/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Языковые модели все плотнее входят в нашу жизнь. Они используются в системах распознавания речи, системах обработки естественного языка, системах машинного перевода и многих других приложениях. В то же время их обучение происходит с использованием все большего количества данных.
Языковая модель — это вероятностная модель для предсказания следующего слова в последовательности с учетом истории слов в этой последовательности, например, последовательность слов в документе или речи.
Новые масштабные модели такие, как захватившая весь тематический информационный фон GPT-3, достаточно хороши даже для того чтобы позволить «воскресить» погибших близких, создав на основе прошлых переписок чат-бот, имитирующий стиль и манеру общения. Что уж говорить о генерации текста, ведь первые два абзаца этой статьи так же написаны языковой моделью, но не вышеупомянутой, а GPT-J-6B, о которой сегодня немного поговорим.
GPT-J-6B — это авторегрессионная модель генерации текста с 6 миллиардами параметров, обученная на The Pile (представляет собой объемный набор с разнообразными данными моделирования с открытым исходным кодом), среди данных которого имеется более узкоспециализированная информация, полученная из таких источников, как Stack Overflow, Github и других. В сравнении с набором GPT-3, в котором, в основном, общие данные, это позволяет не только получать часть текста для этой статьи (используется Colab Demo версия (рис. 1), которую вы можете найти и попробовать), но и генерировать вполне рабочий код (используется Web Demo версия (рис. 2), которую вы так же можете найти и опробовать).


Вы можете заметить, что это похоже на переобучение модели — она просто выдает запомненные ответы, однако, по моим небольшим тестам, я не нашёл ни одного точного совпадения в интернете по получаемым ответам модели, так что, как минимум, она их перерабатывает. Так же заметно, что примеры не всегда точны или же бывают избыточно сложными. Тем не менее, модель зачастую с задачей справляется.
Разбирая пример выше на таком файле:
txt = pd.read_table(r'/content/drive/MyDrive/Тест.txt', sep=' ', header=None)
txt
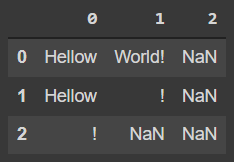
Видно, что код работает, но с некоторыми оговорками.
with open('/content/drive/MyDrive/Тест.txt', 'r') as f:
for line in f:
word=line.strip().split()
print (len(word))
print ('the total number of words in the file is:', len(word))

Вы можете найти и посмотреть больше примеров на GitHub.
Также, вы могли заметить, что я использую английский язык для подачи контекста. Это связано с тем, что данные, на которых обучалась модель, практически одноязычны: так она лучше справляется с задачами, хотя и русский язык поддерживается.
GPT-J-6B является продуктом команды EleutherAI, которая, в то время как OpenAI решили не открывать всем доступ к GPT-3, открыла исходный код, позволяя всем желающим изучить систему искусственного интеллекта общего назначения. Они сделали акцент на качестве данных, поэтому, несмотря на то что количество параметров GPT-J-6B меньше почти в 30 раз, чем у GPT-3 (175 миллиардов против 6 миллиардов), она обладает сопоставимым качеством, а генерация кода даже превосходит по вышеупомянутым причинам.