/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 8 мин.
Задача классификации текста уже давно является устоявшейся во многих компаниях. Она используется для определения настроения клиентов, разделения документов на заранее известные темы, детекции фейковых новостей и т.д. Сегодня я представлю state of the art подход для решения задачи бинарной классификации, а именно детекция сообщений, в которой присутствует жалоба на сотрудника.
А также сравню по точности два подхода: Fine-Tune Bert и получение предобученных эмбеддингов и их классификация с использованием полносвязной нейронной сети.
Подходы для классификации текста
Для работы с текстом существует множество подходов, которые имеют как плюсы, так и минусы. Есть простые решения, которые дают точность ниже, чем более сложные подходы, но могут быть использованы в случае, когда требуется сократить time2market до минимума. Есть более тяжелые подходы, как, например, тот же Fine-Tune Bert, но он выдает максимально возможную точность при конкретной природе данных, на которых обучался.
- Logistic Regression+VECTORIZER
Это один из самых простых в реализации подходов. Алгоритм Logistic Regression и подобные ему на вход принимают числовые значения. Поэтому прежде чем обучать модель, текст нужно векторизовать. Самый простой способ это сделать — использовать мешок слов.
Для это можно использовать Count Vectorizer или его более совершенную версию, учитывающую частоту вхождения слова TF-IDF Vectorizer.
Но для использования такого подхода нужно будет почистить текст, а именно удалить стоп-слова, спецсимволы и эмоджи, а также привести текст к лемматизированному виду.
Плюсы: не затратно по ресурсам и дает довольно неплохой бейзлайн, с учетом того, что это один из самых простых способов.
Минусы: требуется правильная предобработка текста и точность может сильно уступать более мощным инструментам, по причине того, что такой способ не учитывает семантику текста и порядок слов в предложении. Также такое представление текста получается слишком разреженным.
- Word2vec и Fasttext
Word2vec – это способ построения сжатого пространства векторов слов, который принимает на вход корпус текста и сопоставляет каждому слову вектор. Векторное представление основывается на контекстной близости.
Fasttext – улучшение Word2vec, использующее N-граммы символов, которая помогает в случае незнакомых для моделей слов, что в свою очередь положительно влияет на качество работы модели.
Плюсы: есть куча предобученных моделей и довольно удобный инструмент — Gensim для работы с ними.
Минусы: все еще не учитывает всю семантику предложения и данные модели назначают каждому слову один вектор, независимо от контекста.
- Получение эмбедингов из предобученного Bert и их последующая классификация нейронными сетями
Bert – это нейронная сеть, показавшая результаты с большим отрывом на целом ряде задач обработки текста, так как учитывает порядок слов в предложениях и семантику текстов.
Здесь также есть куча предобученных моделей (скажем на huggineface или DeepPavlov), которые довольно легко можно использовать для получения эмбеддингов. Далее полученные вектора можно разделить, например, линейной моделью, но это будет не очень хорошо, так как вектора текста, полученные таким образом, не линейно зависимы. Данный подход будет определенно лучше, чем Logistic Regression+VECTORIZER, но все же хуже, чем если мы разделим их с помощью нескольких полно связных слоев нейронной сети, которая будет учитывать нелинейные зависимости. Более подробно про этот подход можно посмотреть здесь (ссылка).
Плюсы: много предобученных моделей Bert и простота получения эмбедингов. Нейронная сеть при разделении векторов, сможет уловить нелинейные зависимости в данных, что опять же положительно повлияет на точность.
Минусы: данный подход никак не учитывает природу исходных текстовых данных, которые мы хотим классифицировать. Например, Bert учился на множестве wiki статей, а мне нужно классифицировать, например, является ли текст, написанный неким пользователем, жалобой на сотрудника нашей организации или нет. Wiki статьи написаны научным или литературным, хорошо структурированным языком, когда сообщения (в моем случае жалобы) пользователей имеют определенную семантику и могут быть не так хорошо структурированы.
- Fine-Tune Bert
У каждого предобученного Bert есть свои веса, которые были получены путем его обучения на большом корпусе текстов. Можно дообучить Bert на своих текстовых данных, тем самым изменяя веса модели Bert и более хорошо учитывать семантику исходных данных.
Плюсы: таким методом можно получить точность классификации намного больше, чем у выше описанных методов.
Минусы: операция дообучения Bert довольно затратная по времени и вычислительным ресурсам.
Тонкая настройка rubert-base-cased-sentence
В этом разделе я представлю код для дообучения Bert и сравнения двух подходов: получение предобученных эмбеддингов и их классификация с использованием полносвязной нейронной сети или Fine-Tune Bert.
Для решения задачи детекции сообщений на предмет наличия жалобы на сотрудника в качестве данных я буду использовать данные из предыдущей публикации (ссылка), но датасеты train и val будут объедены в один, для увеличения объема обучающей выборки.
