/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
В своей статье я хочу рассказать об облачном инструменте, который позволяет анализировать большие данные, применять к ним методы машинного обучения и экономить временные ресурсы на администрирование Базы Данных.
Довольно часто, в нашей работе возникает потребность в обработке и анализе большого массива внешних данных. С целью экономии времени на создание и развертывание полноценной Базы Данных, использование дополнительной среды разработки для построения моделей машинного обучения (например, PyCharm), я решил воспользоваться облачным инструментом для анализа данных от компании Google – BigQuery.
Аналитика данных включает в себя обработку данных и поиск инсайтов, которые можно использовать для принятия решения. Анализируемые данные хранятся в одном или нескольких форматах: текстовые файлы, электронные таблицы, базы данных и др.
Когда для работы с данными вы выбираете локальную Базу Данных (БД) возникает несколько вопросов:
- Выбор БД
- Загрузка и установка софта
- Настройка производительности
- Масштабирование при увеличении нагрузки
- Ограничение места для хранения данных
Все эти вопросы помогает решить Google BigQuery (GBQ) – быстрое, масштабируемое, экономичное хранилище данных, входящее в набор облачных услуг Google Cloud Platform (GCP). Также Google BigQuery дает возможность использовать методы машинного обучения непосредственно в консоли.
Работать с GBQ можно с помощью встроенного графического интерфейса, либо на любом языке программирования, который работает с REST API. Для запросов к БД используется SQL диалект (standard, legacy). Начать использование GBQ вы можете с использования публичных датасетов или загрузить собственные данные.
В данной статье в качестве примера я использовал публичный датасет Google Analytics 360. В нем содержатся данные о поведении пользователей Google Merchandise Store (просмотры страниц, транзакции и т.д.). Подробную информацию о наборе данных можно посмотреть здесь. Отправим запрос к таблице ga_sessions_, чтобы посмотреть сводную информацию по кол-ву пользователей, визитов, просмотров страниц, транзакций и доходу:
SELECT
COUNT(DISTINCT fullVisitorId) AS users,
SUM(totals.visits) AS visits,
SUM(totals.pageviews) AS pageviews,
SUM(totals.transactions) AS transactions,
SUM(totals.transactionRevenue)/1000000 AS revenue
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20170101'
AND '20170120'
AND totals.totalTransactionRevenue IS NOT NULL
Запрос вернет таблицу:
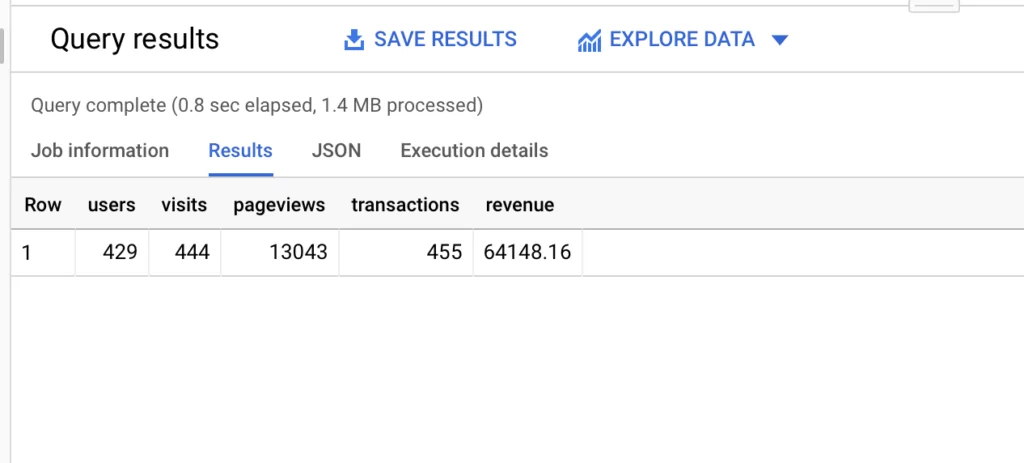
Теперь мы знаем, что в период с 01.01.2017 по 20.01.2017 сайт Google Merchandise Store посетили 429 пользователей. Они совершили 444 визита, 13043 просмотра страниц, оформили 455 заказов и принесли доход 64148,16 у.е.
Инструмент прост в использовании и не требует навыков Data Engineer. Достаточно владеть навыками Аналитика Данных, SQL.
Далее рассмотрим BigQuery ML – инструмент для создания моделей машинного обучения с использованием standard SQL.
