: предсказанные, dtype: int64
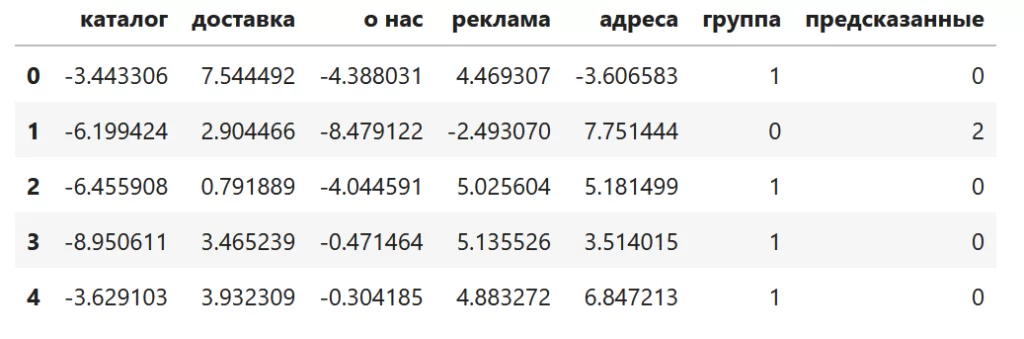
Поскольку мы заранее знали к какому кластеру принадлежит тот или иной пользователь — мы ведь их сами создавали — есть возможность проверить насколько хорошо справился k-means со своей задачей. В соответствии с вышеприведенной частью датасета переназначим найденные алгоритмом кластеры и сравним их с сгенерированными:
temp = result_df["предсказанные"].map({2:0,0:1,1:2}) - result_df["группа"]
temp.value_counts(normalize=True)0 0.971
-1 0.018
1 0.011
dtype: float64
Впечатляющее качество распознавания! К сожалению, в реальных данных этой информации как правило нет, а если есть, то это уже supervised learning и изначально нужно было решать задачу классификации, а не кластеризации. Проблему сложности восприятия табличных данных о кластерах принято решать графически при помощи dimensional reduction, что позволяет все фичи ужать до двух, x и y, и построить их на графике. Существует много алгоритмов dr, мы покажем один из самых популярных из-за своей красоты t-sne.
from matplotlib import pyplot as plt
from sklearn.manifold import TSNE
tsne_df = TSNE(n_components=2,perplexity=20).fit_transform(data)
result_df["tsneX"] = tsne_df[:,0]
result_df["tsneY"] = tsne_df[:,1]
plt.scatter(result_df["tsneX"], result_df["tsneY"],s=2,)
plt.savefig("blobs_gray.jpg",dpi=1200,transparent=True)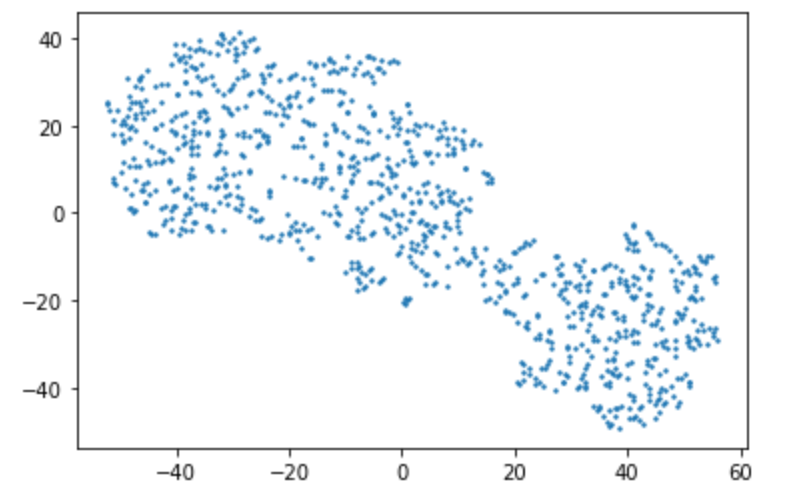
Как мы видим, пять фич сжались до двух, чтобы уместиться на плоскости. Кроме того, точки разделились на несколько различимых взглядом агломератов. Для проверки выделим точки справа по координатам и посмотрим какие из изначально созданных групп пользователей в него входят.
result_df[(result_df['tsneX']>15) & (result_df['tsneY']<5)]["группа"].value_counts()0 325
1 19
Name: группа, dtype: int64
Действительно, соответствует сгенерированному кластеру с кодом 0.
