/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Для начала вспомним что такое GROUP BY. Итак, GROUP BY – конструкция, которая используется в SQL для группировки данных по полю при использовании в запросе функций агрегации (например, SUM, MAX, MIN и д.р.) либо для исключения дублирования строк (как эквивалент ключевого слова DISTINCT).
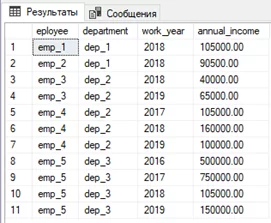
Теперь же рассмотрим расширения GROUP BY, которые позволяют получать промежуточные итоги и итоги в целом — ROLLUP, CUBE и GROUPING SETS. Создадим тестовую таблицу и заполним ее данными.
CREATE TABLE #tmp
(
[eployee] nvarchar(10), --сотрудник
[department] nvarchar(10), --подразделение
[work_year] int, --год
[annual_income] money –доход
)
Начнем с ROLLUP, который вернет нам общую суммирующую строку. Например, мы хотим посмотреть сколько сотрудников в каждом подразделении и их доход за все время работы. Для этого напишем простой запрос:
SELECT
[department]
,COUNT(DISTINCT [eployee]) as employess_count
,SUM([annual_income]) as common_income
FROM #tmp
GROUP BY [department]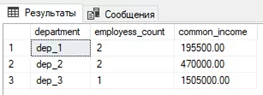
А если нам необходимы общее количество сотрудников и их совокупный доход? Тут на помощь и придет ROLLUP.
SELECT
[department]
,COUNT(DISTINCT [eployee]) as employess_count
,SUM([annual_income]) as common_income
FROM #tmp
GROUP BY ROLLUP([department])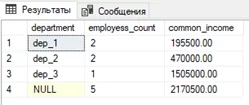
Также ROLLUP нам пригодится, если мы хотим увидеть промежуточный итог с доходом каждого сотрудника за все время работы.
SELECT
[eployee]
,[work_year]
,SUM([annual_income]) as common_income
FROM #tmp
GROUP BY ROLLUP([eployee],[work_year])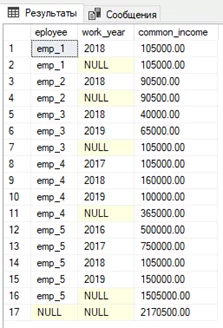
Строки, отмеченные красными стрелками, будут промежуточным итогом по сотруднику за все его время работы, а фиолетовыми – общая суммирующая строка.
Следующий на очереди — CUBE. Он похож на ROLLUP по двум столбцам из предыдущего примера за тем исключением, что CUBE добавляет суммирующие строки для каждой комбинации групп.
SELECT
[eployee]
,[work_year]
,SUM([annual_income]) as common_income
FROM #tmp
GROUP BY CUBE([eployee],[work_year])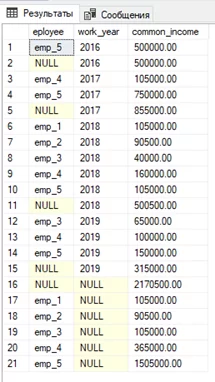
В нашем случае красными стрелками показаны итоги по каждому году для всех сотрудников, которые работали в этом году, синими – общие итоги по каждому сотруднику за все время работы, а фиолетовыми – общая суммирующая строка, как при использовании ROLLUP.
Но что делать, если мы хотим видеть только суммирующие строки для групп? Ответ на этот вопрос – использовать GROUPING SETS. Он, как и ROLLUP и CUBE, добавляет суммирующую строку для групп, но при этом не включает сами группы.
SELECT
[eployee]
,[work_year]
,SUM([annual_income]) as common_income
FROM #tmp
GROUP BY GROUPING SETS([eployee],[work_year])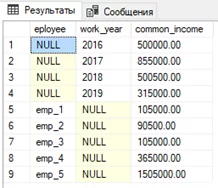
То есть на примере видим результат выполнения CUBE, из которого исключены промежуточные итоги и общий суммирующий итог.
Описанные расширения конструкции GROUP BY позволяют легко сформировать необходимые итоги, не прибегая к использованию подзапросов и облегчая код.