BigQuery ML поддерживает следующие модели:
- Линейная Регрессия
- Бинарная Логистическая Регрессия
- Мультиклассовая Логистическая Регрессия
- Метод k-средних
- Boosted Tree
- Matrix Factorization
- Auto ML
- DNN
- Импорт моделей TensorFlow
Синтаксис запроса для создания модели выглядит следующим образом:
{CREATE MODEL | CREATE MODEL IF NOT EXISTS | CREATE OR REPLACE MODEL}
model_name
[OPTIONS(model_option_list)]
[AS query_statement]
- model_name – имя вашей модели
- model_type может принимать значения — ‘LINEAR_REG’, ‘LOGISTIC_REG’, ‘KMEANS’, ‘BOOSTED_TREE_REGRESSOR’, ‘BOOSTED_TREE_CLASSIFIER’, ‘DNN_CLASSIFIER’, ‘DNN_REGRESSOR’
- model_options_list дополнительные параметры
- query_statement – запрос к таблице с исходными данными.
Полный список доступен здесь.
Рассмотрим пример с прогнозированием покупки на основе данных о поведении пользователей. В качестве модели будем использовать Логистическую Регрессию.
Для начала нужно создать и обучить модель:
CREATE MODEL `automated-rune-302513.bq_nta.test_model`
OPTIONS(model_type='logistic_reg') AS
SELECT
IF(totals.transactions IS NULL, 0, 1) AS label,
IFNULL(device.operatingSystem, "") AS os,
device.isMobile AS is_mobile,
IFNULL(geoNetwork.country, "") AS country,
IFNULL(totals.pageviews, 0) AS pageviews