Если бы это были реальные данные, мы бы многое поняли о пользователях из этого графика — во первых группы пользователей действительно есть, их как минимум две, во вторых — все пользователи пользуются всеми ссылками, просто с разной интенсивностью, ведь кластеры связаны. Чтобы извлечь больше выводов из этого графика, можно добавить в него больше внешней информации. Проще всего изменению поддаются цвет точек, их фон и размер. Красить точки и фон лучше в категориальные фичи, размер же отведен для численных. В данном примере у нас нет никаких категориальных фич, кроме, собственно, кластеров к которым принадлежат точки. Покрасим точки на графике в цвета согласно известным нам заранее группам пользователей, для валидации. Этой информации у модели не было.
def colorer(row,column):
if row[column] == 1:
return "Green"
if row[column] == 2:
return "Brown"
return "Magenta"
result_df["цвет"] = result_df.apply(colorer,axis = 1,column = "группа")
plt.scatter(result_df["tsneX"], result_df["tsneY"],s=2,c=list(result_df['цвет']))
plt.savefig("blobs_colored.jpg",dpi=1200,transparent=True)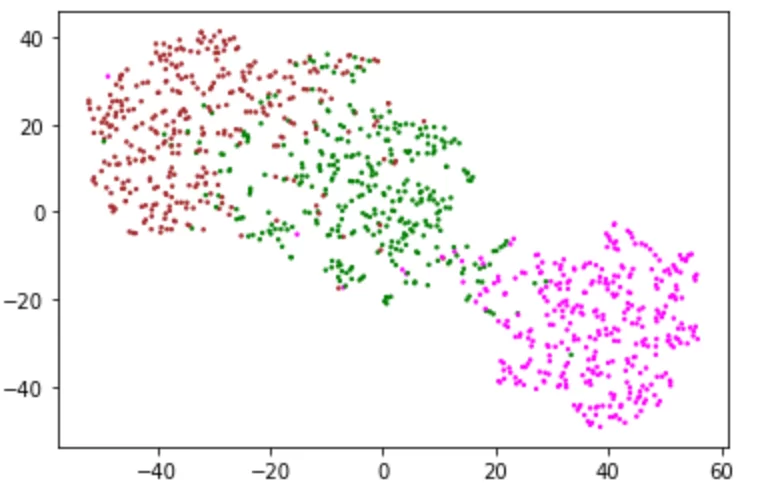
Метод t-sne сумел отделить фиолетовый кластер от двух других. В реальной ситуации в качестве цвета обычно выступает собранная помимо статистики переходов по ссылкам эвристика, например user agent их браузера, или их участие/неучастие в опросе, или проведенное на странице время. Бывает так, что кластеры видны плохо и выводы делать трудно. Для визуального определения помимо цвета можно использовать размер точек, делая более важные точки больше. При анализе поведения пользователей одной из самых важных для визуализации фич является активность.
