/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Когда бизнес только начинает свой путь. Процессы его свежи и понятны всем участникам, включая менеджмент. С течением времени бизнес начинает расти и как следствие – начинают расти процессы внутри него. Такая деформация, от эталонного состояния, просто необходима, чтобы соответствовать потребностям бизнеса. Как только процесс разрастается вертикально и горизонтально – им становится тяжелее управлять. Анализ бизнес-процессов всегда трудоемкая работа, обремененная такими факторами как:
- Плохо структурированные данные
- Непонимание реального процесса
- Отсутствие должных it компетенций для работы с данными
Зачастую, этим заняты глубокопогруженные в процесс аналитики, затрачивая на это много времени. Современные инструменты способны облегчить им работу и обеспечить надежность выводов. Одним из таких инструментов является набор алгоритмов Process Mining. Направление, имеющее некоторую популярность в кругах аналитиков, реализовано на различных платформах. В этой статье мы рассмотрим, как просто построить граф процесса на python, используя библиотеку pm4py.
Предполагается, что на Вашем устройстве уже установлено соответствующее виртуальное окружение. О том, как это сделать, можете прочитать тут.
В первую очередь необходимо из данных извлечь три составляющие:
- case:concept:name. Порядковый номер одного экземпляра Вашего процесса.
- time:timestamp. Время и дата события в формате timestamp.
- concept:name. Id события в рамках одного кейса.
Пример будет выглядеть примерно так:
# Импортируем пакет pandas
import pandas as pd
# Загружаем лог
pData = pd.read_csv('test_2012.csv', sep=';')
# Визуализируем первые пять строк файла
pData.head()Вам нужно перевести дату и время в формат timestamp что бы получилось примерно следующее.
| time:timestamp | EventID | case:concept:name | |
| 0 | 01.01.2000 13:00 | 1 | Клиент пришел |
| 1 | 01.01.2000 13:05 | 1 | Клиент подал заявку |
| 2 | 01.01.2000 13:06 | 2 | Клиент пришел |
| 3 | 01.01.2000 13:07 | 1 | Клиент получил решение |
| 4 | 01.01.2000 13:10 | 3 | Клиент пришел |
Далее необходимо преобразовать дату:
# Преобразование поля time:timestamp из строки в datetime
pData['time:timestamp'] = pd.to_datetime(pData['time:timestamp'])
# Преобразование поля time:timestamp в timestamp float
pData['time:timestamp'] = pData['time:timestamp'].astype(np.int64) // 10**9
# Преобразование поля time:timestamp в int
pData['time:timestamp'] = pData['time:timestamp'].astype(np.int)
pData.head() После преобразований таблица должна выглядеть следующим образом:
| time:timestamp | EventID | case:concept:name | |
| 0 | 946731600 | 1 | Клиент пришел |
| 1 | 946731900 | 1 | Клиент подал заявку |
| 2 | 946731960 | 2 | Клиент пришел |
| 3 | 946732020 | 1 | Клиент получил решение |
| 4 | 946732200 | 3 | Клиент пришел |
Следующим шагом необходимо отсортировать Ваши данные по времени. Это необходимо для корректной работы алгоритмов. Если в Ваши логи не отсортированы, сделать это можно так:
pData.sort_values('time:timestamp')Теперь данные готовы для подачи в пакет pm4py.
from pm4py.objects.conversion.log import factory as log_conv
log = log_conv.apply(pData)После того как лог сформирован – можно переходить к формированию графа процесса. Ниже будет приведен пример эвристического майнера. Полый список и описание алгоритмов можете посмотреть тут.
from pm4py.algo.discovery.heuristics import factory as heuristics_miner
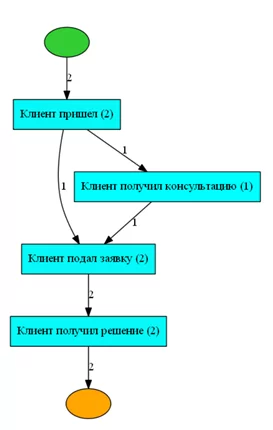
heu_net = heuristics_miner.apply_heu(log) После формирования графа, последнее что остается – визуализировать его. Для этого нам потребуется утилита GraphViz.
from pm4py.visualization.heuristics_net import factory as hn_vis_factory
gviz = hn_vis_factory.apply(heu_net)
hn_vis_factory.view(gviz)Вот и все. Граф готов.