/img/star (2).png.webp)






/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
В последнее время значимость графовых БД в IT-области стремительно увеличивается, а использование привычных реляционных БД для работы с высокоуровневыми иерархиями является крайне неэффективным, поскольку увеличение уровней связей, а, следовательно, и соединений, что приводит к снижению производительности. Основное преимущество графовых базы данных – их направленность на взаимосвязи между сущностями, что исключает необходимость использования внешних ключей. Это позволяет строить сложные системы, используя только абстракции ребер и вершин.
Рекурсивные табличные выражения, которые позволяют работать с иерархиями, по сути, являются обходным путем. Что же делать, если мы хотим работать в SQL Server с несколькими уровнями данных, но не хотим терять производительность? Ответ прост – использовать графовые таблицы. Они позволяют просто и эффективно обрабатывать сложные иерархии, при этом значительно сокращая объем кода, но важно помнить, что они подходят для работы с данными, которые имеют четко определенные связи.
Рассмотрим применение таких таблиц на примере структуры организации с иерархией сотрудников (данные вымышлены). Ниже представлено создание таблицы сотрудников EMPLOYEES с идентификатором TABNUM и столбцом HEAD, которая будет ссылаться на линейного руководителя сотрудника.
CREATE TABLE EMPLOYEES
(TABNUM INT NOT NULL,
NAME NVARCHAR(100),
EXPERIENCE INT,
POST NVARCHAR(40),
HEAD INT,
WAGES INT)
INSERT INTO EMPLOYEES VALUES
(766,'Amanda',5,'Аналитик',121,25000),
(423,'Steve',2,'DE',121,30000),
(121,'Alex',10,'Менеджер направления',876,50000),
(342,'Drake',4,'DE',121,30000),
(876,'Thomas',23,'Начальник отдела',789,70000),
(351,'Nick',15,'Аналитик',343,25000),
(343,'Kevin',17,'Менеджер направления',876,50000),
(123,'Josh',9,'DE',343,30000),
(789,'Bella',27,'Заместитель директора',126,70000),
(126,'Jiji',39,'Директор',NULL,100000)В результате получится следующая таблица:
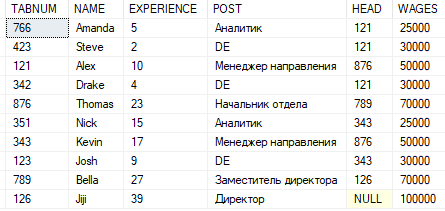
Анализируя таблицу можно увидеть связи подчинения в организации, например, что сотрудник 766 подчиняется сотруднику 121.
Теперь представим эти данные в формате графа. Для этого создадим таблицу узлов TableNode, сделать это крайне просто – к обычному выражению создания таблицы в конец необходимо добавить AS NODE.
CREATE TABLE TableNode (
ID int identity(1,1),
TABNUM NUMERIC(3) NOT NULL,
NAME NVARCHAR(100),
POST NVARCHAR(100),
HEAD NUMERIC(3),
WAGES INT)
AS NODE
Далее заполним нашу графовую таблицу данными из стандартной.
insert into TableNode(TABNUM,NAME,POST,HEAD,WAGES) select TABNUM,NAME,POST,HEAD,WAGES
from EMPLOYEESСодержимое таблицы TableNode:
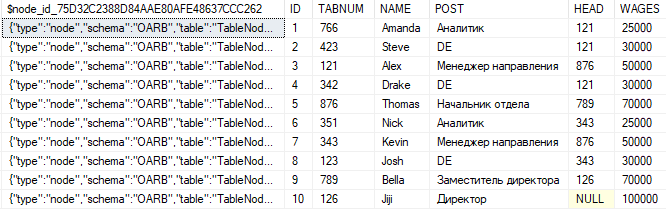
Таблица узлов содержит специальную колонку $node_id, которая хранит признак узла в формате JSON. Остальные столбцы содержат атрибуты данного узла.
Следующим шагом создадим ребра. Для этого аналогично предыдущему шагу после выражения добавим AS EDGE.
CREATE TABLE TableEdge(WEIGHT int) AS EDGEТаблица ребер содержит три столбца. Первый $edge_id – признак ребра в формате JSON, столбцы $from_id и $to_id определяют связь между узлами. Также стоит отметить, что ребра могут иметь дополнительные свойства, например, WEIGHT.
Далее определим связи подчинения между сотрудниками. Ниже представлен пример определения подобной связи.
insert into TableEdge VALUES ((SELECT $node_id from TableNode WHERE ID = 1), (SELECT $node_id from TableNode where id = 3), 5)В результате TableEdge будет иметь вид:

Отлично, мы создали графовую базу данных, но как же делать к ней запрос? – В этом нам поможет выражение MATCH.
Давайте напишем несколько запросов. Допустим, мы хотим узнать руководителя сотрудника Amanda.
SELECT n.tabnum,n.name,n.post,n.head, n1.tabnum,n1.name,n1.post,n1.head
FROM
TableNode n, TableNode n1, TableEdge e
WHERE
MATCH(n-(e)->n1)
and n.name = 'Amanda'

Следующий запрос увеличивает уровень на один.
SELECT n.tabnum,n.name,n.post,n.head, n1.tabnum,n1.name,n1.post,n1.head, n2.tabnum,n2.name,n2.post,n2.head
FROM
TableNode n, TableNode n1, TableEdge e, TableEdge e1, TableNode n2
WHERE
MATCH(n-(e)->n1-(e1)->n2)
and n.name = 'Amanda'

Ниже представлен запрос третьего уровня для сотрудников и их руководителей.
SELECT n.tabnum, n.name,n.head, n1.tabnum,n1.name,n1.head, n2.tabnum,n2.name,n2.head, n3.tabnum,n3.name,n3.head
FROM
TableNode n, TableNode n1, TableEdge e, TableEdge e1, TableNode n2, TableEdge e2, TableNode n3
WHERE
MATCH(n-(e)->n1-(e1)->n2-(e2)->n3)
and n.name = 'Amanda'

Следует отметить, что уровни иерархии можно увеличивать, их количество зависит от требований поставленной задачи. Теперь давайте изменим направление и узнаем всех начальников выбранного сотрудника.
SELECT n.tabnum, n.name,n.head, n1.tabnum,n1.name,n1.head, n2.tabnum,n2.name,n2.head, n3.tabnum,n3.name,n3.head
FROM
TableNode n, TableNode n1, TableEdge e, TableEdge e1, TableNode n2, TableEdge e2, TableNode n3
WHERE
MATCH(n<-(e)-n1<-(e1)-n2<-(e2)-n3)
and n3.name = 'Alex'

Таким образом, в данной статье мы узнали, что SQL Server содержит функционал для работы с графовыми таблицами, его использование упрощает запросы, увеличивая их производительность и сокращая объем. Однако перед началом работы следует помнить, что в SQL Server есть несколько ограничений, вот несколько наиболее важных из них: в SQL Server поддерживаются только однонаправленные связи, после создания таблиц невозможно обновить столбцы $from_id и $to_id через UPDATE, а также нет прямого способа преобразования обычных таблиц в графовые.