Для примера сгенерируем ее при помощи случайных чисел, зависящих от номера кластера
result_df["активность"] = np.random.randint(1,10, len(result_df))*(result_df["группа"]+0.1)
plt.scatter(result_df["tsneX"], result_df["tsneY"],s=list(result_df['активность']),c=list(result_df['цвет']))
plt.savefig("blobs_size.jpg",dpi=1200,transparent=True)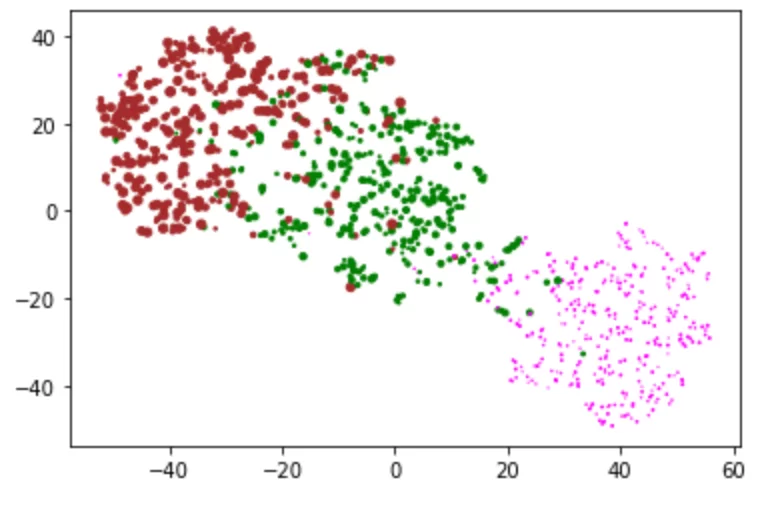
Видно, что в фиолетовый кластер входили самые неактивные пользователи, а в коричневый — самые активные. При этом случайные вбросы фиолетового цвета в зеленый стали менее видны, и это плюс, ведь нам важнее поведение активных пользователей, нежели чем неактивных.
Параметр размера также можно использовать для создания фона под картинкой, добавляя второй scatter на тот же график, с большим размером точки s и низкой прозрачностью alpha
result_df["фон"] = result_df.apply(colorer,axis = 1,column = "предсказанные")
plt.scatter(result_df["tsneX"], result_df["tsneY"],s = 100, c=list(result_df['фон'])
,marker = "o",alpha = 0.05)
plt.scatter(result_df["tsneX"], result_df["tsneY"],s=list(result_df['активность']),c=list(result_df['цвет']))
plt.savefig("blobs_background.jpg",dpi=1200,transparent=True)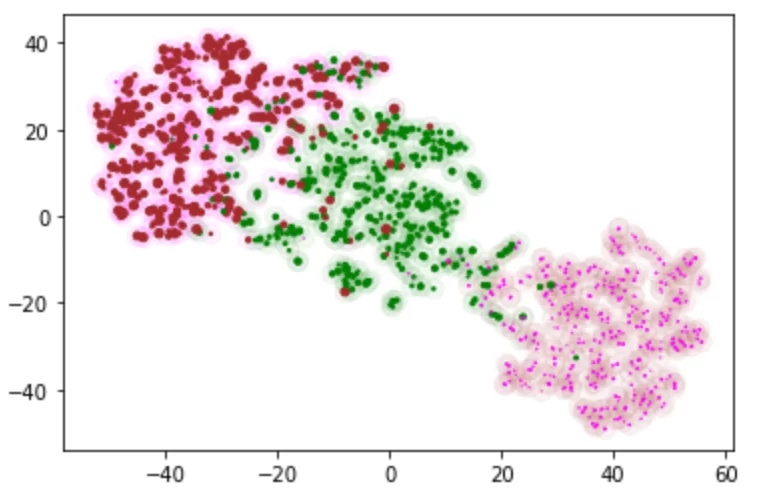
Использование фона очень полезно, если есть возможность эвристически распределить пользователей в другие группы, не связанные с поведением, например на фон можно поместить категорию размера города для каждой точки.
На этом этап построения графиков заканчивается, и начинается анализ результатов, включающий демонстрацию графика коллегам, поиск скрытых в нем инсайдов и многого другого, выходящего за рамки статьи. Совокупность вышеперечисленных подходов применима к любым неразмеченным данным, и была успешно использована для выявления интереса (и отсутствия интереса) к продуктам среди посетителей определенного сайта. Подобное исследование может дать пищу для размышлений в рамках выполнения обязанностей аналитиков, маркетологов и аудиторов.
Код можно скачать по ссылке https://github.com/RomanKrekhno/table_recognition_example/blob/master/clustering%20example.ipynb