Для начала импортирую нужные библиотеки:
import pandas as pd
import numpy as np
import random
import torch
import transformers
import torch.nn as nn
from transformers import AutoModel, BertTokenizer, BertForSequenceClassification
from transformers import TrainingArguments, Trainer
from datasets import load_metric, Dataset
from sklearn.metrics import classification_report, f1_score
Загрузка данных для дообучения модели и тестовых данных для проверки работы будущей модели:
train_df = pd.read_excel('tmp/train.xlsx', engine = 'openpyxl', index_col = 0)
test_df = pd.read_excel('tmp/test.xlsx', engine = 'openpyxl', index_col = 0)
train_text = train_df['text'].astype('str')
train_labels = train_df['target']
test_text = test_df['text'].astype('str')
test_labels = test_df['target']
Посмотрим на данные:

Задание всех seed:
def seed_all(seed_value):
random.seed(seed_value)
np.random.seed(seed_value)
torch.manual_seed(seed_value)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed_value)
torch.cuda.manual_seed_all(seed_value)
torch.backends.cudnn.benchmark = True
torch.backends.cudnn.deterministic = False
seed_all(42)Далее происходит загрузка предобученной модели, а также указание, на какое количество классов делятся данные. Для дообучения буду использовать GPU:
model = BertForSequenceClassification.from_pretrained('rubert_base_cased_sentence/', num_labels=2).to("cuda")
tokenizer = BertTokenizer.from_pretrained('rubert_base_cased_sentence/')Данная модель принимает предложения длиной, не больше 512 токенов, поэтому сначала проверю, какая максимальная длина в train и test:
seq_len_train = [len(str(i).split()) for i in train_df['text']]
seq_len_test = [len(str(i).split()) for i in test_df['text']]
max_seq_len = max(max(seq_len_test), max(seq_len_train))
max_seq_len
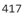
Модели Bert принимают на вход предложения одной длины, поэтому для train и test буду брать предложения длиной 417, а не 512 как по умолчанию, для того, чтобы уменьшить разреженность данных:
tokens_train = tokenizer.batch_encode_plus(
train_text.values,
max_length = max_seq_len,
padding = 'max_length',
truncation = True
)
tokens_test = tokenizer.batch_encode_plus(
test_text.values,
max_length = max_seq_len,
padding = 'max_length',
truncation = True
)Данный код оборачивает токенизированные текстовые данные в torch Dataset:
class Data(torch.utils.data.Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {k: torch.tensor(v[idx]) for k, v in self.encodings.items()}
item["labels"] = torch.tensor([self.labels[idx]])
return item
def __len__(self):
return len(self.labels)
train_dataset = Data(tokens_train, train_labels)
test_dataset = Data(tokens_test, test_labels)Напишу функцию для расчета метрики. Использую метрику F1, так как классы не сбалансированы:
from sklearn.metrics import f1_score
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
f1 = f1_score(labels, preds)
return {'F1': f1}Ниже указаны все параметры, которые будут использоваться для обучения:
training_args = TrainingArguments(
output_dir = './results', #Выходной каталог
num_train_epochs = 3, #Кол-во эпох для обучения
per_device_train_batch_size = 8, #Размер пакета для каждого устройства во время обучения
per_device_eval_batch_size = 8, #Размер пакета для каждого устройства во время валидации
weight_decay =0.01, #Понижение весов
logging_dir = './logs', #Каталог для хранения журналов
load_best_model_at_end = True, #Загружать ли лучшую модель после обучения
learning_rate = 1e-5, #Скорость обучения
evaluation_strategy ='epoch', #Валидация после каждой эпохи (можно сделать после конкретного кол-ва шагов)
logging_strategy = 'epoch', #Логирование после каждой эпохи
save_strategy = 'epoch', #Сохранение после каждой эпохи
save_total_limit = 1,
seed=21)Передача в trainer предообученную модель, tokenizer, данные для обучения, данные для валидации и способ расчета метрики:
trainer = Trainer(model=model,
tokenizer = tokenizer,
args = training_args,
train_dataset = train_dataset,
eval_dataset = train_dataset,
compute_metrics = compute_metrics)Запуск обучения модели:
trainer.train()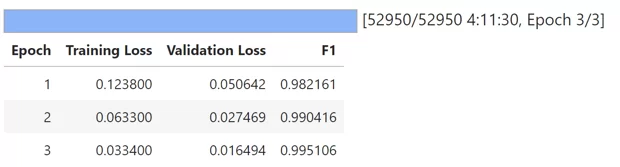
Сохранение обученной модели:
model_path = "fine-tune-bert"
model.save_pretrained(model_path)
tokenizer.save_pretrained(model_path)Написание функции для получения предикта:
def get_prediction():
test_pred = trainer.predict(test_dataset)
labels = np.argmax(test_pred.predictions, axis = -1)
return labels
pred = get_prediction()Проверка полученного результата:

Вывод всей необходимой информации для оценки качества модели:
print(classification_report(test_labels, pred))
print(f1_score(test_labels, pred))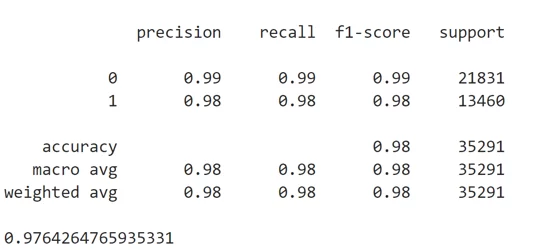
По итогу получаю F1 = 0.976!!!, это довольно крутой результат, который можно улучшить.
Предложения по улучшению:
- Более подробно изучить гиперпараметры модели и попробовать поиграться с ними, скажем указав lr не как константу, а сделать learning rate затухающим, и т.д.
- Произвести кроссвалидационный стекинг данной модели. Это сильно увеличит время на дообучения каждой модели, но таким образом можно уменьшить дисперсию предсказания и поднять точность на 0.5-1%.
Вывод: данный подход увеличил метрику F1 почти на 10% относительно подхода, описанного в статье. Fine-Tune Bert позволяет с очень высокой точностью классифицировать данные той же природы, что и данные, на которых производился Fine-Tune, его также можно производить не только для бинарной классификации, но и для мультиклассовой. Стоит также отметить, что при уменьшении количества обучаемых данных, метрика ожидаемо упадет, но все равно будет лучше, чем при других подходах, так как они не учитывают природу конкретных данных.