/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Как рационально организовать процесс движения?
На это вопрос может дать ответ логистика. Общеизвестный факт: когда логист спит – затраты увеличиваются 🙂
Попробую осветить тему оптимизации перевозок с использованием Graph Mining глазами Data Engineer.
В работе использовал следующие библиотеки Python:
- pandas — для хранения и обработки данных;
- sklearn — для группировки адресов по группам;
- requests — для запросов на сервер с целью вычисления расстояния маршрутов с учетом дорог;
- geocoder — для получения координат адресов.
Рассмотрим задачу, в которой есть некоторые количество перевозок (с одной точкой подачи) с разными точками назначения. В моем примере таких будет — 7. Задача состоит в том, чтобы уменьшив количество поездок и оптимизировав маршрут, мы добились уменьшения километража, а вследствие и затрат.
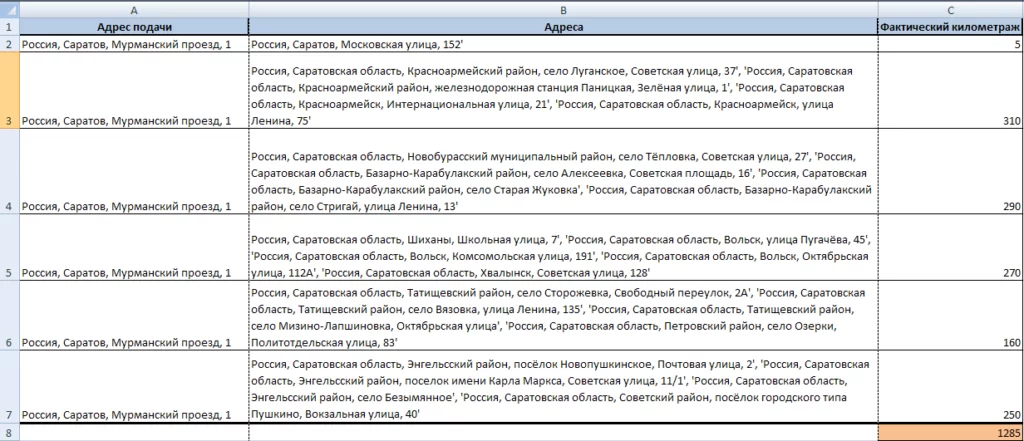
Данные будем хранить в excel:
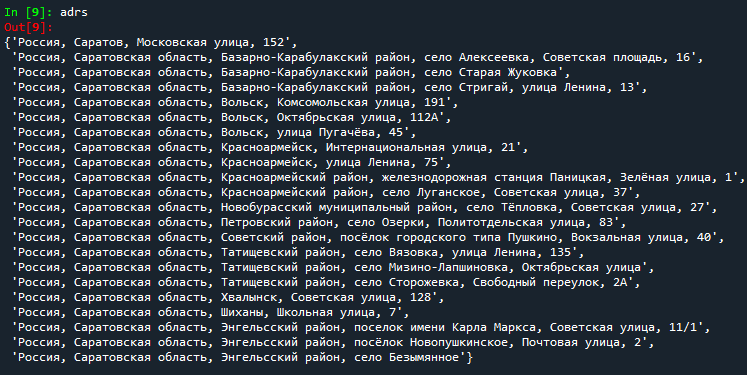
Для начала считаем данные: берем все уникальные адреса назначения в массив.
routes = pd.read_excel('логистика без К-3.xlsx', sheet_name='Лист3')
adrs = []
for i in routes.index:
adrs += routes['Адреса'][i].split("', '")
adrs[-1] = adrs[-1].replace("'",'')
adrs = set(adrs)
Результат:
Далее необходимо получить таблицу вида: «Адрес — Координата Х — Координата Y». Для этого используем словарь и dataframe, а координаты адресов получим с помощью библиотеки geocoder.