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20160801' AND '20170630'
В запросе SELECT есть столбец label – класс, который мы хотим предсказать.
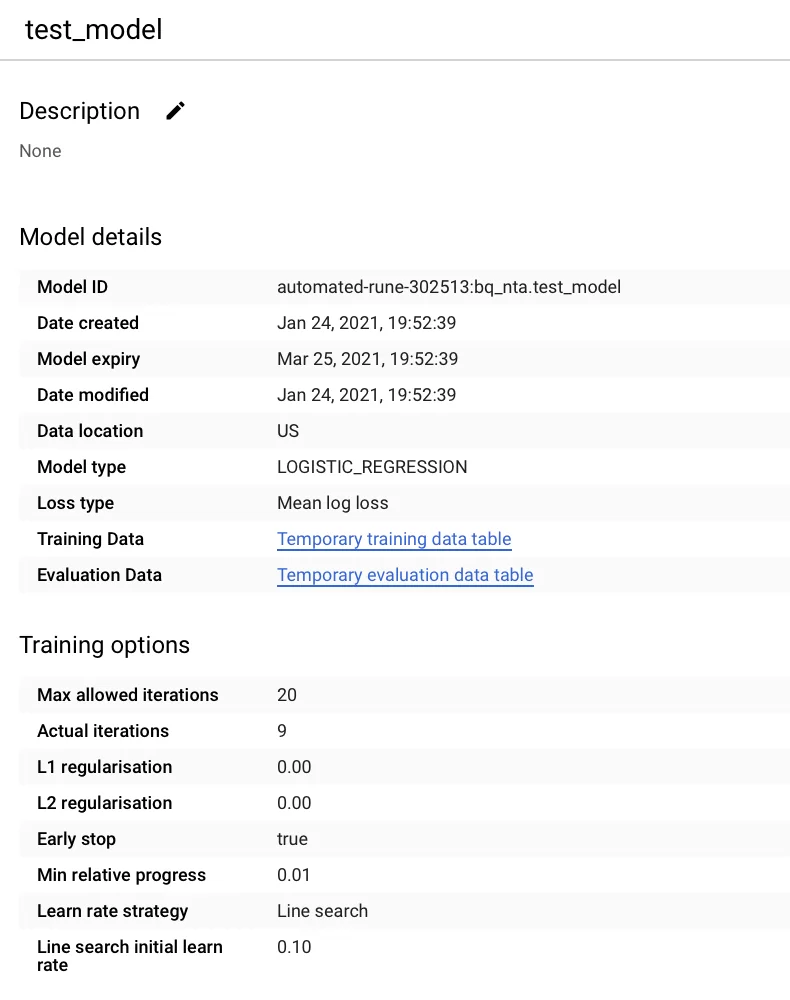
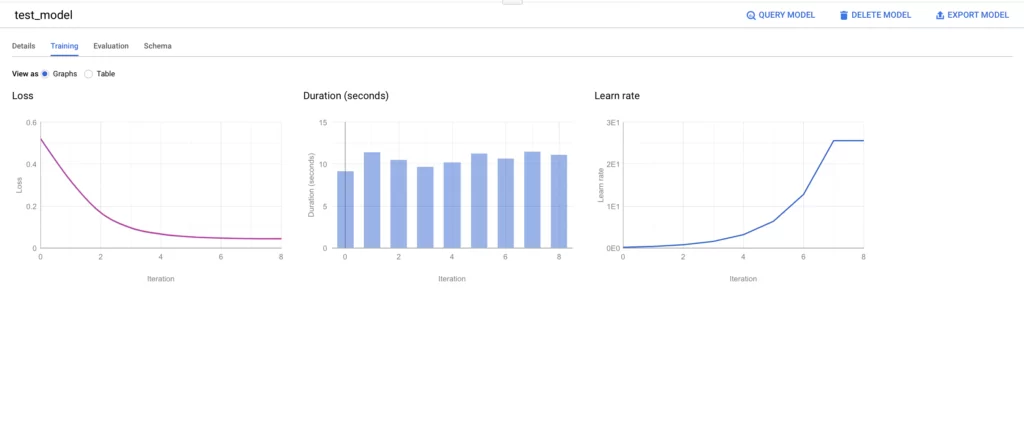
После выполнения запроса модель доступна в нашем исходном датасете. Мы можем посмотреть дополнительные параметры модели (скорость обучения, длительность и так далее). Также можно посмотреть на тренировочную и тестовые выборки.
Когда наша модель обучена, мы можем c помощью процедуры ML.PREDICT сделать прогноз следующей покупки:
SELECT
*
FROM
ML.PREDICT(MODEL `automated-rune-302513.bq_nta.test_model`, (
SELECT
IFNULL(device.operatingSystem, "") AS os,
device.isMobile AS is_mobile,
IFNULL(totals.pageviews, 0) AS pageviews,
IFNULL(geoNetwork.country, "") AS country
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20170701' AND '20170730'))
ORDER BY predicted_label DESC
В итоге мы получим финальную таблицу с прогнозируемым значением выбранного признака:
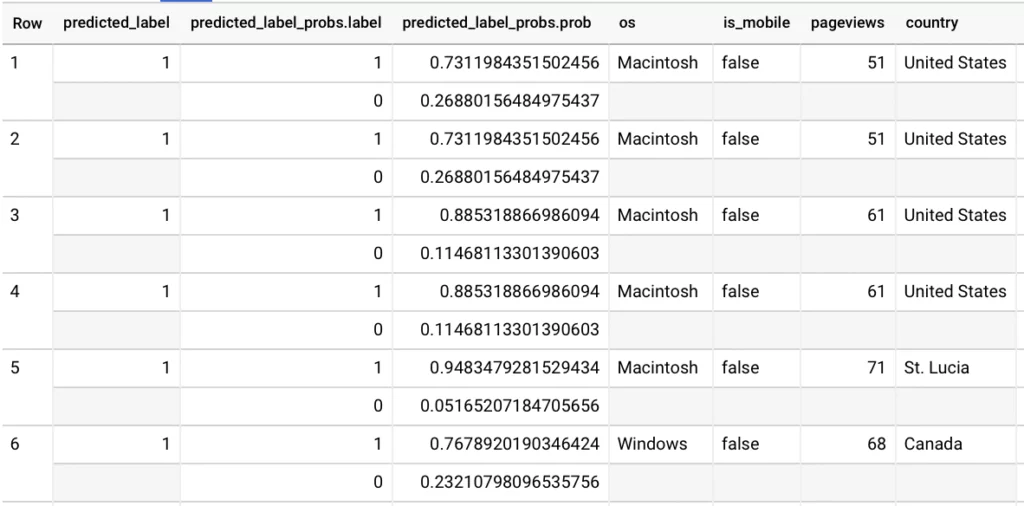
Вот так, Google BigQuery позволяет Аналитику Данных сфокусироваться на обработке данных и сократить время на поиск решения. Предлагаю использовать данный инструмент в ситуациях, когда вы ограничены временными ресурсами на выполнение поставленной задачи и, если в вашей команде отсутствует Data Engineer.