adrs = set(adrs)
coords = []
for i in adrs:
g = geocoder.arcgis(i)
temp = {'x': g.latlng[0], 'y': g.latlng[1]}
coords.append(temp)
coords = pd.DataFrame(coords, index = adrs)
Теперь мы можем отобразить все адреса в виде графа:
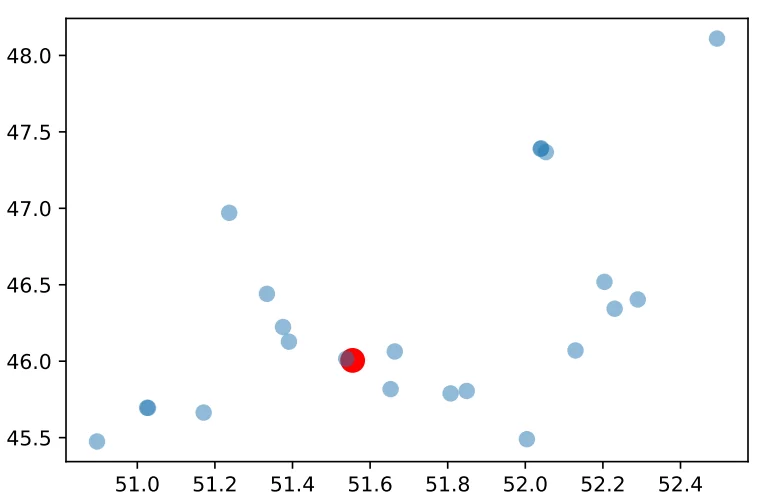
Красным обозначен адрес подачи, остальные точки – адреса назначения.
Теперь, требуется разбить все точки на группы, так чтобы получить несколько оптимальных маршрутов. Здесь нам поможет метод ближайшего соседа (K-means) с помощью библиотеки sklearn:
n = 4
kmeans = KMeans(n_clusters=n).fit(coords)
Можно подбирать различное значение n, при котором суммарное расстояние будет минимальным. В данном случае оптимальным значением n является 4. На выходе получаем n количество классов (групп), в каждый из которых можно посылать одну машину на доставку.
Результат можно посмотреть, написав следующий код:
plt.scatter(center.latlng[0], center.latlng[1], s=125, c='red')
plt.scatter(coords['x'], coords['y'], c= kmeans.labels_.astype(float), s=50, alpha=0.5)
plt.savefig('foo.pdf')
plt.show()
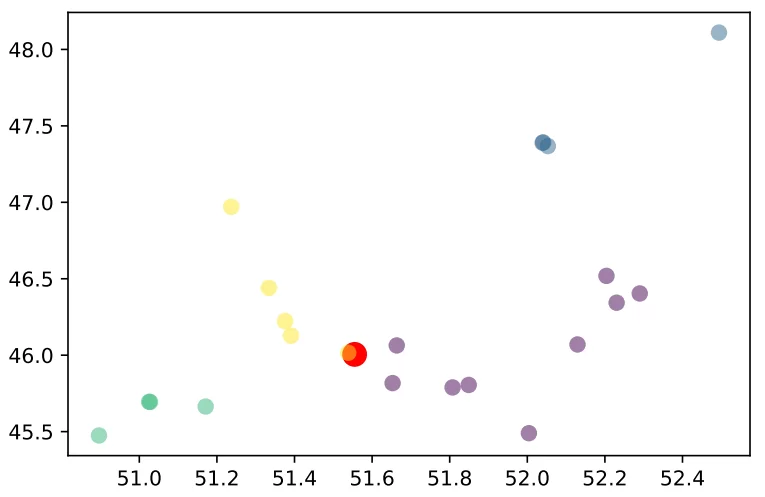
Теперь в этом графе можно увидеть, что точки разбились на группы. Принадлежность адреса к группе на изображении определяется цветом.
Для того чтобы узнать к какой группе принадлежит точка, добавим столбец в DataFrame
groups = coords.copy()
groups['group'] = kmeans.labels_
Результат:
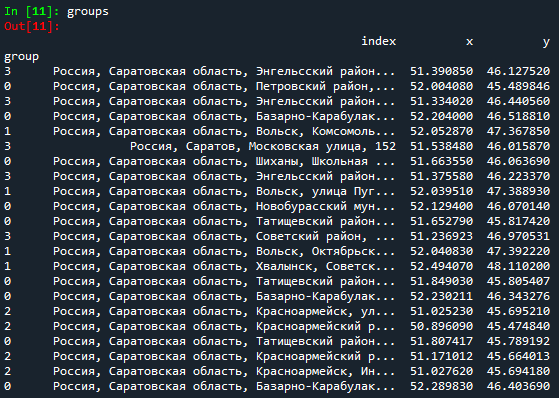
Столбец group отражает принадлежность каждого адреса к определенной группе.
Теперь для каждой группы точек, нужно определить оптимальный маршрут от точки подачи. Для этого нам нужно узнать расстояние между каждой точкой в одном маршруте. Для этого также используем DataFrame со столбцами: Группа — Адрес1 — Адрес2 — Расстояние
def graph_maker(a):
adrs = [routes['Адрес подачи'][0]] + list(a)
print(len(adrs))
result = []
for i in range(0, len(adrs)):
for j in range(i+1, len(adrs)):
temp = {'adr1': adrs[i], 'adr2': adrs[j], 'dist': lin_dist([coords['x'][adrs[i]],
coords['y'][adrs[i]],
coords['x'][adrs[j]],
coords['y'][adrs[j]]])}
result.append(temp)
result = pd.DataFrame(result)
temp = result.copy()
temp['adr1'] = result['adr2']
temp['adr2'] = result['adr1']
return result.append(temp).reset_index(drop=True)
Результат:
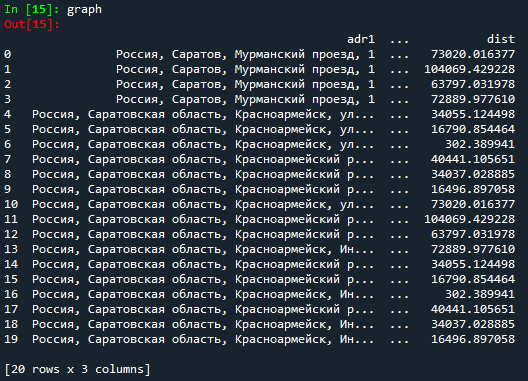
Для нахождения маршрута я также использовал метод ближайшего соседа:
def path_finder(a):
path = [routes['Адрес подачи'][0]]
length = a['adr1'].nunique()
a = a.set_index('adr1')
while len(path) < length:
b = a.loc[path[-1]]
closest_dist = 0
if type(b) == pd.core.series.Series:
path.append(b['adr2'])
else:
closest_dist = b['dist'].min()
next_point = b[b['dist'] == closest_dist]['adr2'].values[0]
path.append(next_point)
a = a.reset_index()
for i in a.index:
delete = a[a['adr2'] == path[-1]]
a = a.drop(delete.index)
a = a.set_index('adr1')
return path
На вход идет группа адресов, на выходе получаем последовательность, которая является оптимальным маршрутом.
Для нахождения ближайших соседей, достаточно линейного расстояния между точками, для того, чтобы скрипт выполнялся быстрее.
Функция, вычисляющая расстояние между двумя точками:
def lin_dist(coords):
R = 6373.0
x1 = radians(coords[0])
y1 = radians(coords[1])
x2 = radians(coords[2])
y2 = radians(coords[3])
dlon = y2-y1
dlat = x2-x1
a = sin(dlat/2)**2 + cos(x1)*cos(x2) * sin(dlon)**2
c = 2 * atan2(sqrt(a), sqrt(1-a))
# x = coords[0]-coords[2]
# y = coords[1]-coords[3]
return R * c * 1000
На выход получаем путь маршрута.
Результат одной из групп адресов:

Теперь необходимо узнать расстояние всего маршрута с учетом дорог, для этого используем функцию с запросом на сервер:
def route_dist(coords):
r = requests.get('http://localhost:8989/route', params={'point': coords, 'profile': 'car'})
if r.status_code == 200:
return(r.json()['paths'][0]['distance'])
else:
return(r.json()['message'])
Всё что остается — это сравнить сумму расстояний маршрутов до и после оптимизации:
distance += route_dist(path_coords)
fact_dist = routes[‘fact_dist’].sum()
print(fact_dist - distance)
Результат:
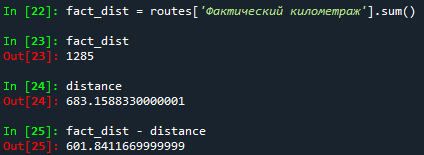
Как видим, в данной кейсе, можно увидеть, что общий километраж сократился на 600 километров, а также мы смогли сократить количество отправляемых машин с 6 до 4.
Вот так с помощью небольшого количества строк кода планируется оптимальный маршрут, решаются транспортные задачи и как следствие уменьшаются затраты организации.